 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive World Simulator for Robot Policy Training and Evaluation
Mar 09, 2026Action-conditioned video prediction models (often referred to as world models) have shown strong potential for robotics applications, but existing approaches are often slow and struggle to capture physically consistent interactions over long horizons, limiting their usefulness for scalable robot policy training and evaluation. We present Interactive World Simulator, a framework for building interactive world models from a moderate-sized robot interaction dataset. Our approach leverages consistency models for both image decoding and latent-space dynamics prediction, enabling fast and stable simulation of physical interactions. In our experiments, the learned world models produce interaction-consistent pixel-level predictions and support stable long-horizon interactions for more than 10 minutes at 15 FPS on a single RTX 4090 GPU. Our framework enables scalable demonstration collection solely within the world models to train state-of-the-art imitation policies. Through extensive real-world evaluation across diverse tasks involving rigid objects, deformable objects, object piles, and their interactions, we find that policies trained on world-model-generated data perform comparably to those trained on the same amount of real-world data. Additionally, we evaluate policies both within the world models and in the real world across diverse tasks, and observe a strong correlation between simulated and real-world performance. Together, these results establish the Interactive World Simulator as a stable and physically consistent surrogate for scalable robotic data generation and faithful, reproducible policy evaluation.
ERA: Transforming VLMs into Embodied Agents via Embodied Prior Learning and Online Reinforcement Learning
Oct 14, 2025Recent advances in embodied AI highlight the potential of vision language models (VLMs) as agents capable of perception, reasoning, and interaction in complex environments. However, top-performing systems rely on large-scale models that are costly to deploy, while smaller VLMs lack the necessary knowledge and skills to succeed. To bridge this gap, we present \textit{Embodied Reasoning Agent (ERA)}, a two-stage framework that integrates prior knowledge learning and online reinforcement learning (RL). The first stage, \textit{Embodied Prior Learning}, distills foundational knowledge from three types of data: (1) Trajectory-Augmented Priors, which enrich existing trajectory data with structured reasoning generated by stronger models; (2) Environment-Anchored Priors, which provide in-environment knowledge and grounding supervision; and (3) External Knowledge Priors, which transfer general knowledge from out-of-environment datasets. In the second stage, we develop an online RL pipeline that builds on these priors to further enhance agent performance. To overcome the inherent challenges in agent RL, including long horizons, sparse rewards, and training instability, we introduce three key designs: self-summarization for context management, dense reward shaping, and turn-level policy optimization. Extensive experiments on both high-level planning (EB-ALFRED) and low-level control (EB-Manipulation) tasks demonstrate that ERA-3B surpasses both prompting-based large models and previous training-based baselines. Specifically, it achieves overall improvements of 8.4\% on EB-ALFRED and 19.4\% on EB-Manipulation over GPT-4o, and exhibits strong generalization to unseen tasks. Overall, ERA offers a practical path toward scalable embodied intelligence, providing methodological insights for future embodied AI systems.
Integrating Risk in Humanoid Robot Control for Applications in the Nuclear Industry
Jul 12, 2018
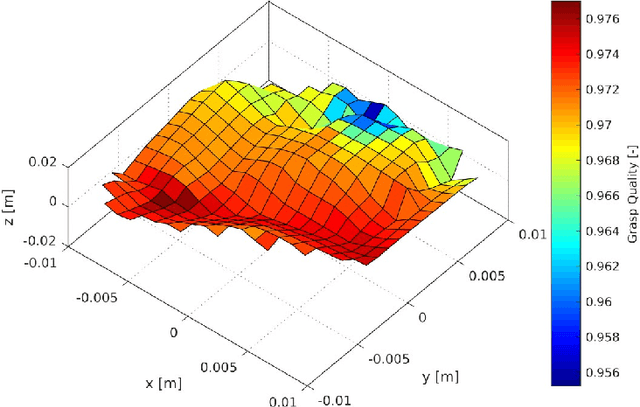
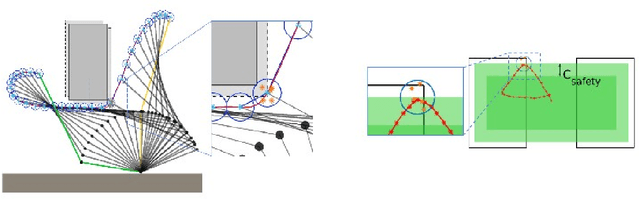
This paper discuss the integration of risk into a robot control framework for decommissioning applications in the nuclear industry. Our overall objective is to allow the robot to evaluate a risk associated with several methods of completing the same task by combining a set of action sequences. If the environment is known and in the absence of sensing errors each set of actions would successfully complete the task. In this paper, instead of attempting to model the errors associated with each sensing system in order to compute an exact solution, a set of solutions are obtained along with a prescribed risk index. The risk associated with each set of actions can then be compared to possible payoffs or rewards, for instance task completion time or power consumption. This information is then sent to a high level decision planner, for instance a human teleoperator, who can then make a more informed decision regarding the robots actions. In order to illustrate the concept, we introduce three specific risk measures, namely, the collision risk and the risk of toppling and failure risk associated with grasping an object. We demonstrate the results from this foundational study of risk-aware compositional robot autonomy in simulation using NASA's Valkyrie humanoid robot, and the grasping simulator HAPTIX.
* 9 pages, 6 figues
Using Contact to Increase Robot Performance for Glovebox D&D Tasks
Jul 11, 2018
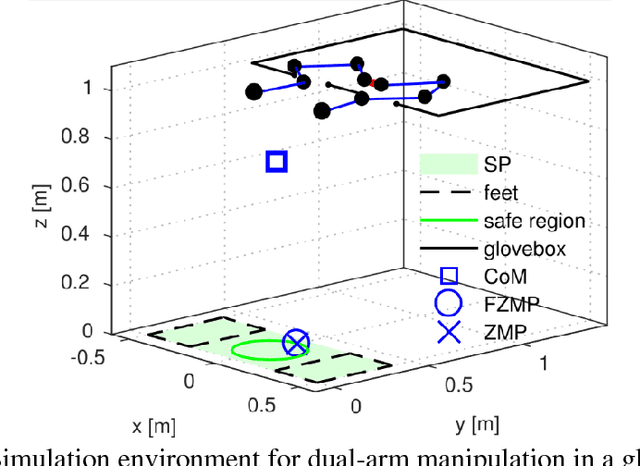
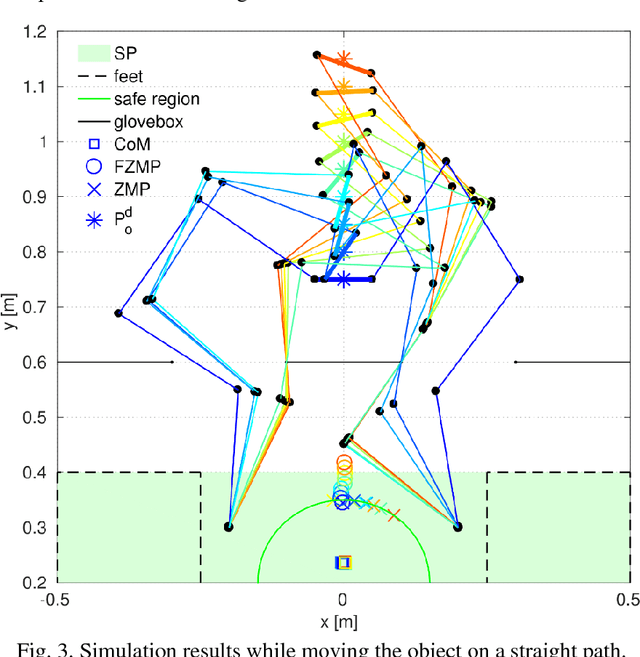
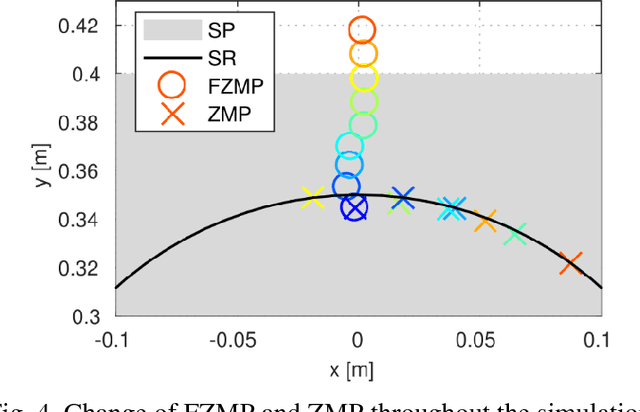
Glovebox decommissioning tasks usually require manipulating relatively heavy objects in a highly constrained environment. Thus, contact with the surroundings becomes inevitable. In order to allow the robot to interact with the environment in a natural way, we present a contact-implicit motion planning framework. This framework enables the system, without the specification in advance of a contact plan, to make and break contacts to maintain stability while performing a manipulation task. In this method, we use linear complementarity constraints to model rigid body contacts and find a locally optimal solution for joint displacements and magnitudes of support forces. Then, joint torques are calculated such that the support forces have the highest priority. We evaluate our framework in a 2.5D, quasi-static simulation in which a humanoid robot with planar arms manipulates a heavy object. Our results suggest that the proposed method provides the robot with the ability to balance itself by generating support forces on the environment while simultaneously performing the manipulation task.