 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMIGO: Agentic Multi-Image Grounding Oracle Benchmark
Mar 30, 2026Agentic vision-language models increasingly act through extended interactions, but most evaluations still focus on single-image, single-turn correctness. We introduce AMIGO (Agentic Multi-Image Grounding Oracle Benchmark), a long-horizon benchmark for hidden-target identification over galleries of visually similar images. In AMIGO, the oracle privately selects a target image, and the model must recover it by asking a sequence of attribute-focused Yes/No/Unsure questions under a strict protocol that penalizes invalid actions with Skip. This setting stresses (i) question selection under uncertainty, (ii) consistent constraint tracking across turns, and (iii) fine-grained discrimination as evidence accumulates. AMIGO also supports controlled oracle imperfections to probe robustness and verification behavior under inconsistent feedback. We instantiate AMIGO with Guess My Preferred Dress task and report metrics covering both outcomes and interaction quality, including identification success, evidence verification, efficiency, protocol compliance, noise tolerance, and trajectory-level diagnostics.
FashionVQA: A Domain-Specific Visual Question Answering System
Aug 24, 2022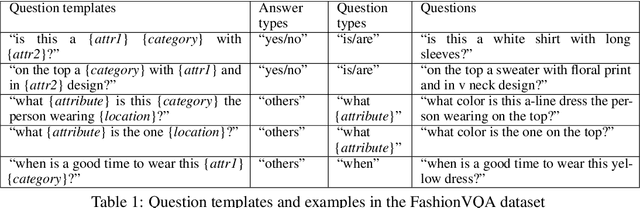
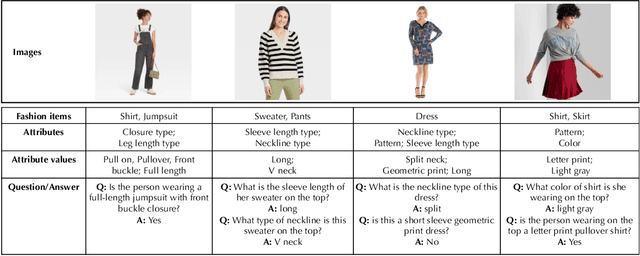
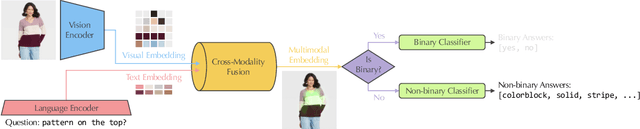
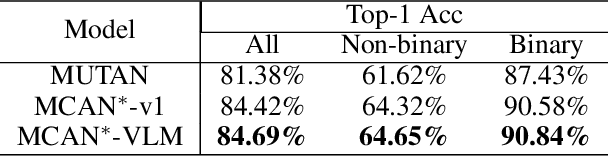
Humans apprehend the world through various sensory modalities, yet language is their predominant communication channel. Machine learning systems need to draw on the same multimodal richness to have informed discourses with humans in natural language; this is particularly true for systems specialized in visually-dense information, such as dialogue, recommendation, and search engines for clothing. To this end, we train a visual question answering (VQA) system to answer complex natural language questions about apparel in fashion photoshoot images. The key to the successful training of our VQA model is the automatic creation of a visual question-answering dataset with 168 million samples from item attributes of 207 thousand images using diverse templates. The sample generation employs a strategy that considers the difficulty of the question-answer pairs to emphasize challenging concepts. Contrary to the recent trends in using several datasets for pretraining the visual question answering models, we focused on keeping the dataset fixed while training various models from scratch to isolate the improvements from model architecture changes. We see that using the same transformer for encoding the question and decoding the answer, as in language models, achieves maximum accuracy, showing that visual language models (VLMs) make the best visual question answering systems for our dataset. The accuracy of the best model surpasses the human expert level, even when answering human-generated questions that are not confined to the template formats. Our approach for generating a large-scale multimodal domain-specific dataset provides a path for training specialized models capable of communicating in natural language. The training of such domain-expert models, e.g., our fashion VLM model, cannot rely solely on the large-scale general-purpose datasets collected from the web.
Designing an Efficient End-to-end Machine Learning Pipeline for Real-time Empty-shelf Detection
May 28, 2022
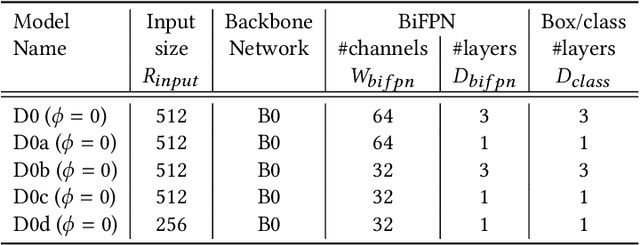
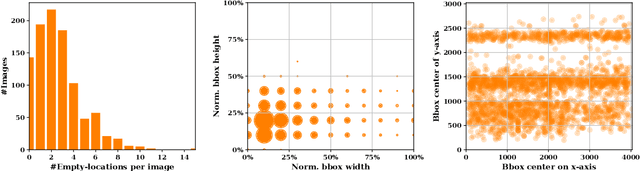
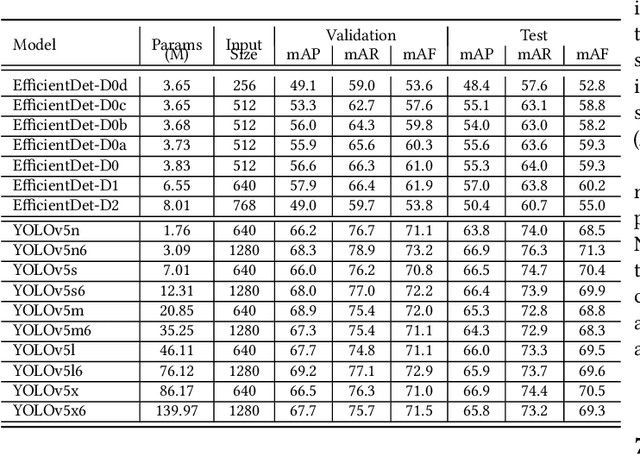
On-Shelf Availability (OSA) of products in retail stores is a critical business criterion in the fast moving consumer goods and retails sector. When a product is out-of-stock (OOS) and a customer cannot find it on its designed shelf, this motivates the customer to store-switching or buying nothing, which causes fall in future sales and demands. Retailers are employing several approaches to detect empty shelves and ensure high OSA of products; however, such methods are generally ineffective and infeasible since they are either manual, expensive or less accurate. Recently machine learning based solutions have been proposed, but they suffer from high computational cost and low accuracy problem due to lack of large annotated datasets of on-shelf products. Here, we present an elegant approach for designing an end-to-end machine learning (ML) pipeline for real-time empty shelf detection. Considering the strong dependency between the quality of ML models and the quality of data, we focus on the importance of proper data collection, cleaning and correct data annotation before delving into modeling. Since an empty-shelf detection solution should be computationally-efficient for real-time predictions, we explore different run-time optimizations to improve the model performance. Our dataset contains 1000 images, collected and annotated by following well-defined guidelines. Our low-latency model achieves a mean average F1-score of 68.5%, and can process up to 67 images/s on Intel Xeon Gold and up to 860 images/s on an A100 GPU.
Neuromorphic Computing for Content-based Image Retrieval
Aug 04, 2020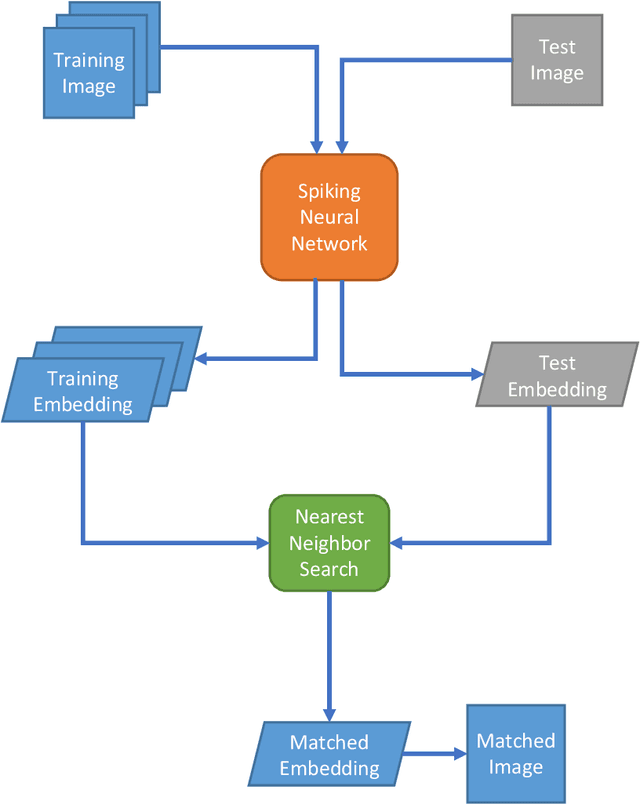
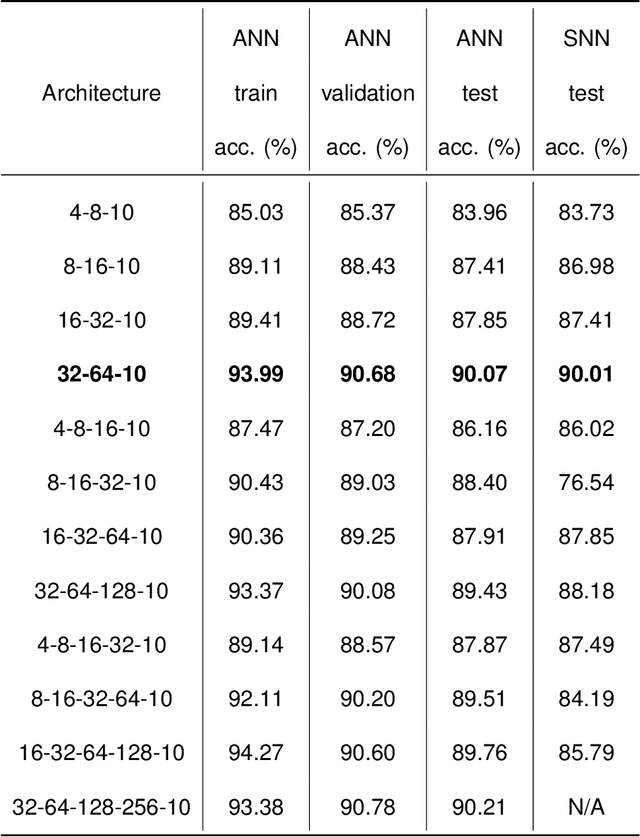
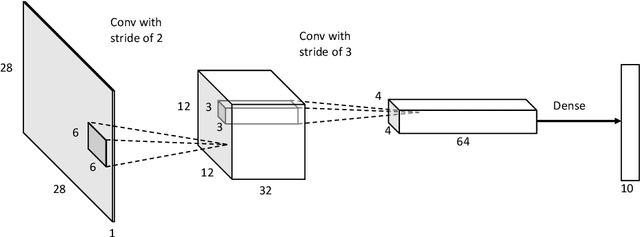
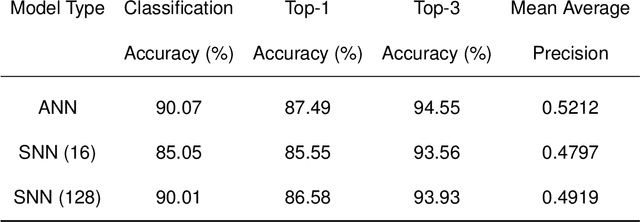
Neuromorphic computing mimics the neural activity of the brain through emulating spiking neural networks. In numerous machine learning tasks, neuromorphic chips are expected to provide superior solutions in terms of cost and power efficiency. Here, we explore the application of Loihi, a neuromorphic computing chip developed by Intel, for the computer vision task of image retrieval. We evaluated the functionalities and the performance metrics that are critical in context-based visual search and recommender systems using deep-learning embeddings. Our results show that the neuromorphic solution is about 3.2 times more energy-efficient compared with an Intel Core i7 CPU and 12.5 times more energy-efficient compared with Nvidia T4 GPU for inference by a lightweight convolutional neural network without batching, while maintaining the same level of matching accuracy. The study validates the longterm potential of neuromorphic computing in machine learning, as a complementary paradigm to the existing Von Neumann architectures.
Deep Cytometry
Apr 09, 2019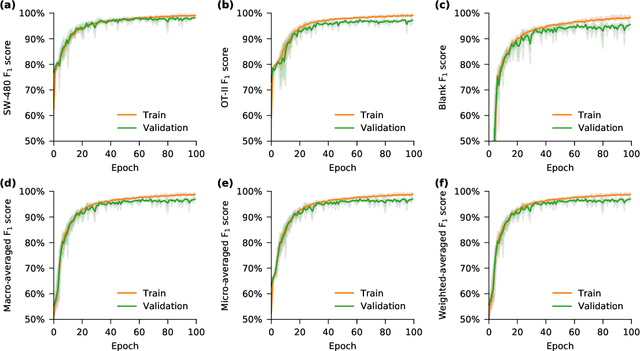
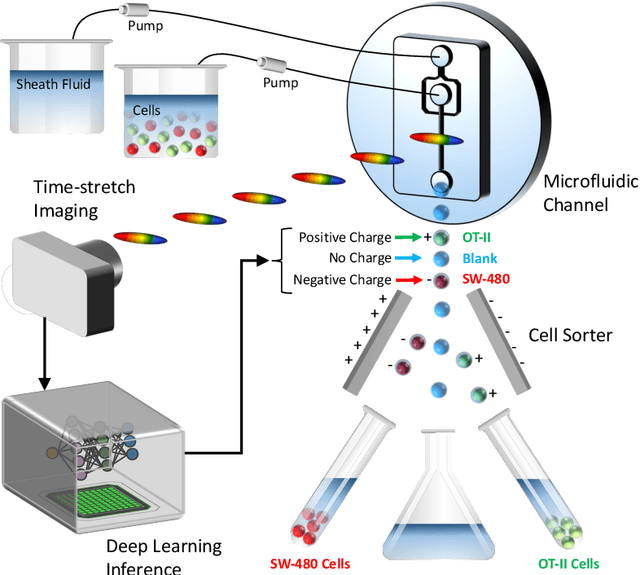
Deep learning has achieved spectacular performance in image and speech recognition and synthesis. It outperforms other machine learning algorithms in problems where large amounts of data are available. In the area of measurement technology, instruments based on the Photonic Time Stretch have established record real-time measurement throughput in spectroscopy, optical coherence tomography, and imaging flow cytometry. These extreme-throughput instruments generate approximately 1 Tbit/s of continuous measurement data and have led to the discovery of rare phenomena in nonlinear and complex systems as well as new types of biomedical instruments. Owing to the abundance of data they generate, time stretch instruments are a natural fit to deep learning classification. Previously we had shown that high-throughput label-free cell classification with high accuracy can be achieved through a combination of time stretch microscopy, image processing and feature extraction, followed by deep learning for finding cancer cells in the blood. Such a technology holds promise for early detection of primary cancer or metastasis. Here we describe a new implementation of deep learning which entirely avoids the computationally costly image processing and feature extraction pipeline. The improvement in computational efficiency makes this new technology suitable for cell sorting via deep learning. Our neural network takes less than a millisecond to classify the cells, fast enough to provide a decision to a cell sorter. We demonstrate the applicability of our new method in the classification of OT-II white blood cells and SW-480 epithelial cancer cells with more than 95\% accuracy in a label-free fashion.
Time Stretch Inspired Computational Imaging
Jun 07, 2017
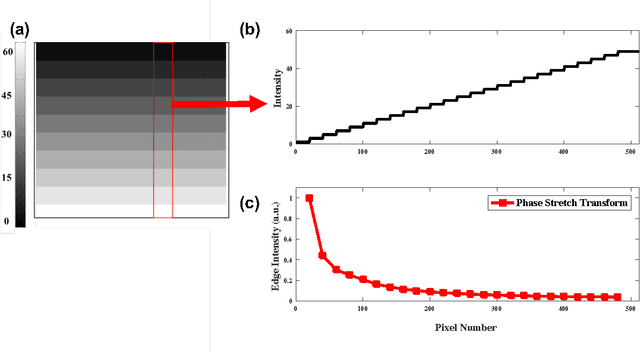


We show that dispersive propagation of light followed by phase detection has properties that can be exploited for extracting features from the waveforms. This discovery is spearheading development of a new class of physics-inspired algorithms for feature extraction from digital images with unique properties and superior dynamic range compared to conventional algorithms. In certain cases, these algorithms have the potential to be an energy efficient and scalable substitute to synthetically fashioned computational techniques in practice today.