 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfident Kernel Sparse Coding and Dictionary Learning
Paper and Code

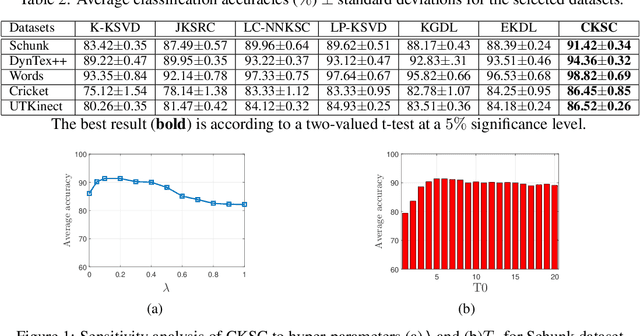
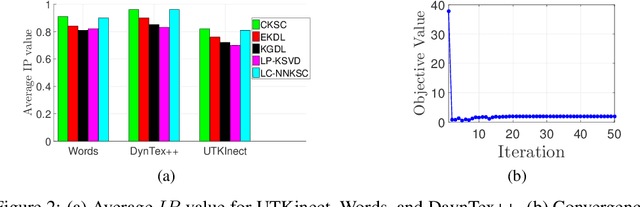
In recent years, kernel-based sparse coding (K-SRC) has received particular attention due to its efficient representation of nonlinear data structures in the feature space. Nevertheless, the existing K-SRC methods suffer from the lack of consistency between their training and test optimization frameworks. In this work, we propose a novel confident K-SRC and dictionary learning algorithm (CKSC) which focuses on the discriminative reconstruction of the data based on its representation in the kernel space. CKSC focuses on reconstructing each data sample via weighted contributions which are confident in its corresponding class of data. We employ novel discriminative terms to apply this scheme to both training and test frameworks in our algorithm. This specific design increases the consistency of these optimization frameworks and improves the discriminative performance in the recall phase. In addition, CKSC directly employs the supervised information in its dictionary learning framework to enhance the discriminative structure of the dictionary. For empirical evaluations, we implement our CKSC algorithm on multivariate time-series benchmarks such as DynTex++ and UTKinect. Our claims regarding the superior performance of the proposed algorithm are justified throughout comparing its classification results to the state-of-the-art K-SRC algorithms.