 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reversible De-Identification in Video Sequences Using 3D Avatars and Steganography
Oct 16, 2015


We propose a de-identification pipeline that protects the privacy of humans in video sequences by replacing them with rendered 3D human models, hence concealing their identity while retaining the naturalness of the scene. The original images of humans are steganographically encoded in the carrier image, i.e. the image containing the original scene and the rendered 3D human models. We qualitatively explore the feasibility of our approach, utilizing the Kinect sensor and its libraries to detect and localize human joints. A 3D avatar is rendered into the scene using the obtained joint positions, and the original human image is steganographically encoded in the new scene. Our qualitative evaluation shows reasonably good results that merit further exploration.
Classifying Traffic Scenes Using The GIST Image Descriptor
Oct 01, 2013
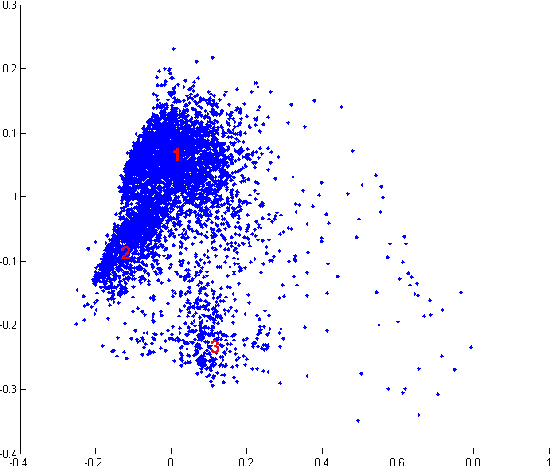


This paper investigates classification of traffic scenes in a very low bandwidth scenario, where an image should be coded by a small number of features. We introduce a novel dataset, called the FM1 dataset, consisting of 5615 images of eight different traffic scenes: open highway, open road, settlement, tunnel, tunnel exit, toll booth, heavy traffic and the overpass. We evaluate the suitability of the GIST descriptor as a representation of these images, first by exploring the descriptor space using PCA and k-means clustering, and then by using an SVM classifier and recording its 10-fold cross-validation performance on the introduced FM1 dataset. The obtained recognition rates are very encouraging, indicating that the use of the GIST descriptor alone could be sufficiently descriptive even when very high performance is required.
Combining Spatio-Temporal Appearance Descriptors and Optical Flow for Human Action Recognition in Video Data
Oct 01, 2013
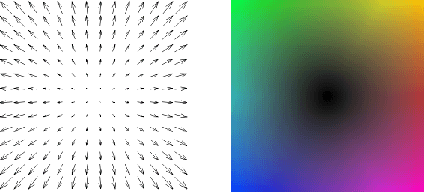
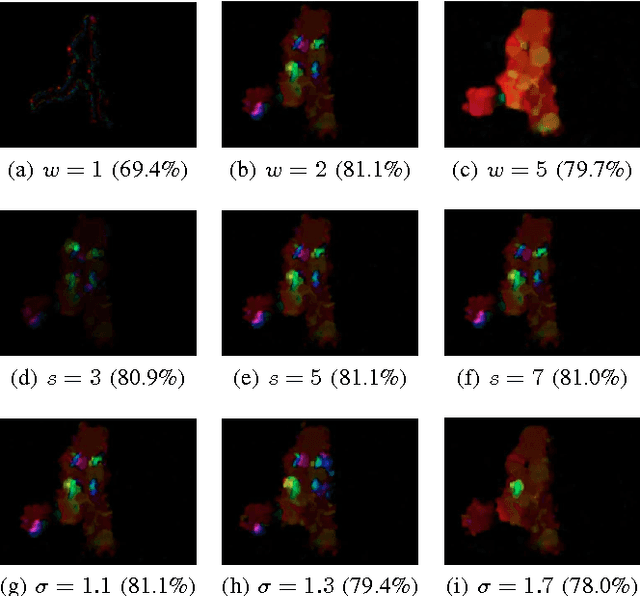

This paper proposes combining spatio-temporal appearance (STA) descriptors with optical flow for human action recognition. The STA descriptors are local histogram-based descriptors of space-time, suitable for building a partial representation of arbitrary spatio-temporal phenomena. Because of the possibility of iterative refinement, they are interesting in the context of online human action recognition. We investigate the use of dense optical flow as the image function of the STA descriptor for human action recognition, using two different algorithms for computing the flow: the Farneb\"ack algorithm and the TVL1 algorithm. We provide a detailed analysis of the influencing optical flow algorithm parameters on the produced optical flow fields. An extensive experimental validation of optical flow-based STA descriptors in human action recognition is performed on the KTH human action dataset. The encouraging experimental results suggest the potential of our approach in online human action recognition.