 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashionVQA: A Domain-Specific Visual Question Answering System
Aug 24, 2022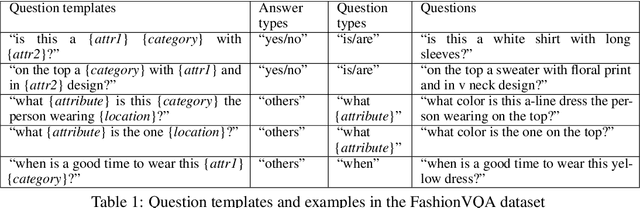
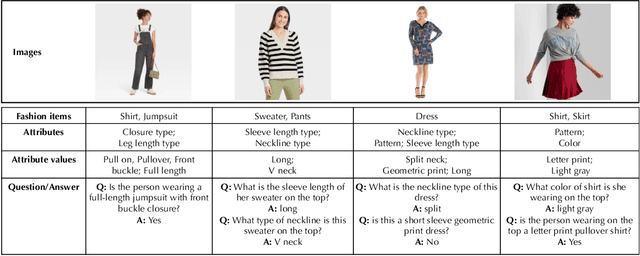
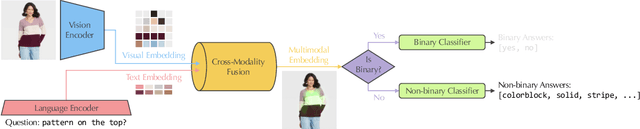
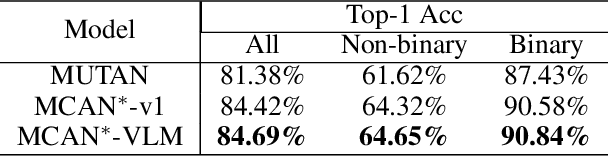
Humans apprehend the world through various sensory modalities, yet language is their predominant communication channel. Machine learning systems need to draw on the same multimodal richness to have informed discourses with humans in natural language; this is particularly true for systems specialized in visually-dense information, such as dialogue, recommendation, and search engines for clothing. To this end, we train a visual question answering (VQA) system to answer complex natural language questions about apparel in fashion photoshoot images. The key to the successful training of our VQA model is the automatic creation of a visual question-answering dataset with 168 million samples from item attributes of 207 thousand images using diverse templates. The sample generation employs a strategy that considers the difficulty of the question-answer pairs to emphasize challenging concepts. Contrary to the recent trends in using several datasets for pretraining the visual question answering models, we focused on keeping the dataset fixed while training various models from scratch to isolate the improvements from model architecture changes. We see that using the same transformer for encoding the question and decoding the answer, as in language models, achieves maximum accuracy, showing that visual language models (VLMs) make the best visual question answering systems for our dataset. The accuracy of the best model surpasses the human expert level, even when answering human-generated questions that are not confined to the template formats. Our approach for generating a large-scale multimodal domain-specific dataset provides a path for training specialized models capable of communicating in natural language. The training of such domain-expert models, e.g., our fashion VLM model, cannot rely solely on the large-scale general-purpose datasets collected from the web.
Designing an Efficient End-to-end Machine Learning Pipeline for Real-time Empty-shelf Detection
May 28, 2022
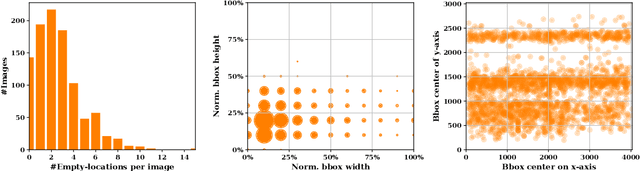
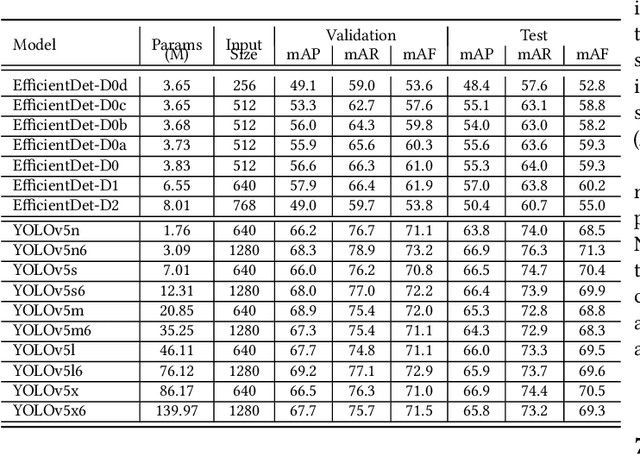
On-Shelf Availability (OSA) of products in retail stores is a critical business criterion in the fast moving consumer goods and retails sector. When a product is out-of-stock (OOS) and a customer cannot find it on its designed shelf, this motivates the customer to store-switching or buying nothing, which causes fall in future sales and demands. Retailers are employing several approaches to detect empty shelves and ensure high OSA of products; however, such methods are generally ineffective and infeasible since they are either manual, expensive or less accurate. Recently machine learning based solutions have been proposed, but they suffer from high computational cost and low accuracy problem due to lack of large annotated datasets of on-shelf products. Here, we present an elegant approach for designing an end-to-end machine learning (ML) pipeline for real-time empty shelf detection. Considering the strong dependency between the quality of ML models and the quality of data, we focus on the importance of proper data collection, cleaning and correct data annotation before delving into modeling. Since an empty-shelf detection solution should be computationally-efficient for real-time predictions, we explore different run-time optimizations to improve the model performance. Our dataset contains 1000 images, collected and annotated by following well-defined guidelines. Our low-latency model achieves a mean average F1-score of 68.5%, and can process up to 67 images/s on Intel Xeon Gold and up to 860 images/s on an A100 GPU.