 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Aligned Convolutional Neural Network for Skeleton-based Action Recognition and Segmentation
Nov 12, 2019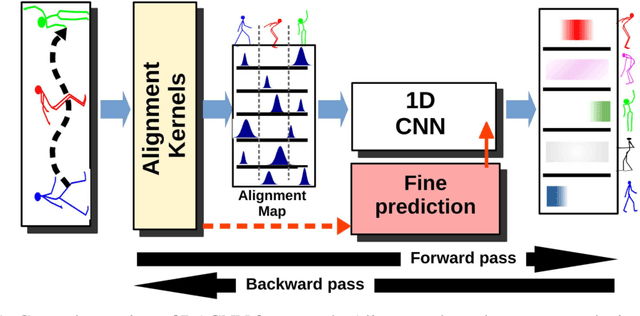

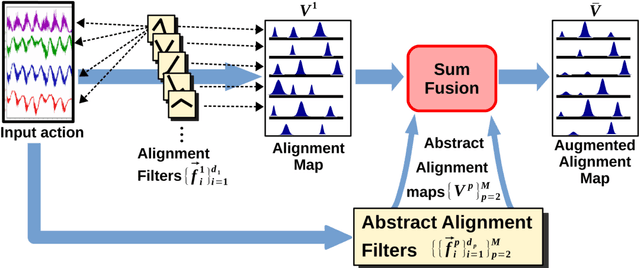

Convolutional neural networks (CNNs) are deep learning frameworks which are well-known for their notable performance in classification tasks. Hence, many skeleton-based action recognition and segmentation (SBARS) algorithms benefit from them in their designs. However, a shortcoming of such applications is the general lack of spatial relationships between the input features in such data types. Besides, non-uniform temporal scalings is a common issue in skeleton-based data streams which leads to having different input sizes even within one specific action category. In this work, we propose a novel deep-aligned convolutional neural network (DACNN) to tackle the above challenges for the particular problem of SBARS. Our network is designed by introducing a new type of filters in the context of CNNs which are trained based on their alignments to the local subsequences in the inputs. These filters result in efficient predictions as well as learning interpretable patterns in the data. We empirically evaluate our framework on real-world benchmarks showing that the proposed DACNN algorithm obtains a competitive performance compared to the state-of-the-art while benefiting from a less complicated yet more interpretable model.
Interpretable Multiple-Kernel Prototype Learning for Discriminative Representation and Feature Selection
Nov 10, 2019
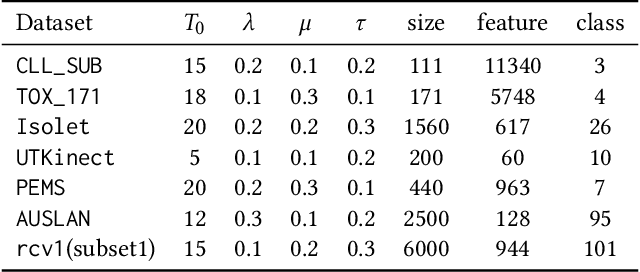

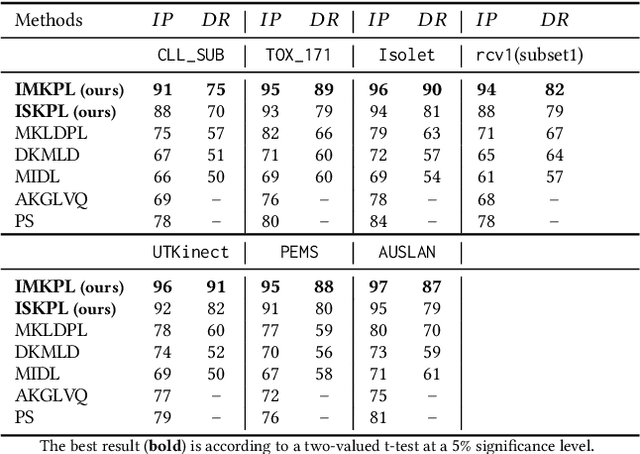
Prototype-based methods are of the particular interest for domain specialists and practitioners as they summarize a dataset by a small set of representatives. Therefore, in a classification setting, interpretability of the prototypes is as significant as the prediction accuracy of the algorithm. Nevertheless, the state-of-the-art methods make inefficient trade-offs between these concerns by sacrificing one in favor of the other, especially if the given data has a kernel-based representation. In this paper, we propose a novel interpretable multiple-kernel prototype learning (IMKPL) to construct highly interpretable prototypes in the feature space, which are also efficient for the discriminative representation of the data. Our method focuses on the local discrimination of the classes in the feature space and shaping the prototypes based on condensed class-homogeneous neighborhoods of data. Besides, IMKPL learns a combined embedding in the feature space in which the above objectives are better fulfilled. When the base kernels coincide with the data dimensions, this embedding results in a discriminative features selection. We evaluate IMKPL on several benchmarks from different domains which demonstrate its superiority to the related state-of-the-art methods regarding both interpretability and discriminative representation.
Interpretable Discriminative Dimensionality Reduction and Feature Selection on the Manifold
Sep 19, 2019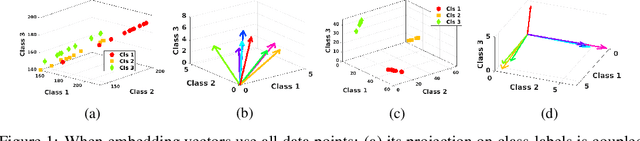



Dimensionality reduction (DR) on the manifold includes effective methods which project the data from an implicit relational space onto a vectorial space. Regardless of the achievements in this area, these algorithms suffer from the lack of interpretation of the projection dimensions. Therefore, it is often difficult to explain the physical meaning behind the embedding dimensions. In this research, we propose the interpretable kernel DR algorithm (I-KDR) as a new algorithm which maps the data from the feature space to a lower dimensional space where the classes are more condensed with less overlapping. Besides, the algorithm creates the dimensions upon local contributions of the data samples, which makes it easier to interpret them by class labels. Additionally, we efficiently fuse the DR with feature selection task to select the most relevant features of the original space to the discriminative objective. Based on the empirical evidence, I-KDR provides better interpretations for embedding dimensions as well as higher discriminative performance in the embedded space compared to the state-of-the-art and popular DR algorithms.
Large-Margin Multiple Kernel Learning for Discriminative Features Selection and Representation Learning
Mar 12, 2019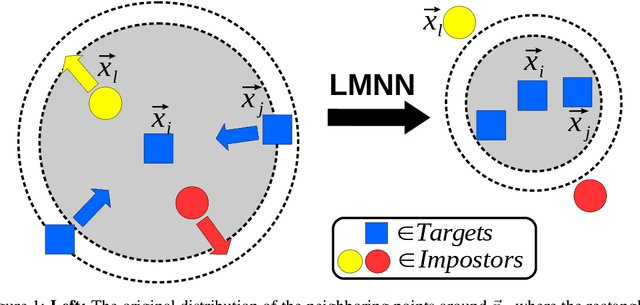
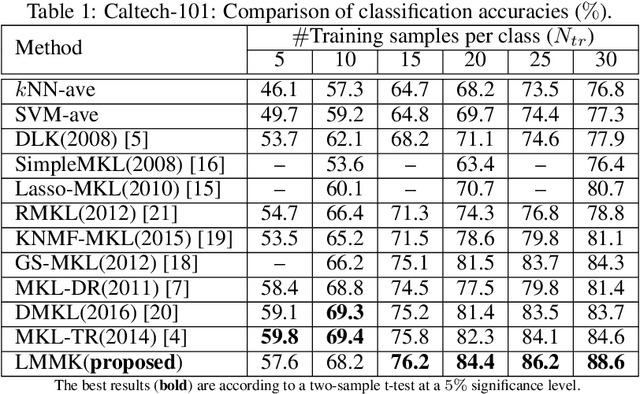
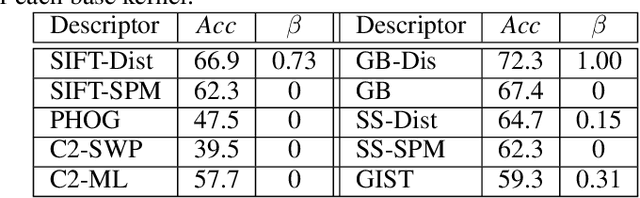
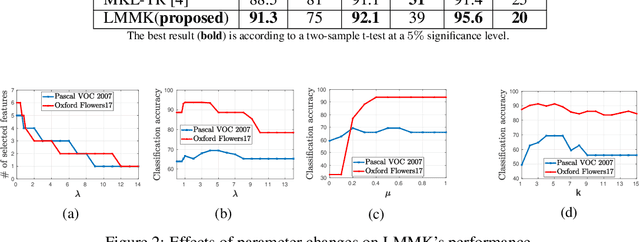
Multiple kernel learning (MKL) algorithms combine different base kernels to obtain a more efficient representation in the feature space. Focusing on discriminative tasks, MKL has been used successfully for feature selection and finding the significant modalities of the data. In such applications, each base kernel represents one dimension of the data or is derived from one specific descriptor. Therefore, MKL finds an optimal weighting scheme for the given kernels to increase the classification accuracy. Nevertheless, the majority of the works in this area focus on only binary classification problems or aim for linear separation of the classes in the kernel space, which are not realistic assumptions for many real-world problems. In this paper, we propose a novel multi-class MKL framework which improves the state-of-the-art by enhancing the local separation of the classes in the feature space. Besides, by using a sparsity term, our large-margin multiple kernel algorithm (LMMK) performs discriminative feature selection by aiming to employ a small subset of the base kernels. Based on our empirical evaluations on different real-world datasets, LMMK provides a competitive classification accuracy compared with the state-of-the-art algorithms in MKL. Additionally, it learns a sparse set of non-zero kernel weights which leads to a more interpretable feature selection and representation learning.
Non-Negative Local Sparse Coding for Subspace Clustering
Mar 12, 2019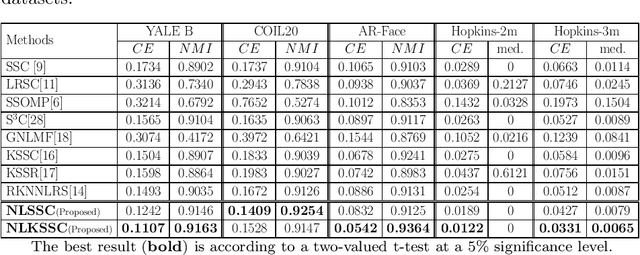

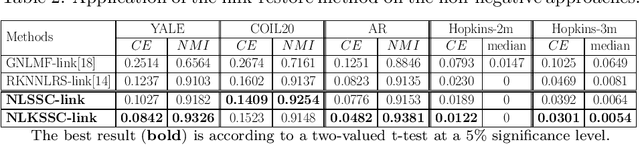

Subspace sparse coding (SSC) algorithms have proven to be beneficial to clustering problems. They provide an alternative data representation in which the underlying structure of the clusters can be better captured. However, most of the research in this area is mainly focused on enhancing the sparse coding part of the problem. In contrast, we introduce a novel objective term in our proposed SSC framework which focuses on the separability of data points in the coding space. We also provide mathematical insights into how this local-separability term improves the clustering result of the SSC framework. Our proposed non-linear local SSC algorithm (NLSSC) also benefits from the efficient choice of its sparsity terms and constraints. The NLSSC algorithm is also formulated in the kernel-based framework (NLKSSC) which can represent the nonlinear structure of data. In addition, we address the possibility of having redundancies in sparse coding results and its negative effect on graph-based clustering problems. We introduce the link-restore post-processing step to improve the representation graph of non-negative SSC algorithms such as ours. Empirical evaluations on well-known clustering benchmarks show that our proposed NLSSC framework results in better clusterings compared to the state-of-the-art baselines and demonstrate the effectiveness of the link-restore post-processing in improving the clustering accuracy via correcting the broken links of the representation graph.
Multiple-Kernel Dictionary Learning for Reconstruction and Clustering of Unseen Multivariate Time-series
Mar 12, 2019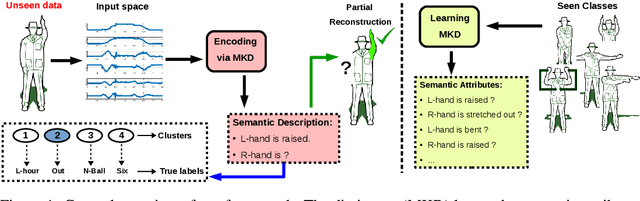
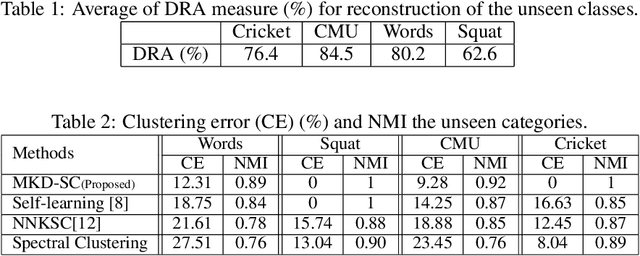

There exist many approaches for description and recognition of unseen classes in datasets. Nevertheless, it becomes a challenging problem when we deal with multivariate time-series (MTS) (e.g., motion data), where we cannot apply the vectorial algorithms directly to the inputs. In this work, we propose a novel multiple-kernel dictionary learning (MKD) which learns semantic attributes based on specific combinations of MTS dimensions in the feature space. Hence, MKD can fully/partially reconstructs the unseen classes based on the training data (seen classes). Furthermore, we obtain sparse encodings for unseen classes based on the learned MKD attributes, and upon which we propose a simple but effective incremental clustering algorithm to categorize the unseen MTS classes in an unsupervised way. According to the empirical evaluation of our MKD framework on real benchmarks, it provides an interpretable reconstruction of unseen MTS data as well as a high performance regarding their online clustering.
Confident Kernel Sparse Coding and Dictionary Learning
Mar 12, 2019
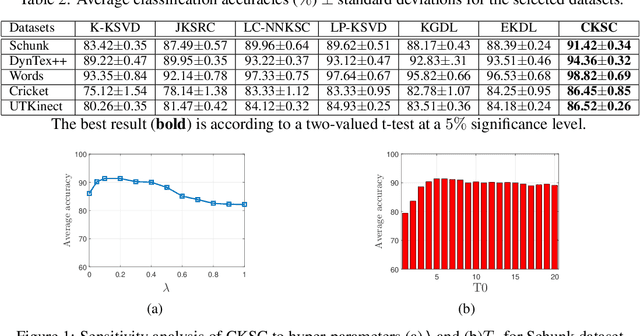
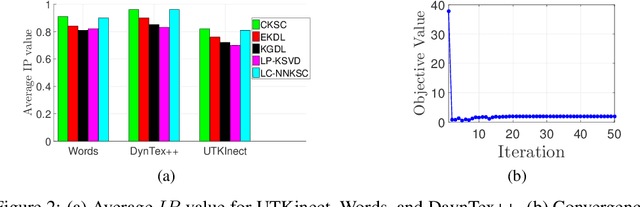
In recent years, kernel-based sparse coding (K-SRC) has received particular attention due to its efficient representation of nonlinear data structures in the feature space. Nevertheless, the existing K-SRC methods suffer from the lack of consistency between their training and test optimization frameworks. In this work, we propose a novel confident K-SRC and dictionary learning algorithm (CKSC) which focuses on the discriminative reconstruction of the data based on its representation in the kernel space. CKSC focuses on reconstructing each data sample via weighted contributions which are confident in its corresponding class of data. We employ novel discriminative terms to apply this scheme to both training and test frameworks in our algorithm. This specific design increases the consistency of these optimization frameworks and improves the discriminative performance in the recall phase. In addition, CKSC directly employs the supervised information in its dictionary learning framework to enhance the discriminative structure of the dictionary. For empirical evaluations, we implement our CKSC algorithm on multivariate time-series benchmarks such as DynTex++ and UTKinect. Our claims regarding the superior performance of the proposed algorithm are justified throughout comparing its classification results to the state-of-the-art K-SRC algorithms.
Non-Negative Kernel Sparse Coding for the Classification of Motion Data
Mar 12, 2019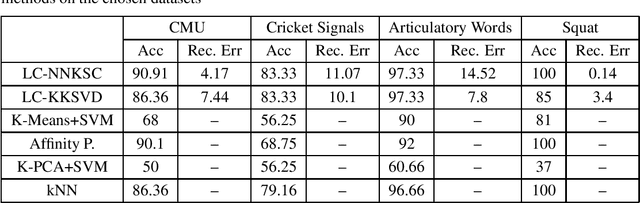
We are interested in the decomposition of motion data into a sparse linear combination of base functions which enable efficient data processing. We combine two prominent frameworks: dynamic time warping (DTW), which offers particularly successful pairwise motion data comparison, and sparse coding (SC), which enables an automatic decomposition of vectorial data into a sparse linear combination of base vectors. We enhance SC as follows: an efficient kernelization which extends its application domain to general similarity data such as offered by DTW, and its restriction to non-negative linear representations of signals and base vectors in order to guarantee a meaningful dictionary. Empirical evaluations on motion capture benchmarks show the effectiveness of our framework regarding interpretation and discrimination concerns.
Feasibility Based Large Margin Nearest Neighbor Metric Learning
May 02, 2018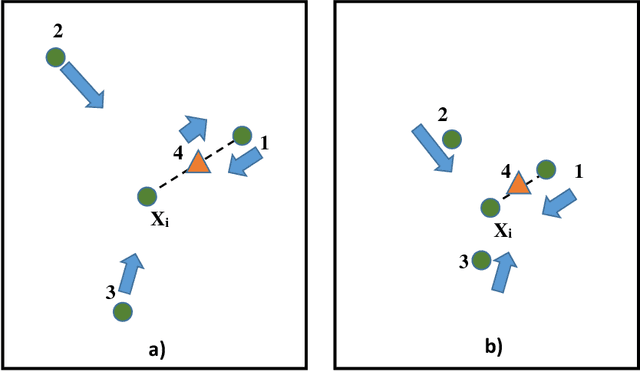
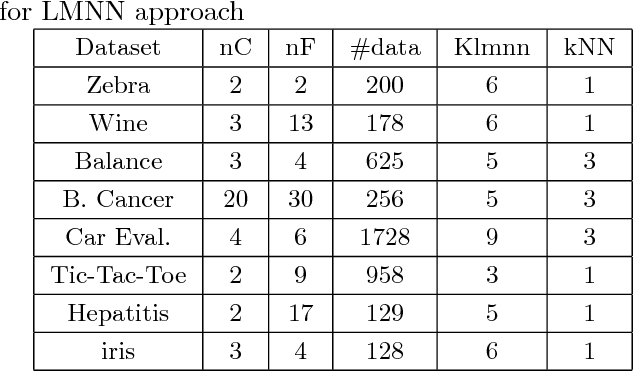

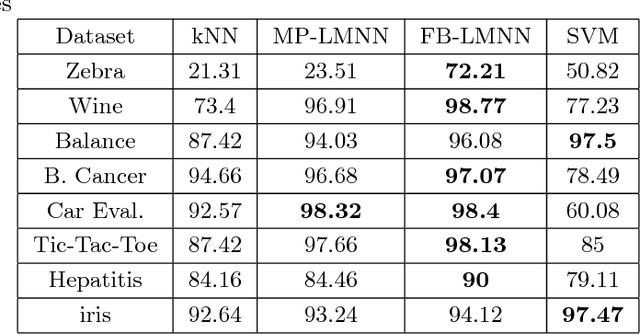
Large margin nearest neighbor (LMNN) is a metric learner which optimizes the performance of the popular $k$NN classifier. However, its resulting metric relies on pre-selected target neighbors. In this paper, we address the feasibility of LMNN's optimization constraints regarding these target points, and introduce a mathematical measure to evaluate the size of the feasible region of the optimization problem. We enhance the optimization framework of LMNN by a weighting scheme which prefers data triplets which yield a larger feasible region. This increases the chances to obtain a good metric as the solution of LMNN's problem. We evaluate the performance of the resulting feasibility-based LMNN algorithm using synthetic and real datasets. The empirical results show an improved accuracy for different types of datasets in comparison to regular LMNN.
* This is the preprint of the conference paper published in ESANN2018
Efficient Metric Learning for the Analysis of Motion Data
Oct 18, 2016



We investigate metric learning in the context of dynamic time warping (DTW), the by far most popular dissimilarity measure used for the comparison and analysis of motion capture data. While metric learning enables a problem-adapted representation of data, the majority of meth- ods has been proposed for vectorial data only. In this contribution, we extend the popular principle offered by the large margin nearest neighbours learner (LMNN) to DTW by treating the resulting component-wise dissimilarity values as features. We demonstrate, that this principle greatly enhances the classification accuracy in several benchmarks. Further, we show that recent auxiliary concepts such as metric regularisation can be transferred from the vectorial case to component-wise DTW in a similar way. We illustrate, that metric regularisation constitutes a crucial prerequisite for the interpretation of the resulting relevance profiles.