 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Future of Data Analysis in the Neurosciences
Paper and Code
Aug 05, 2016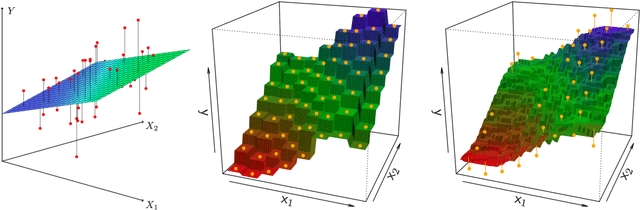
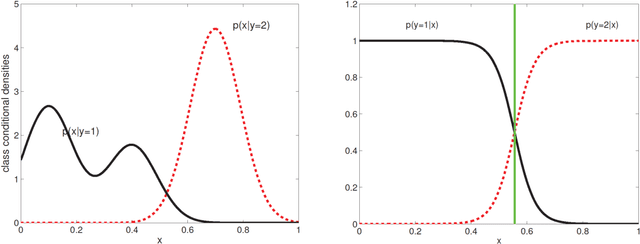

Neuroscience is undergoing faster changes than ever before. Over 100 years our field qualitatively described and invasively manipulated single or few organisms to gain anatomical, physiological, and pharmacological insights. In the last 10 years neuroscience spawned quantitative big-sample datasets on microanatomy, synaptic connections, optogenetic brain-behavior assays, and high-level cognition. While growing data availability and information granularity have been amply discussed, we direct attention to a routinely neglected question: How will the unprecedented data richness shape data analysis practices? Statistical reasoning is becoming more central to distill neurobiological knowledge from healthy and pathological brain recordings. We believe that large-scale data analysis will use more models that are non-parametric, generative, mixing frequentist and Bayesian aspects, and grounded in different statistical inferences.