 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReportAGE: Automatically extracting the exact age of Twitter users based on self-reports in tweets
Mar 10, 2021


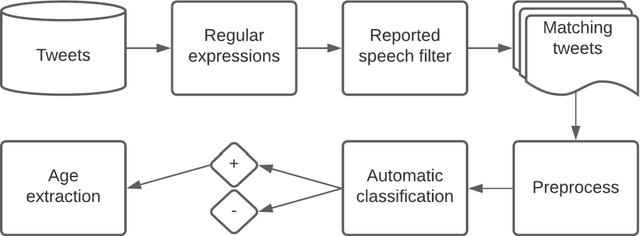
Advancing the utility of social media data for research applications requires methods for automatically detecting demographic information about social media study populations, including users' age. The objective of this study was to develop and evaluate a method that automatically identifies the exact age of users based on self-reports in their tweets. Our end-to-end automatic natural language processing (NLP) pipeline, ReportAGE, includes query patterns to retrieve tweets that potentially mention an age, a classifier to distinguish retrieved tweets that self-report the user's exact age ("age" tweets) and those that do not ("no age" tweets), and rule-based extraction to identify the age. To develop and evaluate ReportAGE, we manually annotated 11,000 tweets that matched the query patterns. Based on 1000 tweets that were annotated by all five annotators, inter-annotator agreement (Fleiss' kappa) was 0.80 for distinguishing "age" and "no age" tweets, and 0.95 for identifying the exact age among the "age" tweets on which the annotators agreed. A deep neural network classifier, based on a RoBERTa-Large pretrained model, achieved the highest F1-score of 0.914 (precision = 0.905, recall = 0.942) for the "age" class. When the age extraction was evaluated using the classifier's predictions, it achieved an F1-score of 0.855 (precision = 0.805, recall = 0.914) for the "age" class. When it was evaluated directly on the held-out test set, it achieved an F1-score of 0.931 (precision = 0.873, recall = 0.998) for the "age" class. We deployed ReportAGE on more than 1.2 billion tweets posted by 245,927 users, and predicted ages for 132,637 (54%) of them. Scaling the detection of exact age to this large number of users can advance the utility of social media data for research applications that do not align with the predefined age groupings of extant binary or multi-class classification approaches.
Social media mining for identification and exploration of health-related information from pregnant women
Feb 08, 2017
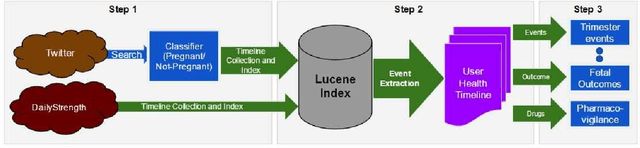

Widespread use of social media has led to the generation of substantial amounts of information about individuals, including health-related information. Social media provides the opportunity to study health-related information about selected population groups who may be of interest for a particular study. In this paper, we explore the possibility of utilizing social media to perform targeted data collection and analysis from a particular population group -- pregnant women. We hypothesize that we can use social media to identify cohorts of pregnant women and follow them over time to analyze crucial health-related information. To identify potentially pregnant women, we employ simple rule-based searches that attempt to detect pregnancy announcements with moderate precision. To further filter out false positives and noise, we employ a supervised classifier using a small number of hand-annotated data. We then collect their posts over time to create longitudinal health timelines and attempt to divide the timelines into different pregnancy trimesters. Finally, we assess the usefulness of the timelines by performing a preliminary analysis to estimate drug intake patterns of our cohort at different trimesters. Our rule-based cohort identification technique collected 53,820 users over thirty months from Twitter. Our pregnancy announcement classification technique achieved an F-measure of 0.81 for the pregnancy class, resulting in 34,895 user timelines. Analysis of the timelines revealed that pertinent health-related information, such as drug-intake and adverse reactions can be mined from the data. Our approach to using user timelines in this fashion has produced very encouraging results and can be employed for other important tasks where cohorts, for which health-related information may not be available from other sources, are required to be followed over time to derive population-based estimates.