 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNMM-HRI: Natural Multi-modal Human-Robot Interaction with Voice and Deictic Posture via Large Language Model
Jan 01, 2025



Translating human intent into robot commands is crucial for the future of service robots in an aging society. Existing Human-Robot Interaction (HRI) systems relying on gestures or verbal commands are impractical for the elderly due to difficulties with complex syntax or sign language. To address the challenge, this paper introduces a multi-modal interaction framework that combines voice and deictic posture information to create a more natural HRI system. The visual cues are first processed by the object detection model to gain a global understanding of the environment, and then bounding boxes are estimated based on depth information. By using a large language model (LLM) with voice-to-text commands and temporally aligned selected bounding boxes, robot action sequences can be generated, while key control syntax constraints are applied to avoid potential LLM hallucination issues. The system is evaluated on real-world tasks with varying levels of complexity using a Universal Robots UR3e manipulator. Our method demonstrates significantly better performance in HRI in terms of accuracy and robustness. To benefit the research community and the general public, we will make our code and design open-source.
Methodology to analyze the accuracy of 3D objects reconstructed with collaborative robot based monocular LSD-SLAM
Mar 06, 2018


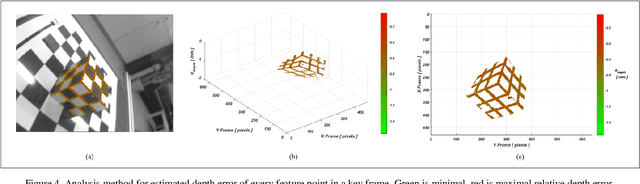
SLAM systems are mainly applied for robot navigation while research on feasibility for motion planning with SLAM for tasks like bin-picking, is scarce. Accurate 3D reconstruction of objects and environments is important for planning motion and computing optimal gripper pose to grasp objects. In this work, we propose the methods to analyze the accuracy of a 3D environment reconstructed using a LSD-SLAM system with a monocular camera mounted onto the gripper of a collaborative robot. We discuss and propose a solution to the pose space conversion problem. Finally, we present several criteria to analyze the 3D reconstruction accuracy. These could be used as guidelines to improve the accuracy of 3D reconstructions with monocular LSD-SLAM and other SLAM based solutions.