 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReportAGE: Automatically extracting the exact age of Twitter users based on self-reports in tweets
Mar 10, 2021


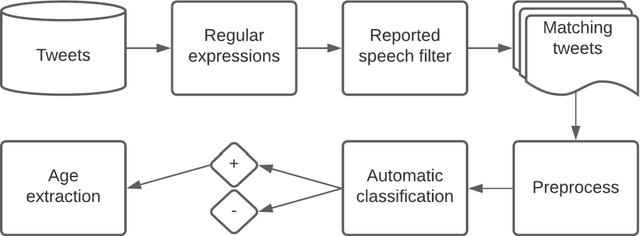
Advancing the utility of social media data for research applications requires methods for automatically detecting demographic information about social media study populations, including users' age. The objective of this study was to develop and evaluate a method that automatically identifies the exact age of users based on self-reports in their tweets. Our end-to-end automatic natural language processing (NLP) pipeline, ReportAGE, includes query patterns to retrieve tweets that potentially mention an age, a classifier to distinguish retrieved tweets that self-report the user's exact age ("age" tweets) and those that do not ("no age" tweets), and rule-based extraction to identify the age. To develop and evaluate ReportAGE, we manually annotated 11,000 tweets that matched the query patterns. Based on 1000 tweets that were annotated by all five annotators, inter-annotator agreement (Fleiss' kappa) was 0.80 for distinguishing "age" and "no age" tweets, and 0.95 for identifying the exact age among the "age" tweets on which the annotators agreed. A deep neural network classifier, based on a RoBERTa-Large pretrained model, achieved the highest F1-score of 0.914 (precision = 0.905, recall = 0.942) for the "age" class. When the age extraction was evaluated using the classifier's predictions, it achieved an F1-score of 0.855 (precision = 0.805, recall = 0.914) for the "age" class. When it was evaluated directly on the held-out test set, it achieved an F1-score of 0.931 (precision = 0.873, recall = 0.998) for the "age" class. We deployed ReportAGE on more than 1.2 billion tweets posted by 245,927 users, and predicted ages for 132,637 (54%) of them. Scaling the detection of exact age to this large number of users can advance the utility of social media data for research applications that do not align with the predefined age groupings of extant binary or multi-class classification approaches.
Towards Automatic Bot Detection in Twitter for Health-related Tasks
Sep 29, 2019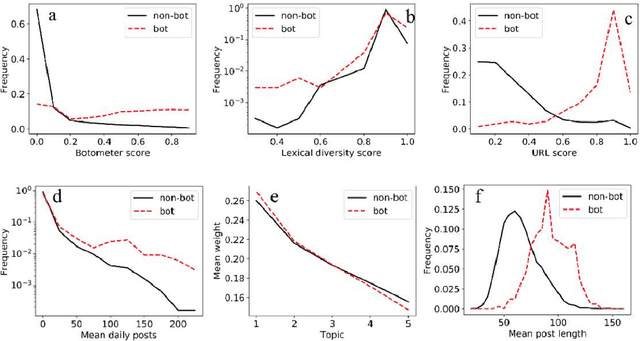

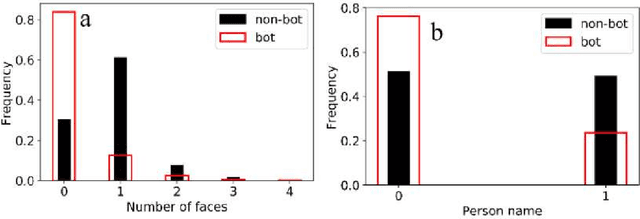
With the increasing use of social media data for health-related research, the credibility of the information from this source has been questioned as the posts may originate from automated accounts or "bots". While automatic bot detection approaches have been proposed, there are none that have been evaluated on users posting health-related information. In this paper, we extend an existing bot detection system and customize it for health-related research. Using a dataset of Twitter users, we first show that the system, which was designed for political bot detection, underperforms when applied to health-related Twitter users. We then incorporate additional features and a statistical machine learning classifier to significantly improve bot detection performance. Our approach obtains F_1 scores of 0.7 for the "bot" class, representing improvements of 0.339. Our approach is customizable and generalizable for bot detection in other health-related social media cohorts.
Automatically Identifying Comparator Groups on Twitter for Digital Epidemiology of Pregnancy Outcomes
Aug 16, 2019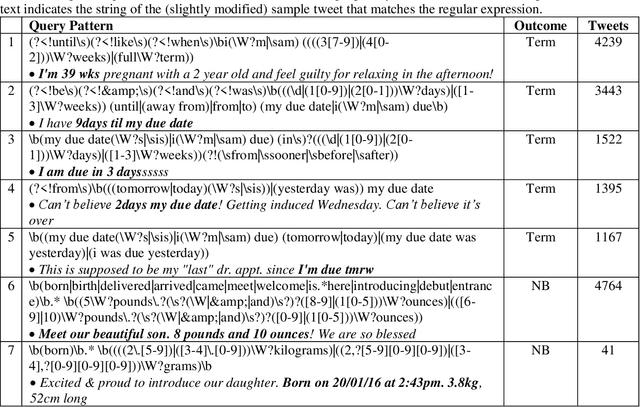
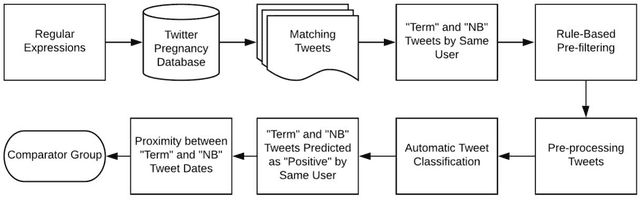

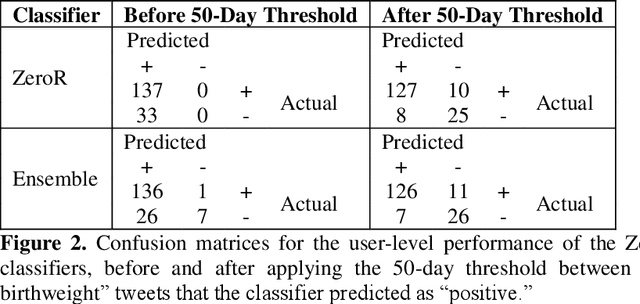
Despite the prevalence of adverse pregnancy outcomes such as miscarriage, stillbirth, birth defects, and preterm birth, their causes are largely unknown. We seek to advance the use of social media for observational studies of pregnancy outcomes by developing a natural language processing pipeline for automatically identifying users from which to select comparator groups on Twitter. We annotated 2361 tweets by users who have announced their pregnancy on Twitter, which were used to train and evaluate supervised machine learning algorithms as a basis for automatically detecting women who have reported that their pregnancy had reached term and their baby was born at a normal weight. Upon further processing the tweet-level predictions of a majority voting-based ensemble classifier, the pipeline achieved a user-level F1-score of 0.933, with a precision of 0.947 and a recall of 0.920. Our pipeline will be deployed to identify large comparator groups for studying pregnancy outcomes on Twitter.
Automatically Detecting Self-Reported Birth Defect Outcomes on Twitter for Large-scale Epidemiological Research
Oct 22, 2018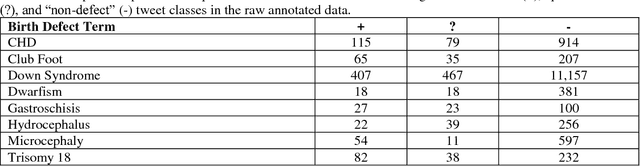
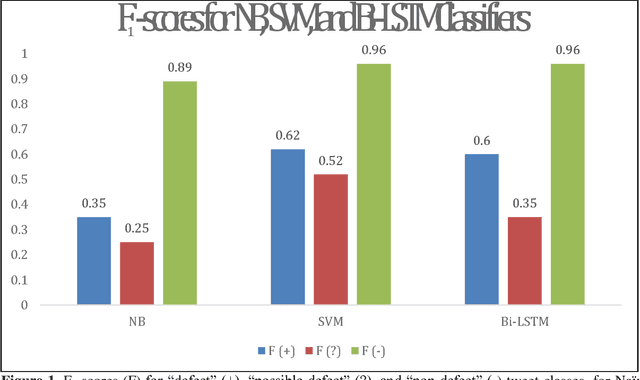
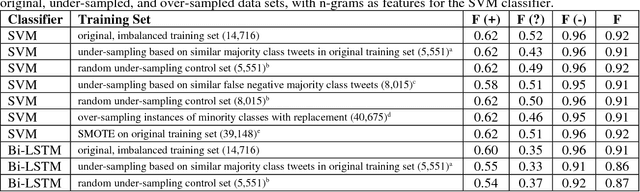
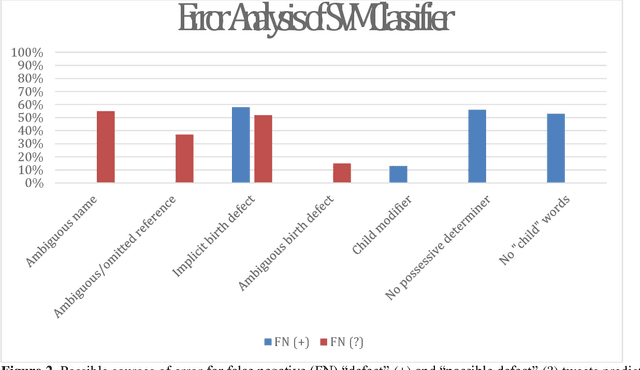
In recent work, we identified and studied a small cohort of Twitter users whose pregnancies with birth defect outcomes could be observed via their publicly available tweets. Exploiting social media's large-scale potential to complement the limited methods for studying birth defects, the leading cause of infant mortality, depends on the further development of automatic methods. The primary objective of this study was to take the first step towards scaling the use of social media for observing pregnancies with birth defect outcomes, namely, developing methods for automatically detecting tweets by users reporting their birth defect outcomes. We annotated and pre-processed approximately 23,000 tweets that mention birth defects in order to train and evaluate supervised machine learning algorithms, including feature-engineered and deep learning-based classifiers. We also experimented with various under-sampling and over-sampling approaches to address the class imbalance. A Support Vector Machine (SVM) classifier trained on the original, imbalanced data set, with n-grams, word clusters, and structural features, achieved the best baseline performance for the positive classes: an F1-score of 0.65 for the "defect" class and 0.51 for the "possible defect" class. Our contributions include (i) natural language processing (NLP) and supervised machine learning methods for automatically detecting tweets by users reporting their birth defect outcomes, (ii) a comparison of feature-engineered and deep learning-based classifiers trained on imbalanced, under-sampled, and over-sampled data, and (iii) an error analysis that could inform classification improvements using our publicly available corpus. Future work will focus on automating user-level analyses for cohort inclusion.