 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeμSplit: efficient image decomposition for microscopy data
Nov 23, 2022



Light microscopy is routinely used to look at living cells and biological tissues at sub-cellular resolution. Components of the imaged cells can be highlighted using fluorescent labels, allowing biologists to investigate individual structures of interest. Given the complexity of biological processes, it is typically necessary to look at multiple structures simultaneously, typically via a temporal multiplexing scheme. Still, imaging more than 3 or 4 structures in this way is difficult for technical reasons and limits the rate of scientific progress in the life sciences. Hence, a computational method to split apart (decompose) superimposed biological structures acquired in a single image channel, i.e. without temporal multiplexing, would have tremendous impact. Here we present {\mu}Split, a dedicated approach for trained image decomposition. We find that best results using regular deep architectures is achieved when large image patches are used during training, making memory consumption the limiting factor to further improving performance. We therefore introduce lateral contextualization (LC), a memory efficient way to train deep networks that operate well on small input patches. In later layers, additional image context is fed at adequately lowered resolution. We integrate LC with Hierarchical Autoencoders and Hierarchical VAEs.For the latter, we also present a modified ELBO loss and show that it enables sound VAE training. We apply {\mu}Split to five decomposition tasks, one on a synthetic dataset, four others derived from two real microscopy datasets. LC consistently achieves SOTA results, while simultaneously requiring considerably less GPU memory than competing architectures not using LC. When introducing LC, results obtained with the above-mentioned vanilla architectures do on average improve by 2.36 dB (PSNR decibel), with individual improvements ranging from 0.9 to 3.4 dB.
Accurate and Clear Precipitation Nowcasting with Consecutive Attention and Rain-map Discrimination
Feb 16, 2021
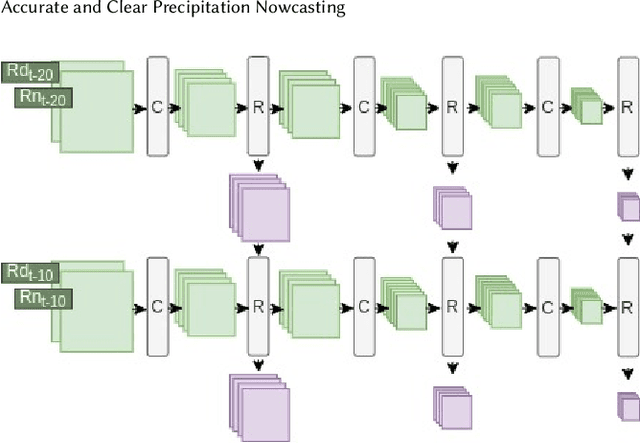
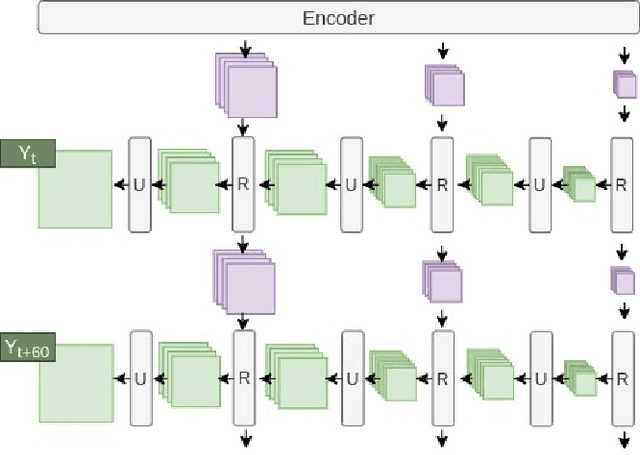
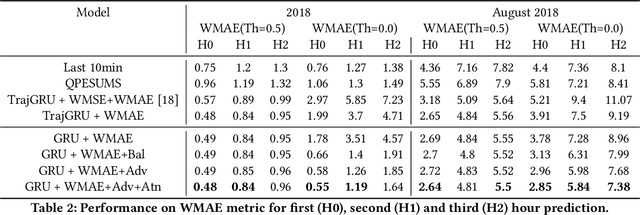
Precipitation nowcasting is an important task for weather forecasting. Many recent works aim to predict the high rainfall events more accurately with the help of deep learning techniques, but such events are relatively rare. The rarity is often addressed by formulations that re-weight the rare events. Somehow such a formulation carries a side effect of making "blurry" predictions in low rainfall regions and cannot convince meteorologists to trust its practical usability. We fix the trust issue by introducing a discriminator that encourages the prediction model to generate realistic rain-maps without sacrificing predictive accuracy. Furthermore, we extend the nowcasting time frame from one hour to three hours to further address the needs from meteorologists. The extension is based on consecutive attentions across different hours. We propose a new deep learning model for precipitation nowcasting that includes both the discrimination and attention techniques. The model is examined on a newly-built benchmark dataset that contains both radar data and actual rain data. The benchmark, which will be publicly released, not only establishes the superiority of the proposed model, but also is expected to encourage future research on precipitation nowcasting.