 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing human-like sketches from natural images using a conditional convolutional decoder
Mar 16, 2020
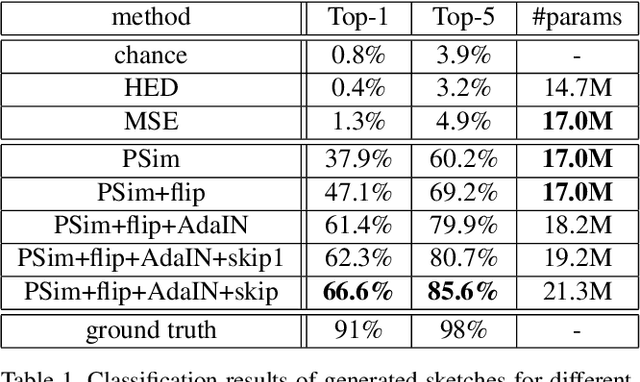
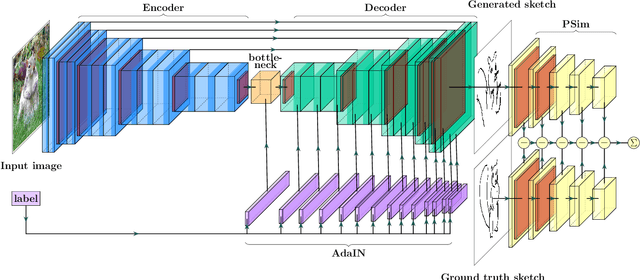

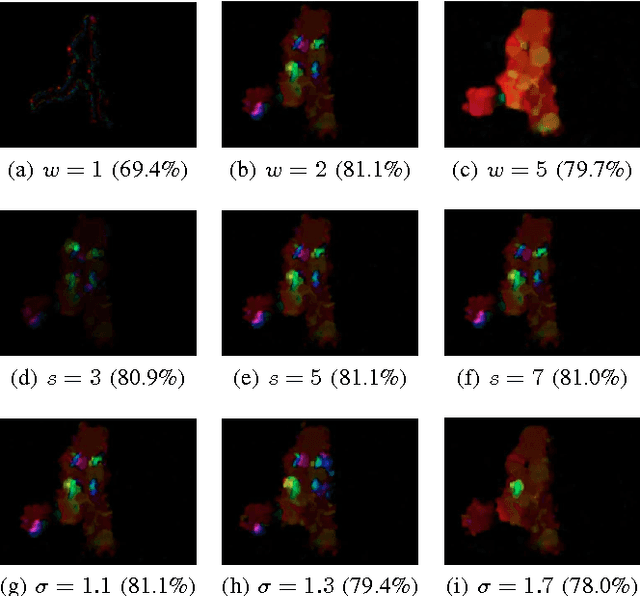
Humans are able to precisely communicate diverse concepts by employing sketches, a highly reduced and abstract shape based representation of visual content. We propose, for the first time, a fully convolutional end-to-end architecture that is able to synthesize human-like sketches of objects in natural images with potentially cluttered background. To enable an architecture to learn this highly abstract mapping, we employ the following key components: (1) a fully convolutional encoder-decoder structure, (2) a perceptual similarity loss function operating in an abstract feature space and (3) conditioning of the decoder on the label of the object that shall be sketched. Given the combination of these architectural concepts, we can train our structure in an end-to-end supervised fashion on a collection of sketch-image pairs. The generated sketches of our architecture can be classified with 85.6% Top-5 accuracy and we verify their visual quality via a user study. We find that deep features as a perceptual similarity metric enable image translation with large domain gaps and our findings further show that convolutional neural networks trained on image classification tasks implicitly learn to encode shape information. Code is available under https://github.com/kampelmuehler/synthesizing_human_like_sketches
Detect to Track and Track to Detect
Mar 07, 2018
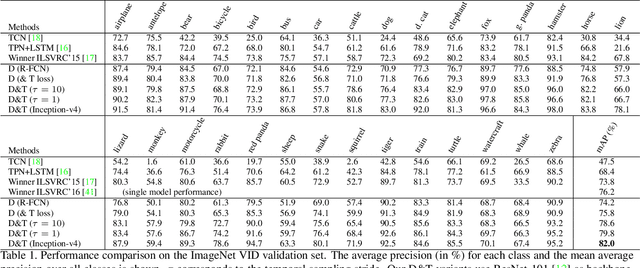

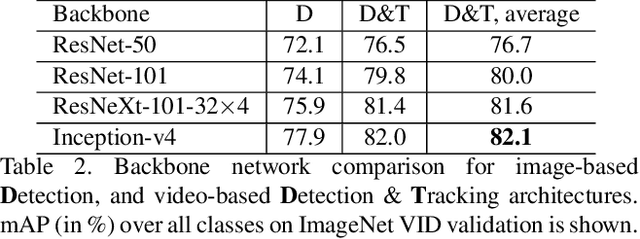
Recent approaches for high accuracy detection and tracking of object categories in video consist of complex multistage solutions that become more cumbersome each year. In this paper we propose a ConvNet architecture that jointly performs detection and tracking, solving the task in a simple and effective way. Our contributions are threefold: (i) we set up a ConvNet architecture for simultaneous detection and tracking, using a multi-task objective for frame-based object detection and across-frame track regression; (ii) we introduce correlation features that represent object co-occurrences across time to aid the ConvNet during tracking; and (iii) we link the frame level detections based on our across-frame tracklets to produce high accuracy detections at the video level. Our ConvNet architecture for spatiotemporal object detection is evaluated on the large-scale ImageNet VID dataset where it achieves state-of-the-art results. Our approach provides better single model performance than the winning method of the last ImageNet challenge while being conceptually much simpler. Finally, we show that by increasing the temporal stride we can dramatically increase the tracker speed.
What have we learned from deep representations for action recognition?
Jan 04, 2018
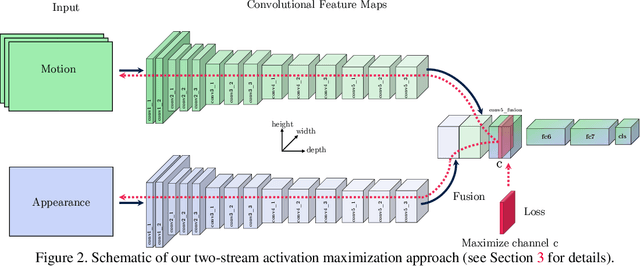


As the success of deep models has led to their deployment in all areas of computer vision, it is increasingly important to understand how these representations work and what they are capturing. In this paper, we shed light on deep spatiotemporal representations by visualizing what two-stream models have learned in order to recognize actions in video. We show that local detectors for appearance and motion objects arise to form distributed representations for recognizing human actions. Key observations include the following. First, cross-stream fusion enables the learning of true spatiotemporal features rather than simply separate appearance and motion features. Second, the networks can learn local representations that are highly class specific, but also generic representations that can serve a range of classes. Third, throughout the hierarchy of the network, features become more abstract and show increasing invariance to aspects of the data that are unimportant to desired distinctions (e.g. motion patterns across various speeds). Fourth, visualizations can be used not only to shed light on learned representations, but also to reveal idiosyncracies of training data and to explain failure cases of the system.
Spatiotemporal Residual Networks for Video Action Recognition
Nov 07, 2016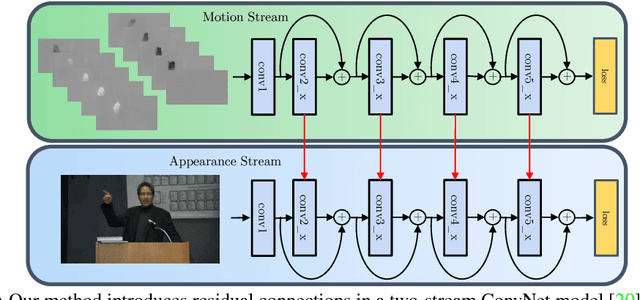
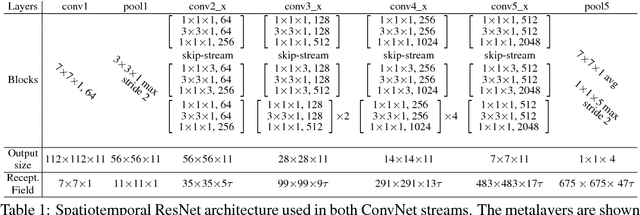
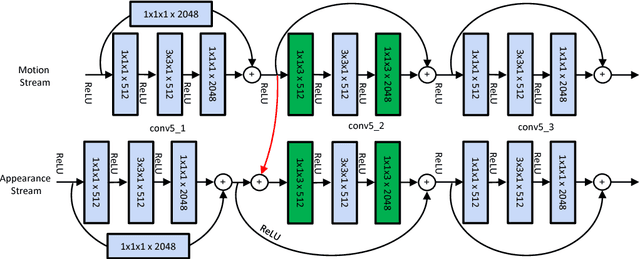
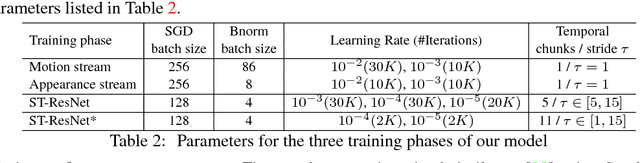
Two-stream Convolutional Networks (ConvNets) have shown strong performance for human action recognition in videos. Recently, Residual Networks (ResNets) have arisen as a new technique to train extremely deep architectures. In this paper, we introduce spatiotemporal ResNets as a combination of these two approaches. Our novel architecture generalizes ResNets for the spatiotemporal domain by introducing residual connections in two ways. First, we inject residual connections between the appearance and motion pathways of a two-stream architecture to allow spatiotemporal interaction between the two streams. Second, we transform pretrained image ConvNets into spatiotemporal networks by equipping these with learnable convolutional filters that are initialized as temporal residual connections and operate on adjacent feature maps in time. This approach slowly increases the spatiotemporal receptive field as the depth of the model increases and naturally integrates image ConvNet design principles. The whole model is trained end-to-end to allow hierarchical learning of complex spatiotemporal features. We evaluate our novel spatiotemporal ResNet using two widely used action recognition benchmarks where it exceeds the previous state-of-the-art.
Convolutional Two-Stream Network Fusion for Video Action Recognition
Sep 26, 2016
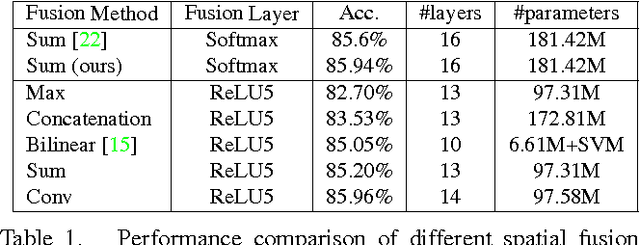
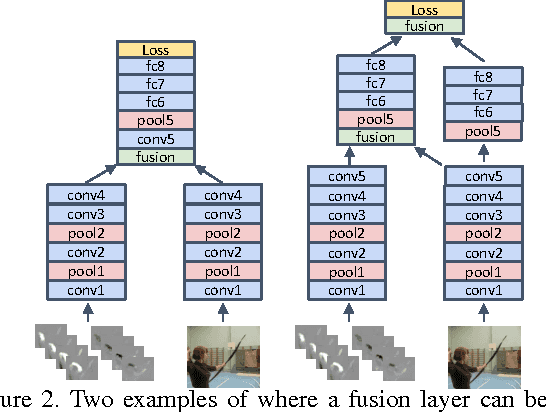

Recent applications of Convolutional Neural Networks (ConvNets) for human action recognition in videos have proposed different solutions for incorporating the appearance and motion information. We study a number of ways of fusing ConvNet towers both spatially and temporally in order to best take advantage of this spatio-temporal information. We make the following findings: (i) that rather than fusing at the softmax layer, a spatial and temporal network can be fused at a convolution layer without loss of performance, but with a substantial saving in parameters; (ii) that it is better to fuse such networks spatially at the last convolutional layer than earlier, and that additionally fusing at the class prediction layer can boost accuracy; finally (iii) that pooling of abstract convolutional features over spatiotemporal neighbourhoods further boosts performance. Based on these studies we propose a new ConvNet architecture for spatiotemporal fusion of video snippets, and evaluate its performance on standard benchmarks where this architecture achieves state-of-the-art results.
Combining Spatio-Temporal Appearance Descriptors and Optical Flow for Human Action Recognition in Video Data
Oct 01, 2013
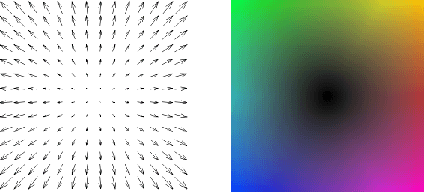

This paper proposes combining spatio-temporal appearance (STA) descriptors with optical flow for human action recognition. The STA descriptors are local histogram-based descriptors of space-time, suitable for building a partial representation of arbitrary spatio-temporal phenomena. Because of the possibility of iterative refinement, they are interesting in the context of online human action recognition. We investigate the use of dense optical flow as the image function of the STA descriptor for human action recognition, using two different algorithms for computing the flow: the Farneb\"ack algorithm and the TVL1 algorithm. We provide a detailed analysis of the influencing optical flow algorithm parameters on the produced optical flow fields. An extensive experimental validation of optical flow-based STA descriptors in human action recognition is performed on the KTH human action dataset. The encouraging experimental results suggest the potential of our approach in online human action recognition.