 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying text using machine learning models and determining conversation drift
Nov 15, 2022



Text classification helps analyse texts for semantic meaning and relevance, by mapping the words against this hierarchy. An analysis of various types of texts is invaluable to understanding both their semantic meaning, as well as their relevance. Text classification is a method of categorising documents. It combines computer text classification and natural language processing to analyse text in aggregate. This method provides a descriptive categorization of the text, with features like content type, object field, lexical characteristics, and style traits. In this research, the authors aim to use natural language feature extraction methods in machine learning which are then used to train some of the basic machine learning models like Naive Bayes, Logistic Regression, and Support Vector Machine. These models are used to detect when a teacher must get involved in a discussion when the lines go off-topic.
Machine Learning enabled models for YouTube Ranking Mechanism and Views Prediction
Nov 15, 2022



With the continuous increase of internet usage in todays time, everyone is influenced by this source of the power of technology. Due to this, the rise of applications and games Is unstoppable. A major percentage of our population uses these applications for multiple purposes. These range from education, communication, news, entertainment, and many more. Out of this, the application that is making sure that the world stays in touch with each other and with current affairs is social media. Social media applications have seen a boom in the last 10 years with the introduction of smartphones and the internet being available at affordable prices. Applications like Twitch and Youtube are some of the best platforms for producing content and expressing their talent as well. It is the goal of every content creator to post the best and most reliable content so that they can gain recognition. It is important to know the methods of achieving popularity easily, which is what this paper proposes to bring to the spotlight. There should be certain parameters based on which the reach of content could be multiplied by a good factor. The proposed research work aims to identify and estimate the reach, popularity, and views of a YouTube video by using certain features using machine learning and AI techniques. A ranking system would also be used keeping the trending videos in consideration. This would eventually help the content creator know how authentic their content is and healthy competition to make better content before uploading the video on the platform will be ensured.
BloomNet: A Robust Transformer based model for Bloom's Learning Outcome Classification
Aug 16, 2021
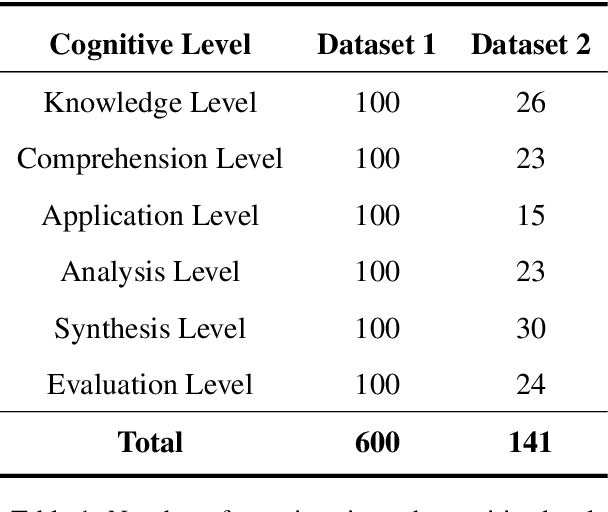
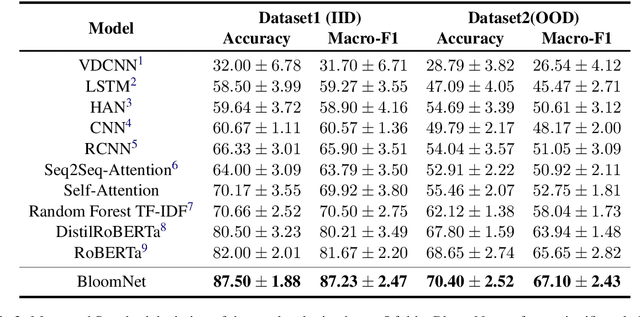
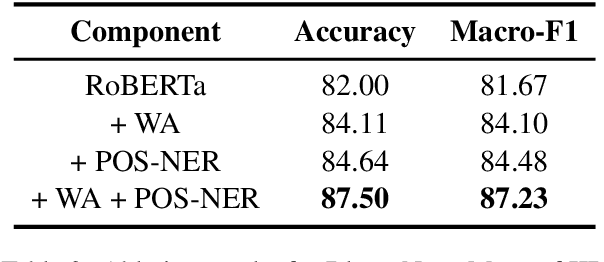
Bloom taxonomy is a common paradigm for categorizing educational learning objectives into three learning levels: cognitive, affective, and psychomotor. For the optimization of educational programs, it is crucial to design course learning outcomes (CLOs) according to the different cognitive levels of Bloom Taxonomy. Usually, administrators of the institutions manually complete the tedious work of mapping CLOs and examination questions to Bloom taxonomy levels. To address this issue, we propose a transformer-based model named BloomNet that captures linguistic as well semantic information to classify the course learning outcomes (CLOs). We compare BloomNet with a diverse set of basic as well as strong baselines and we observe that our model performs better than all the experimented baselines. Further, we also test the generalization capability of BloomNet by evaluating it on different distributions which our model does not encounter during training and we observe that our model is less susceptible to distribution shift compared to the other considered models. We support our findings by performing extensive result analysis. In ablation study we observe that on explicitly encapsulating the linguistic information along with semantic information improves the model on IID (independent and identically distributed) performance as well as OOD (out-of-distribution) generalization capability.
CovidGAN: Data Augmentation Using Auxiliary Classifier GAN for Improved Covid-19 Detection
Mar 08, 2021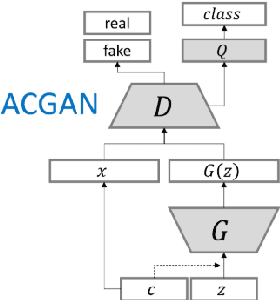
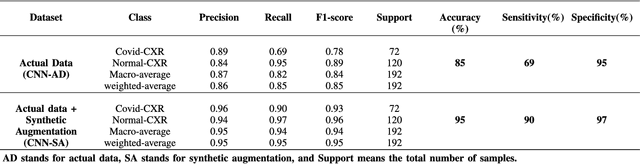
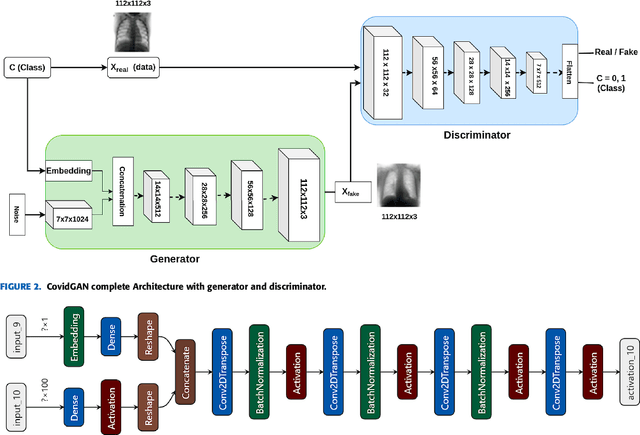
Coronavirus (COVID-19) is a viral disease caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). The spread of COVID-19 seems to have a detrimental effect on the global economy and health. A positive chest X-ray of infected patients is a crucial step in the battle against COVID-19. Early results suggest that abnormalities exist in chest X-rays of patients suggestive of COVID-19. This has led to the introduction of a variety of deep learning systems and studies have shown that the accuracy of COVID-19 patient detection through the use of chest X-rays is strongly optimistic. Deep learning networks like convolutional neural networks (CNNs) need a substantial amount of training data. Because the outbreak is recent, it is difficult to gather a significant number of radiographic images in such a short time. Therefore, in this research, we present a method to generate synthetic chest X-ray (CXR) images by developing an Auxiliary Classifier Generative Adversarial Network (ACGAN) based model called CovidGAN. In addition, we demonstrate that the synthetic images produced from CovidGAN can be utilized to enhance the performance of CNN for COVID-19 detection. Classification using CNN alone yielded 85% accuracy. By adding synthetic images produced by CovidGAN, the accuracy increased to 95%. We hope this method will speed up COVID-19 detection and lead to more robust systems of radiology.
* Accepted at IEEE Access. Received April 30, 2020, accepted May 11, 2020, date of publication May 14, 2020, date of current version May 28, 2020
Hiding Data in Images Using Cryptography and Deep Neural Network
Dec 22, 2019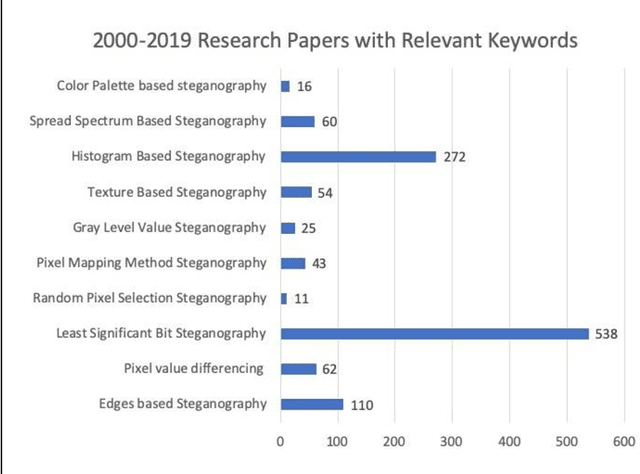

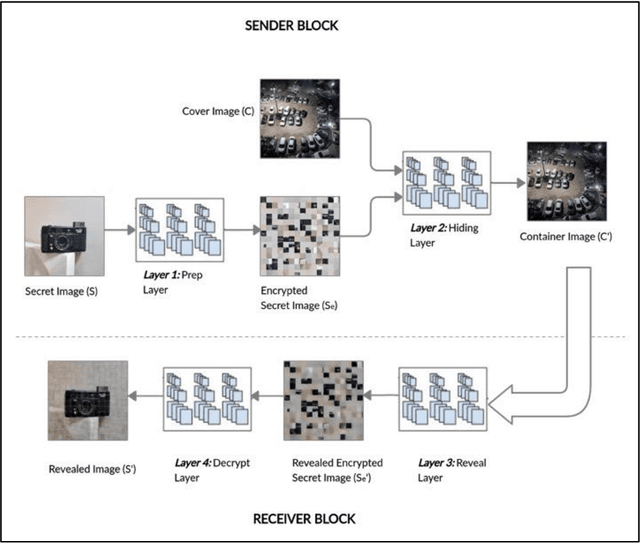
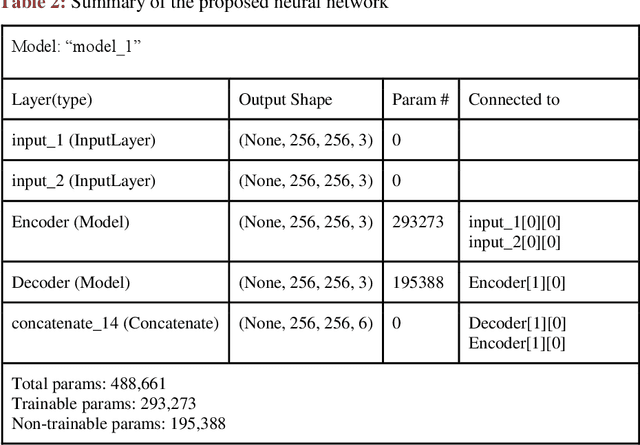
Steganography is an art of obscuring data inside another quotidian file of similar or varying types. Hiding data has always been of significant importance to digital forensics. Previously, steganography has been combined with cryptography and neural networks separately. Whereas, this research combines steganography, cryptography with the neural networks all together to hide an image inside another container image of the larger or same size. Although the cryptographic technique used is quite simple, but is effective when convoluted with deep neural nets. Other steganography techniques involve hiding data efficiently, but in a uniform pattern which makes it less secure. This method targets both the challenges and make data hiding secure and non-uniform.