 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimBEV: A Synthetic Multi-Task Multi-Sensor Driving Data Generation Tool and Dataset
Feb 04, 2025



Bird's-eye view (BEV) perception for autonomous driving has garnered significant attention in recent years, in part because BEV representation facilitates the fusion of multi-sensor data. This enables a variety of perception tasks including BEV segmentation, a concise view of the environment that can be used to plan a vehicle's trajectory. However, this representation is not fully supported by existing datasets, and creation of new datasets can be a time-consuming endeavor. To address this problem, in this paper we introduce SimBEV, an extensively configurable and scalable randomized synthetic data generation tool that incorporates information from multiple sources to capture accurate BEV ground truth data, supports a comprehensive array of sensors, and enables a variety of perception tasks including BEV segmentation and 3D object detection. We use SimBEV to create the SimBEV dataset, a large collection of annotated perception data from diverse driving scenarios.
Image-Guided Outdoor LiDAR Perception Quality Assessment for Autonomous Driving
Jun 25, 2024



LiDAR is one of the most crucial sensors for autonomous vehicle perception. However, current LiDAR-based point cloud perception algorithms lack comprehensive and rigorous LiDAR quality assessment methods, leading to uncertainty in detection performance. Additionally, existing point cloud quality assessment algorithms are predominantly designed for indoor environments or single-object scenarios. In this paper, we introduce a novel image-guided point cloud quality assessment algorithm for outdoor autonomous driving environments, named the Image-Guided Outdoor Point Cloud Quality Assessment (IGO-PQA) algorithm. Our proposed algorithm comprises two main components. The first component is the IGO-PQA generation algorithm, which leverages point cloud data, corresponding RGB surrounding view images, and agent objects' ground truth annotations to generate an overall quality score for a single-frame LiDAR-based point cloud. The second component is a transformer-based IGO-PQA regression algorithm for no-reference outdoor point cloud quality assessment. This regression algorithm allows for the direct prediction of IGO-PQA scores in an online manner, without requiring image data and object ground truth annotations. We evaluate our proposed algorithm using the nuScenes and Waymo open datasets. The IGO-PQA generation algorithm provides consistent and reasonable perception quality indices. Furthermore, our proposed IGO-PQA regression algorithm achieves a Pearson Linear Correlation Coefficient (PLCC) of 0.86 on the nuScenes dataset and 0.97 on the Waymo dataset.
Exploration Without Maps via Zero-Shot Out-of-Distribution Deep Reinforcement Learning
Feb 07, 2024Operation of Autonomous Mobile Robots (AMRs) of all forms that include wheeled ground vehicles, quadrupeds and humanoids in dynamically changing GPS denied environments without a-priori maps, exclusively using onboard sensors, is an unsolved problem that has potential to transform the economy, and vastly improve humanity's capabilities with improvements to agriculture, manufacturing, disaster response, military and space exploration. Conventional AMR automation approaches are modularized into perception, motion planning and control which is computationally inefficient, and requires explicit feature extraction and engineering, that inhibits generalization, and deployment at scale. Few works have focused on real-world end-to-end approaches that directly map sensor inputs to control outputs due to the large amount of well curated training data required for supervised Deep Learning (DL) which is time consuming and labor intensive to collect and label, and sample inefficiency and challenges to bridging the simulation to reality gap using Deep Reinforcement Learning (DRL). This paper presents a novel method to efficiently train DRL for robust end-to-end AMR exploration, in a constrained environment at physical limits in simulation, transferred zero-shot to the real-world. The representation learned in a compact parameter space with 2 fully connected layers with 64 nodes each is demonstrated to exhibit emergent behavior for out-of-distribution generalization to navigation in new environments that include unstructured terrain without maps, and dynamic obstacle avoidance. The learned policy outperforms conventional navigation algorithms while consuming a fraction of the computation resources, enabling execution on a range of AMR forms with varying embedded computer payloads.
Cooperative Probabilistic Trajectory Forecasting under Occlusion
Dec 06, 2023



Perception and planning under occlusion is essential for safety-critical tasks. Occlusion-aware planning often requires communicating the information of the occluded object to the ego agent for safe navigation. However, communicating rich sensor information under adverse conditions during communication loss and limited bandwidth may not be always feasible. Further, in GPS denied environments and indoor navigation, localizing and sharing of occluded objects can be challenging. To overcome this, relative pose estimation between connected agents sharing a common field of view can be a computationally effective way of communicating information about surrounding objects. In this paper, we design an end-to-end network that cooperatively estimates the current states of occluded pedestrian in the reference frame of ego agent and then predicts the trajectory with safety guarantees. Experimentally, we show that the uncertainty-aware trajectory prediction of occluded pedestrian by the ego agent is almost similar to the ground truth trajectory assuming no occlusion. The current research holds promise for uncertainty-aware navigation among multiple connected agents under occlusion.
The Impact of Different Backbone Architecture on Autonomous Vehicle Dataset
Sep 15, 2023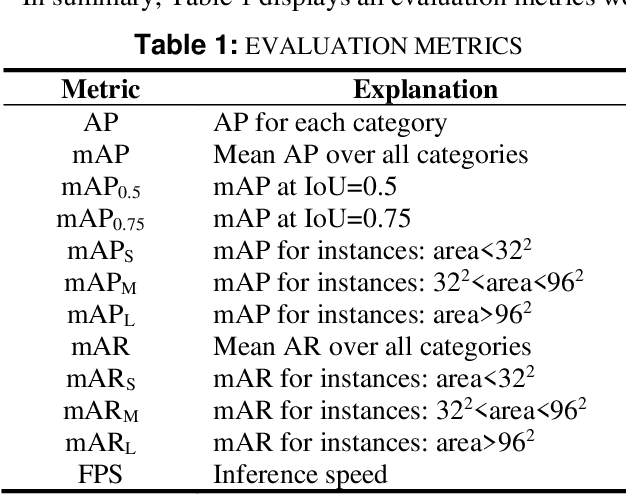
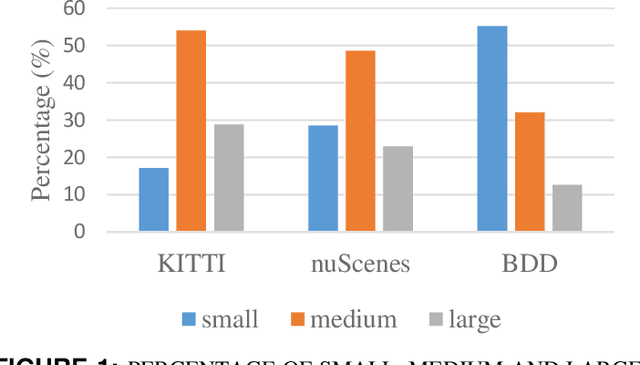
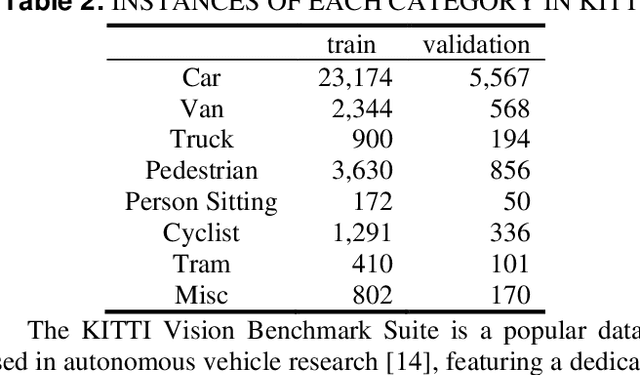
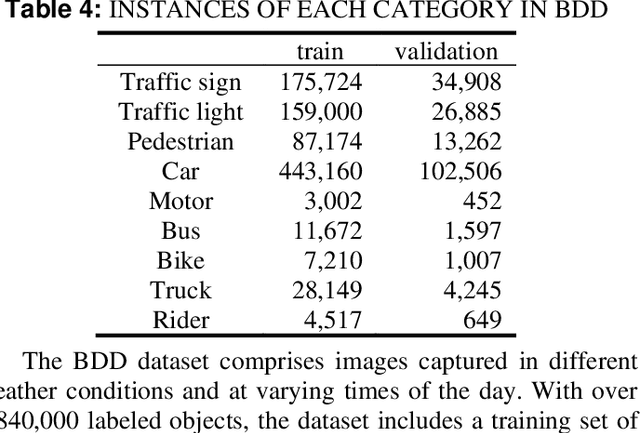
Object detection is a crucial component of autonomous driving, and many detection applications have been developed to address this task. These applications often rely on backbone architectures, which extract representation features from inputs to perform the object detection task. The quality of the features extracted by the backbone architecture can have a significant impact on the overall detection performance. Many researchers have focused on developing new and improved backbone architectures to enhance the efficiency and accuracy of object detection applications. While these backbone architectures have shown state-of-the-art performance on generic object detection datasets like MS-COCO and PASCAL-VOC, evaluating their performance under an autonomous driving environment has not been previously explored. To address this, our study evaluates three well-known autonomous vehicle datasets, namely KITTI, NuScenes, and BDD, to compare the performance of different backbone architectures on object detection tasks.
Pedestrian Trajectory Forecasting Using Deep Ensembles Under Sensing Uncertainty
May 26, 2023One of the fundamental challenges in the prediction of dynamic agents is robustness. Usually, most predictions are deterministic estimates of future states which are over-confident and prone to error. Recently, few works have addressed capturing uncertainty during forecasting of future states. However, these probabilistic estimation methods fail to account for the upstream noise in perception data during tracking. Sensors always have noise and state estimation becomes even more difficult under adverse weather conditions and occlusion. Traditionally, Bayes filters have been used to fuse information from noisy sensors to update states with associated belief. But, they fail to address non-linearities and long-term predictions. Therefore, we propose an end-to-end estimator that can take noisy sensor measurements and make robust future state predictions with uncertainty bounds while simultaneously taking into consideration the upstream perceptual uncertainty. For the current research, we consider an encoder-decoder based deep ensemble network for capturing both perception and predictive uncertainty simultaneously. We compared the current model to other approximate Bayesian inference methods. Overall, deep ensembles provided more robust predictions and the consideration of upstream uncertainty further increased the estimation accuracy for the model.
Probabilistic RRT Connect with intermediate goal selection for online planning of autonomous vehicles
May 14, 2023Rapidly Exploring Random Trees (RRT) is one of the most widely used algorithms for motion planning in the field of robotics. To reduce the exploration time, RRT-Connect was introduced where two trees are simultaneously formed and eventually connected. Probabilistic RRT used the concept of position probability map to introduce goal biasing for faster convergence. In this paper, we propose a modified method to combine the pRRT and RRT-Connect techniques and obtain a feasible trajectory around the obstacles quickly. Instead of forming a single tree from the start point to the destination point, intermediate goal points are selected around the obstacles. Multiple trees are formed to connect the start, destination, and intermediate goal points. These partial trees are eventually connected to form an overall safe path around the obstacles. The obtained path is tracked using an MPC + Stanley controller which results in a trajectory with control commands at each time step. The trajectories generated by the proposed methods are more optimal and in accordance with human intuition. The algorithm is compared with the standard RRT and pRRT for studying its relative performance.
SalienDet: A Saliency-based Feature Enhancement Algorithm for Object Detection for Autonomous Driving
May 11, 2023Object detection (OD) is crucial to autonomous driving. Unknown objects are one of the reasons that hinder autonomous vehicles from driving beyond the operational domain. We propose a saliency-based OD algorithm (SalienDet) to detect objects that do not appear in the training sample set. SalienDet utilizes a saliency-based algorithm to enhance image features for object proposal generation. Then, we design a dataset relabeling approach to differentiate the unknown objects from all objects to achieve open-world detection. We evaluate SalienDet on KITTI, NuScenes, and BDD datasets, and the result indicates that it outperforms existing algorithms for unknown object detection. Additionally, SalienDet can be easily adapted for incremental learning in open-world detection tasks.
AutoVRL: A High Fidelity Autonomous Ground Vehicle Simulator for Sim-to-Real Deep Reinforcement Learning
Apr 22, 2023Deep Reinforcement Learning (DRL) enables cognitive Autonomous Ground Vehicle (AGV) navigation utilizing raw sensor data without a-priori maps or GPS, which is a necessity in hazardous, information poor environments such as regions where natural disasters occur, and extraterrestrial planets. The substantial training time required to learn an optimal DRL policy, which can be days or weeks for complex tasks, is a major hurdle to real-world implementation in AGV applications. Training entails repeated collisions with the surrounding environment over an extended time period, dependent on the complexity of the task, to reinforce positive exploratory, application specific behavior that is expensive, and time consuming in the real-world. Effectively bridging the simulation to real-world gap is a requisite for successful implementation of DRL in complex AGV applications, enabling learning of cost-effective policies. We present AutoVRL, an open-source high fidelity simulator built upon the Bullet physics engine utilizing OpenAI Gym and Stable Baselines3 in PyTorch to train AGV DRL agents for sim-to-real policy transfer. AutoVRL is equipped with sensor implementations of GPS, IMU, LiDAR and camera, actuators for AGV control, and realistic environments, with extensibility for new environments and AGV models. The simulator provides access to state-of-the-art DRL algorithms, utilizing a python interface for simple algorithm and environment customization, and simulation execution.
Deep Reinforcement Learning for Autonomous Ground Vehicle Exploration Without A-Priori Maps
Jan 10, 2023Autonomous Ground Vehicles (AGVs) are essential tools for a wide range of applications stemming from their ability to operate in hazardous environments with minimal human operator input. Efficient and effective motion planning is paramount for successful operation of AGVs. Conventional motion planning algorithms are dependent on prior knowledge of environment characteristics and offer limited utility in information poor, dynamically altering environments such as areas where emergency hazards like fire and earthquake occur, and unexplored subterranean environments such as tunnels and lava tubes on Mars. We propose a Deep Reinforcement Learning (DRL) framework for intelligent AGV exploration without a-priori maps utilizing Actor-Critic DRL algorithms to learn policies in continuous and high-dimensional action spaces, required for robotics applications. The DRL architecture comprises feedforward neural networks for the critic and actor representations in which the actor network strategizes linear and angular velocity control actions given current state inputs, that are evaluated by the critic network which learns and estimates Q-values to maximize an accumulated reward. Three off-policy DRL algorithms, DDPG, TD3 and SAC, are trained and compared in two environments of varying complexity, and further evaluated in a third with no prior training or knowledge of map characteristics. The agent is shown to learn optimal policies at the end of each training period to chart quick, efficient and collision-free exploration trajectories, and is extensible, capable of adapting to an unknown environment with no changes to network architecture or hyperparameters.