 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMalaria Detection from Blood Cell Images Using XceptionNet
Oct 22, 2025Malaria, which primarily spreads with the bite of female anopheles mosquitos, often leads to death of people - specifically children in the age-group of 0-5 years. Clinical experts identify malaria by observing RBCs in blood smeared images with a microscope. Lack of adequate professional knowledge and skills, and most importantly manual involvement may cause incorrect diagnosis. Therefore, computer aided automatic diagnosis stands as a preferred substitute. In this paper, well-demonstrated deep networks have been applied to extract deep intrinsic features from blood cell images and thereafter classify them as malaria infected or healthy cells. Among the six deep convolutional networks employed in this work viz. AlexNet, XceptionNet, VGG-19, Residual Attention Network, DenseNet-121 and Custom-CNN. Residual Attention Network and XceptionNet perform relatively better than the rest on a publicly available malaria cell image dataset. They yield an average accuracy of 97.28% and 97.55% respectively, that surpasses other related methods on the same dataset. These findings highly encourage the reality of deep learning driven method for automatic and reliable detection of malaria while minimizing direct manual involvement.
A Supervised Machine Learning Approach for Sequence Based Protein-protein Interaction (PPI) Prediction
Mar 27, 2022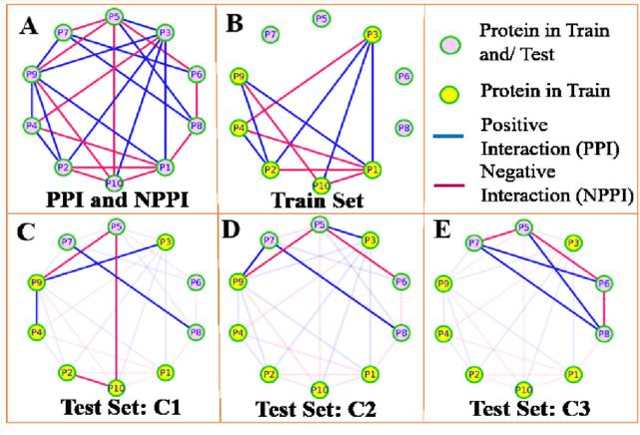
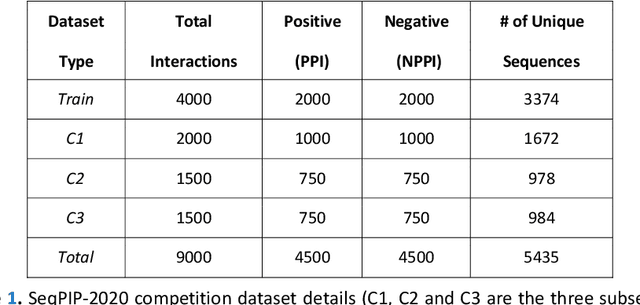
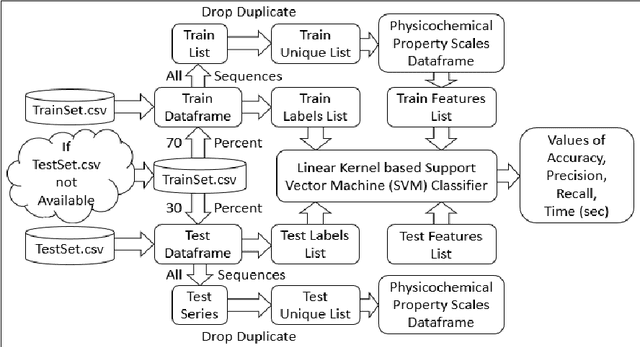
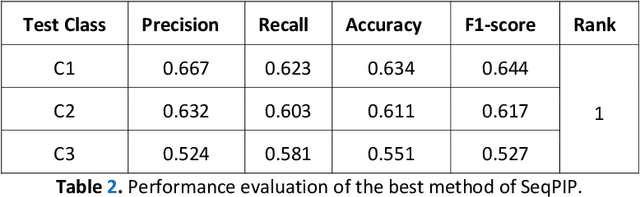
Computational protein-protein interaction (PPI) prediction techniques can contribute greatly in reducing time, cost and false-positive interactions compared to experimental approaches. Sequence is one of the key and primary information of proteins that plays a crucial role in PPI prediction. Several machine learning approaches have been applied to exploit the characteristics of PPI datasets. However, these datasets greatly influence the performance of predicting models. So, care should be taken on both dataset curation as well as design of predictive models. Here, we have described our submitted solution with the results of the SeqPIP competition whose objective was to develop comprehensive PPI predictive models from sequence information with high-quality bias-free interaction datasets. A training set of 2000 positive and 2000 negative interactions with sequences was given to us. Our method was evaluated with three independent high-quality interaction test datasets and with other competitors solutions.
Computationally Efficient Implementation of Convolution-based Locally Adaptive Binarization Techniques
Oct 11, 2012



One of the most important steps of document image processing is binarization. The computational requirements of locally adaptive binarization techniques make them unsuitable for devices with limited computing facilities. In this paper, we have presented a computationally efficient implementation of convolution based locally adaptive binarization techniques keeping the performance comparable to the original implementation. The computational complexity has been reduced from O(W2N2) to O(WN2) where WxW is the window size and NxN is the image size. Experiments over benchmark datasets show that the computation time has been reduced by 5 to 15 times depending on the window size while memory consumption remains the same with respect to the state-of-the-art algorithmic implementation.
Design of an Optical Character Recognition System for Camera-based Handheld Devices
Sep 15, 2011
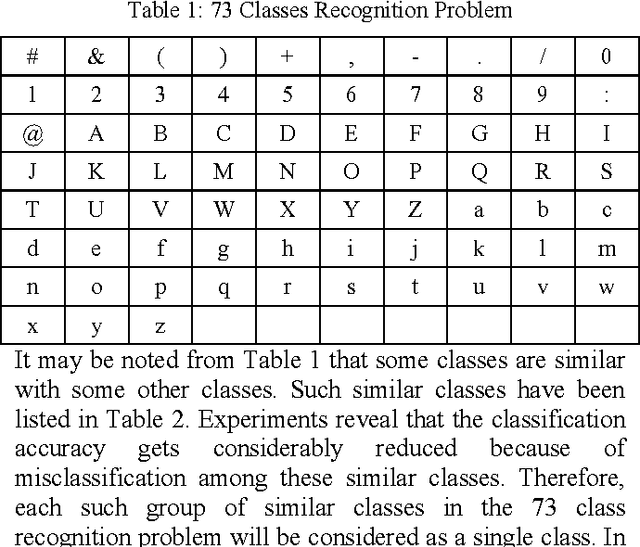

This paper presents a complete Optical Character Recognition (OCR) system for camera captured image/graphics embedded textual documents for handheld devices. At first, text regions are extracted and skew corrected. Then, these regions are binarized and segmented into lines and characters. Characters are passed into the recognition module. Experimenting with a set of 100 business card images, captured by cell phone camera, we have achieved a maximum recognition accuracy of 92.74%. Compared to Tesseract, an open source desktop-based powerful OCR engine, present recognition accuracy is worth contributing. Moreover, the developed technique is computationally efficient and consumes low memory so as to be applicable on handheld devices.
Segmentation of Camera Captured Business Card Images for Mobile Devices
Jan 03, 2011



Due to huge deformation in the camera captured images, variety in nature of the business cards and the computational constraints of the mobile devices, design of an efficient Business Card Reader (BCR) is challenging to the researchers. Extraction of text regions and segmenting them into characters is one of such challenges. In this paper, we have presented an efficient character segmentation technique for business card images captured by a cell-phone camera, designed in our present work towards developing an efficient BCR. At first, text regions are extracted from the card images and then the skewed ones are corrected using a computationally efficient skew correction technique. At last, these skew corrected text regions are segmented into lines and characters based on horizontal and vertical histogram. Experiments show that the present technique is efficient and applicable for mobile devices, and the mean segmentation accuracy of 97.48% is achieved with 3 mega-pixel (500-600 dpi) images. It takes only 1.1 seconds for segmentation including all the preprocessing steps on a moderately powerful notebook (DualCore T2370, 1.73 GHz, 1GB RAM, 1MB L2 Cache).
Text Region Extraction from Business Card Images for Mobile Devices
Mar 09, 2010



Designing a Business Card Reader (BCR) for mobile devices is a challenge to the researchers because of huge deformation in acquired images, multiplicity in nature of the business cards and most importantly the computational constraints of the mobile devices. This paper presents a text extraction method designed in our work towards developing a BCR for mobile devices. At first, the background of a camera captured image is eliminated at a coarse level. Then, various rule based techniques are applied on the Connected Components (CC) to filter out the noises and picture regions. The CCs identified as text are then binarized using an adaptive but light-weight binarization technique. Experiments show that the text extraction accuracy is around 98% for a wide range of resolutions with varying computation time and memory requirements. The optimum performance is achieved for the images of resolution 1024x768 pixels with text extraction accuracy of 98.54% and, space and time requirements as 1.1 MB and 0.16 seconds respectively.
A comparative study of different feature sets for recognition of handwritten Arabic numerals using a Multi Layer Perceptron
Mar 09, 2010


The work presents a comparative assessment of seven different feature sets for recognition of handwritten Arabic numerals using a Multi Layer Perceptron (MLP) based classifier. The seven feature sets employed here consist of shadow features, octant centroids, longest runs, angular distances, effective spans, dynamic centers of gravity, and some of their combinations. On experimentation with a database of 3000 samples, the maximum recognition rate of 95.80% is observed with both of two separate combinations of features. One of these combinations consists of shadow and centriod features, i. e. 88 features in all, and the other shadow, centroid and longest run features, i. e. 124 features in all. Out of these two, the former combination having a smaller number of features is finally considered effective for applications related to Optical Character Recognition (OCR) of handwritten Arabic numerals. The work can also be extended to include OCR of handwritten characters of Arabic alphabet.
Handwritten Arabic Numeral Recognition using a Multi Layer Perceptron
Mar 09, 2010


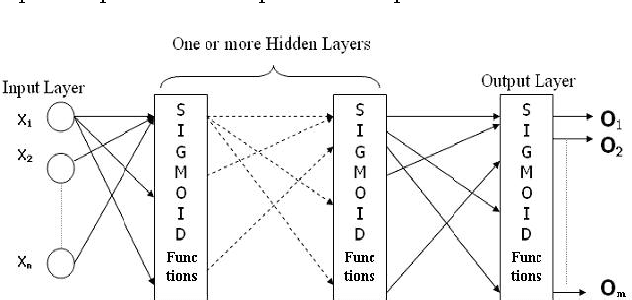
Handwritten numeral recognition is in general a benchmark problem of Pattern Recognition and Artificial Intelligence. Compared to the problem of printed numeral recognition, the problem of handwritten numeral recognition is compounded due to variations in shapes and sizes of handwritten characters. Considering all these, the problem of handwritten numeral recognition is addressed under the present work in respect to handwritten Arabic numerals. Arabic is spoken throughout the Arab World and the fifth most popular language in the world slightly before Portuguese and Bengali. For the present work, we have developed a feature set of 88 features is designed to represent samples of handwritten Arabic numerals for this work. It includes 72 shadow and 16 octant features. A Multi Layer Perceptron (MLP) based classifier is used here for recognition handwritten Arabic digits represented with the said feature set. On experimentation with a database of 3000 samples, the technique yields an average recognition rate of 94.93% evaluated after three-fold cross validation of results. It is useful for applications related to OCR of handwritten Arabic Digit and can also be extended to include OCR of handwritten characters of Arabic alphabet.
Binarizing Business Card Images for Mobile Devices
Mar 08, 2010



Business card images are of multiple natures as these often contain graphics, pictures and texts of various fonts and sizes both in background and foreground. So, the conventional binarization techniques designed for document images can not be directly applied on mobile devices. In this paper, we have presented a fast binarization technique for camera captured business card images. A card image is split into small blocks. Some of these blocks are classified as part of the background based on intensity variance. Then the non-text regions are eliminated and the text ones are skew corrected and binarized using a simple yet adaptive technique. Experiment shows that the technique is fast, efficient and applicable for the mobile devices.