 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Detecting Self-Reported Birth Defect Outcomes on Twitter for Large-scale Epidemiological Research
Paper and Code
Oct 22, 2018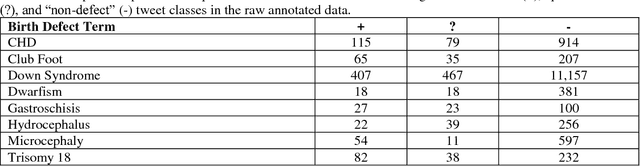
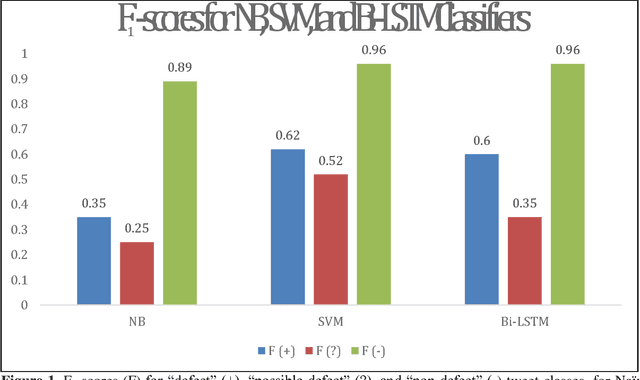
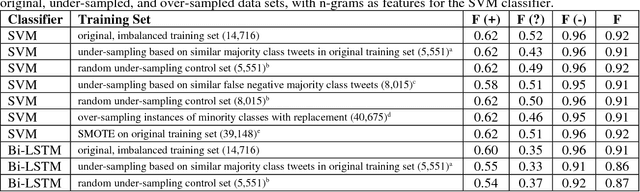
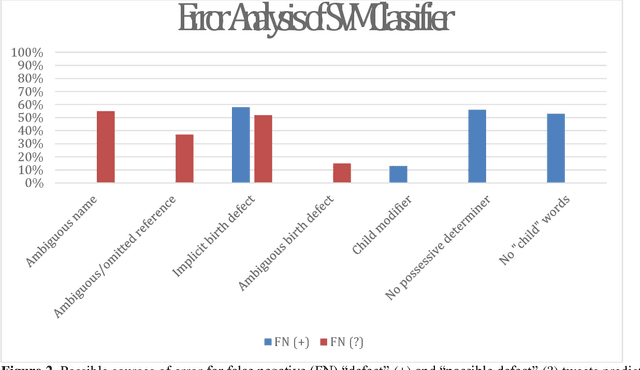
In recent work, we identified and studied a small cohort of Twitter users whose pregnancies with birth defect outcomes could be observed via their publicly available tweets. Exploiting social media's large-scale potential to complement the limited methods for studying birth defects, the leading cause of infant mortality, depends on the further development of automatic methods. The primary objective of this study was to take the first step towards scaling the use of social media for observing pregnancies with birth defect outcomes, namely, developing methods for automatically detecting tweets by users reporting their birth defect outcomes. We annotated and pre-processed approximately 23,000 tweets that mention birth defects in order to train and evaluate supervised machine learning algorithms, including feature-engineered and deep learning-based classifiers. We also experimented with various under-sampling and over-sampling approaches to address the class imbalance. A Support Vector Machine (SVM) classifier trained on the original, imbalanced data set, with n-grams, word clusters, and structural features, achieved the best baseline performance for the positive classes: an F1-score of 0.65 for the "defect" class and 0.51 for the "possible defect" class. Our contributions include (i) natural language processing (NLP) and supervised machine learning methods for automatically detecting tweets by users reporting their birth defect outcomes, (ii) a comparison of feature-engineered and deep learning-based classifiers trained on imbalanced, under-sampled, and over-sampled data, and (iii) an error analysis that could inform classification improvements using our publicly available corpus. Future work will focus on automating user-level analyses for cohort inclusion.