 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Evaluating Explanation Utility for Human-AI Decision Making in NLP
Jul 03, 2024Is explainability a false promise? This debate has emerged from the insufficient evidence that explanations aid people in situations they are introduced for. More human-centered, application-grounded evaluations of explanations are needed to settle this. Yet, with no established guidelines for such studies in NLP, researchers accustomed to standardized proxy evaluations must discover appropriate measurements, tasks, datasets, and sensible models for human-AI teams in their studies. To help with this, we first review fitting existing metrics. We then establish requirements for datasets to be suitable for application-grounded evaluations. Among over 50 datasets available for explainability research in NLP, we find that 4 meet our criteria. By finetuning Flan-T5-3B, we demonstrate the importance of reassessing the state of the art to form and study human-AI teams. Finally, we present the exemplar studies of human-AI decision-making for one of the identified suitable tasks -- verifying the correctness of a legal claim given a contract.
Is My Model Using The Right Evidence? Systematic Probes for Examining Evidence-Based Tabular Reasoning
Aug 02, 2021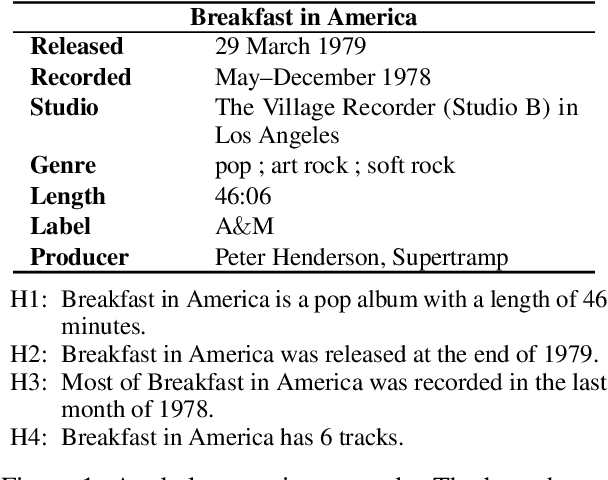
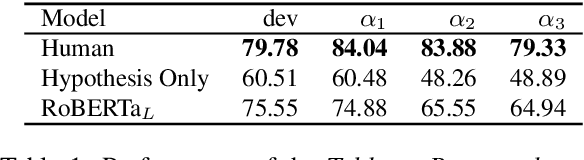
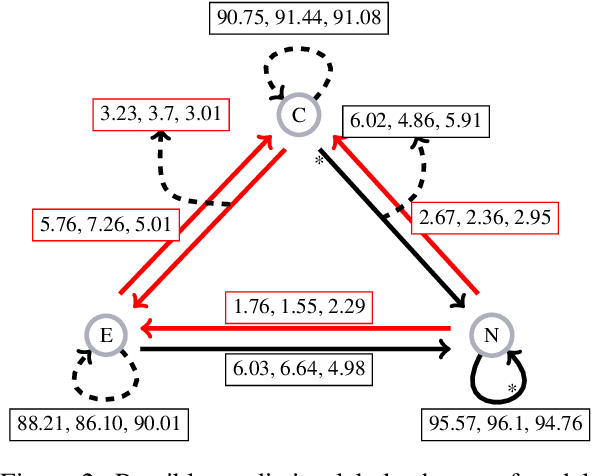
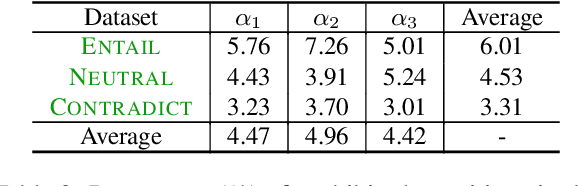
While neural models routinely report state-of-the-art performance across NLP tasks involving reasoning, their outputs are often observed to not properly use and reason on the evidence presented to them in the inputs. A model that reasons properly is expected to attend to the right parts of the input, be self-consistent in its predictions across examples, avoid spurious patterns in inputs, and to ignore biasing from its underlying pre-trained language model in a nuanced, context-sensitive fashion (e.g. handling counterfactuals). Do today's models do so? In this paper, we study this question using the problem of reasoning on tabular data. The tabular nature of the input is particularly suited for the study as it admits systematic probes targeting the properties listed above. Our experiments demonstrate that a BERT-based model representative of today's state-of-the-art fails to properly reason on the following counts: it often (a) misses the relevant evidence, (b) suffers from hypothesis and knowledge biases, and, (c) relies on annotation artifacts and knowledge from pre-trained language models as primary evidence rather than relying on reasoning on the premises in the tabular input.