 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of brain states, transitions, and communities using functional MRI
Jan 26, 2021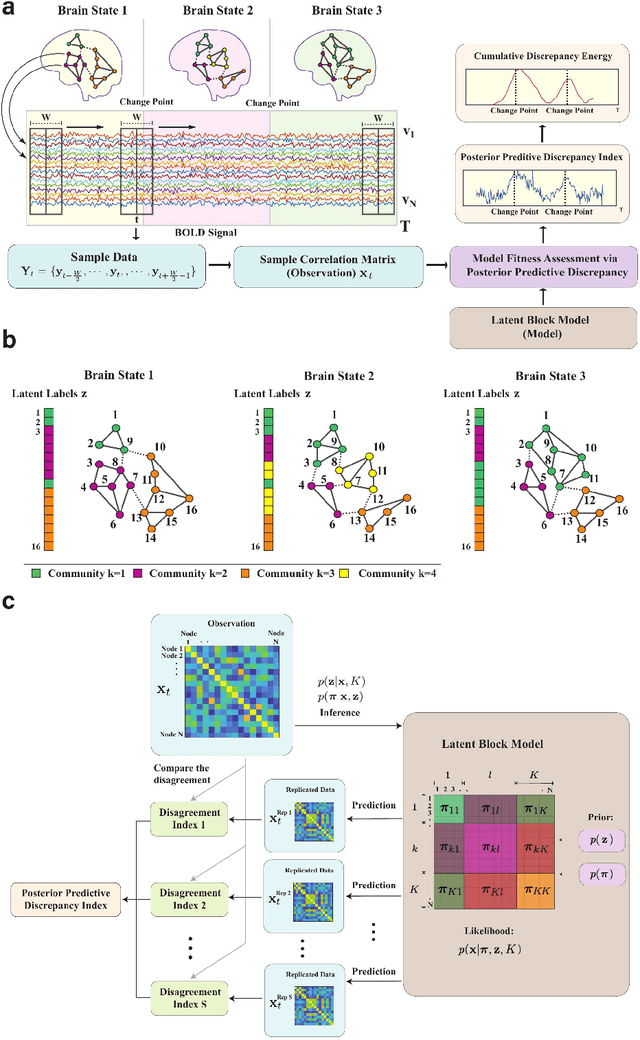
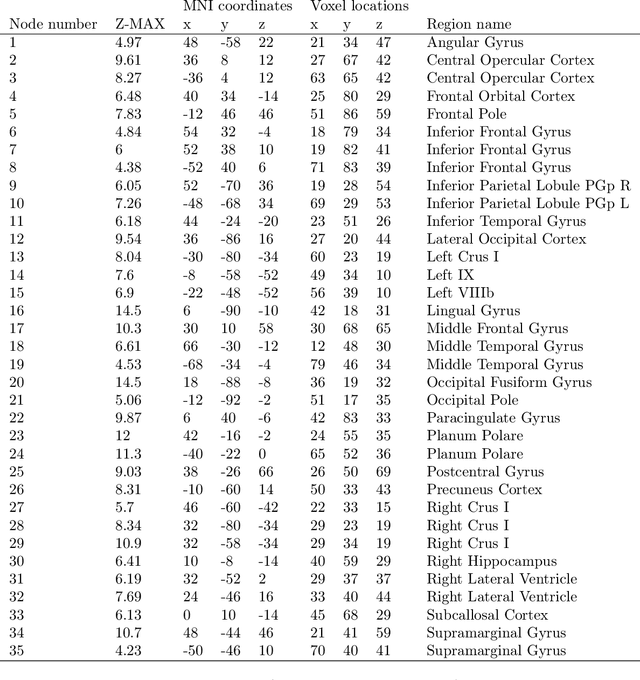
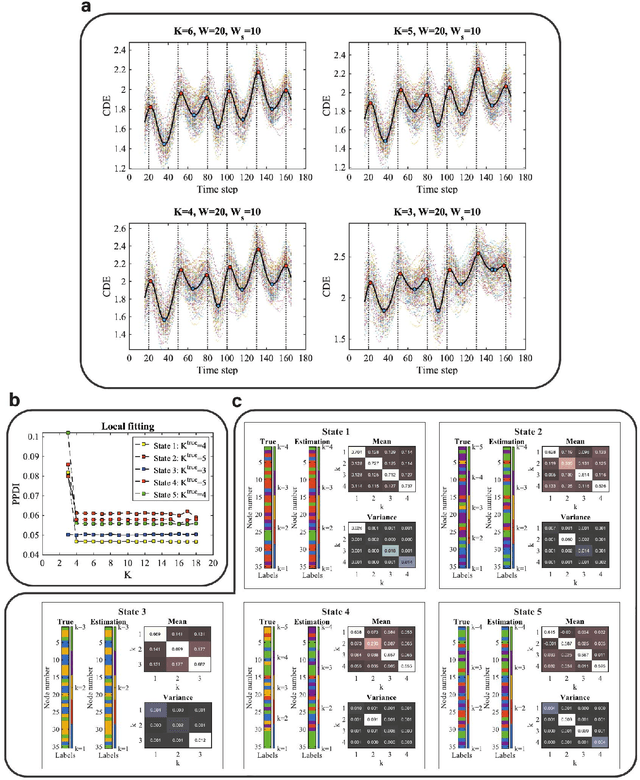

Brain function relies on a precisely coordinated and dynamic balance between the functional integration and segregation of distinct neural systems. Characterizing the way in which neural systems reconfigure their interactions to give rise to distinct but hidden brain states remains an open challenge. In this paper, we propose a Bayesian model-based characterization of latent brain states and showcase a novel method based on posterior predictive discrepancy using the latent block model to detect transitions between latent brain states in blood oxygen level-dependent (BOLD) time series. The set of estimated parameters in the model includes a latent label vector that assigns network nodes to communities, and also block model parameters that reflect the weighted connectivity within and between communities. Besides extensive in-silico model evaluation, we also provide empirical validation (and replication) using the Human Connectome Project (HCP) dataset of 100 healthy adults. Our results obtained through an analysis of task-fMRI data during working memory performance show appropriate lags between external task demands and change-points between brain states, with distinctive community patterns distinguishing fixation, low-demand and high-demand task conditions.
The Future of Data Analysis in the Neurosciences
Aug 05, 2016

Neuroscience is undergoing faster changes than ever before. Over 100 years our field qualitatively described and invasively manipulated single or few organisms to gain anatomical, physiological, and pharmacological insights. In the last 10 years neuroscience spawned quantitative big-sample datasets on microanatomy, synaptic connections, optogenetic brain-behavior assays, and high-level cognition. While growing data availability and information granularity have been amply discussed, we direct attention to a routinely neglected question: How will the unprecedented data richness shape data analysis practices? Statistical reasoning is becoming more central to distill neurobiological knowledge from healthy and pathological brain recordings. We believe that large-scale data analysis will use more models that are non-parametric, generative, mixing frequentist and Bayesian aspects, and grounded in different statistical inferences.