 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairRARI: A Plug and Play Framework for Fairness-Aware PageRank
Feb 09, 2026PageRank (PR) is a fundamental algorithm in graph machine learning tasks. Owing to the increasing importance of algorithmic fairness, we consider the problem of computing PR vectors subject to various group-fairness criteria based on sensitive attributes of the vertices. At present, principled algorithms for this problem are lacking - some cannot guarantee that a target fairness level is achieved, while others do not feature optimality guarantees. In order to overcome these shortcomings, we put forth a unified in-processing convex optimization framework, termed FairRARI, for tackling different group-fairness criteria in a ``plug and play'' fashion. Leveraging a variational formulation of PR, the framework computes fair PR vectors by solving a strongly convex optimization problem with fairness constraints, thereby ensuring that a target fairness level is achieved. We further introduce three different fairness criteria which can be efficiently tackled using FairRARI to compute fair PR vectors with the same asymptotic time-complexity as the original PR algorithm. Extensive experiments on real-world datasets showcase that FairRARI outperforms existing methods in terms of utility, while achieving the desired fairness levels across multiple vertex groups; thereby highlighting its effectiveness.
A Scalable and Exact Relaxation for Densest $k$-Subgraph via Error Bounds
Nov 17, 2025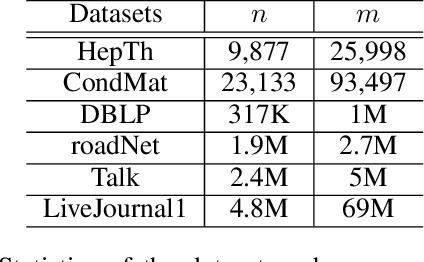
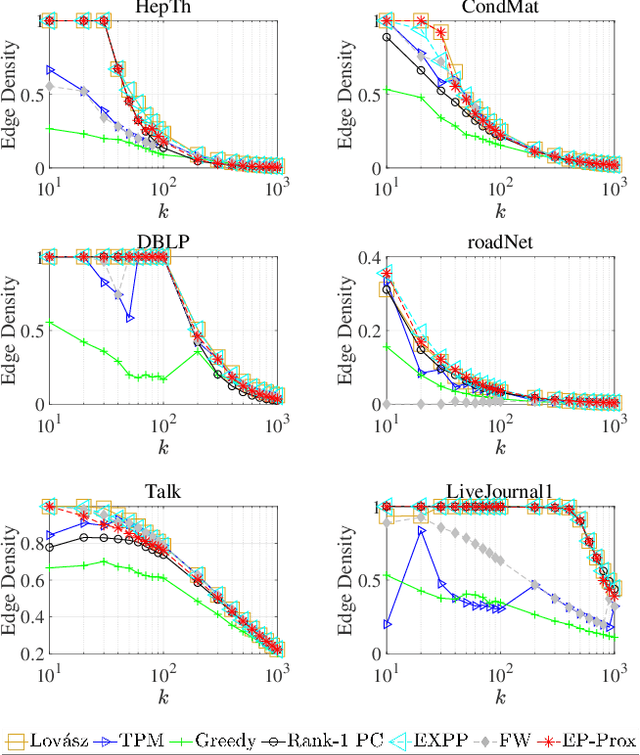
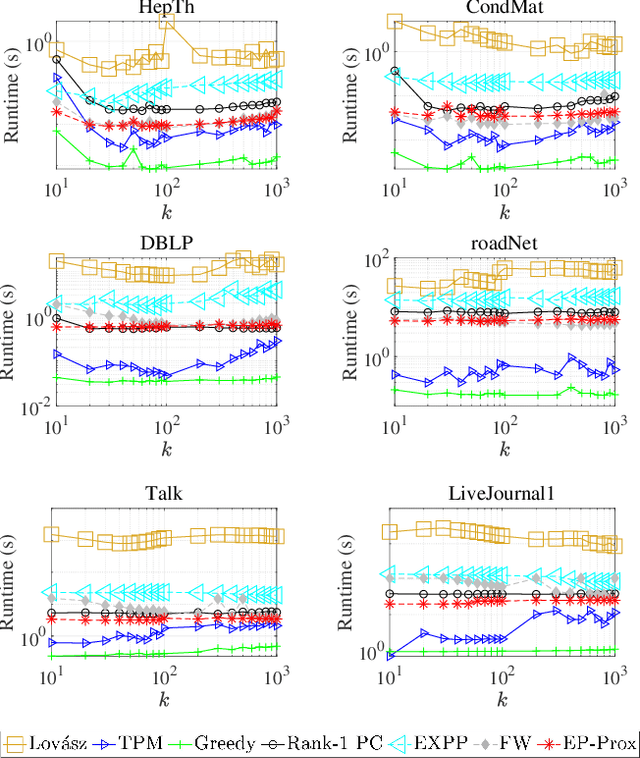
Given an undirected graph and a size parameter $k$, the Densest $k$-Subgraph (D$k$S) problem extracts the subgraph on $k$ vertices with the largest number of induced edges. While D$k$S is NP--hard and difficult to approximate, penalty-based continuous relaxations of the problem have recently enjoyed practical success for real-world instances of D$k$S. In this work, we propose a scalable and exact continuous penalization approach for D$k$S using the error bound principle, which enables the design of suitable penalty functions. Notably, we develop new theoretical guarantees ensuring that both the global and local optima of the penalized problem match those of the original problem. The proposed penalized reformulation enables the use of first-order continuous optimization methods. In particular, we develop a non-convex proximal gradient algorithm, where the non-convex proximal operator can be computed in closed form, resulting in low per-iteration complexity. We also provide convergence analysis of the algorithm. Experiments on large-scale instances of the D$k$S problem and one of its variants, the Densest ($k_1, k_2$) Bipartite Subgraph (D$k_1k_2$BS) problem, demonstrate that our method achieves a favorable balance between computation cost and solution quality.
Differentially Private Densest-$k$-Subgraph
May 06, 2025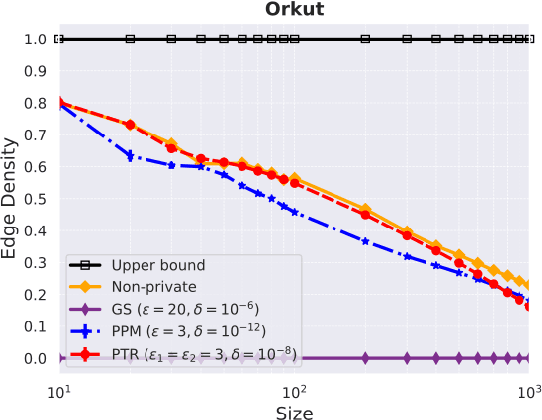
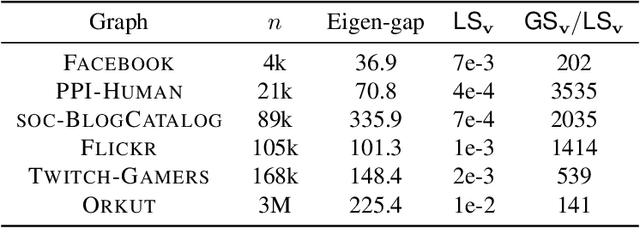
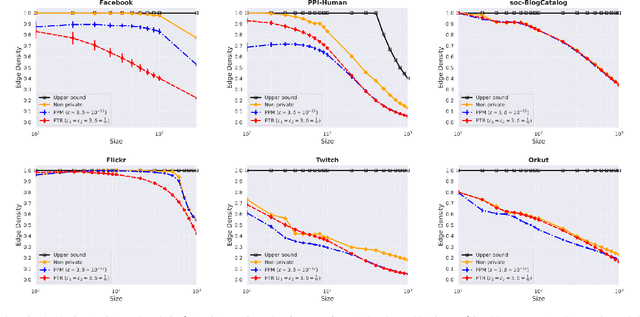
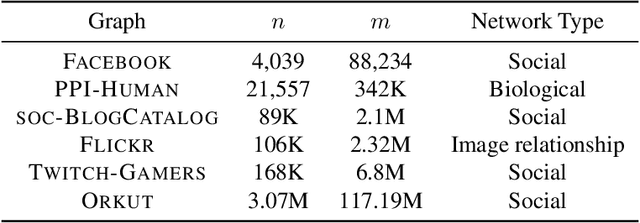
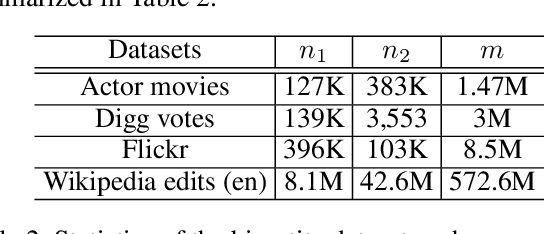
Many graph datasets involve sensitive network data, motivating the need for privacy-preserving graph mining. The Densest-$k$-subgraph (D$k$S) problem is a key primitive in graph mining that aims to extract a subset of $k$ vertices with the maximum internal connectivity. Although non-private algorithms are known for D$k$S, this paper is the first to design algorithms that offer formal differential privacy (DP) guarantees for the problem. We base our general approach on using the principal component (PC) of the graph adjacency matrix to output a subset of $k$ vertices under edge DP. For this task, we first consider output perturbation, which traditionally offer good scalability, but at the expense of utility. Our tight on the local sensitivity indicate a big gap with the global sensitivity, motivating the use of instance specific sensitive methods for private PC. Next, we derive a tight bound on the smooth sensitivity and show that it can be close to the global sensitivity. This leads us to consider the Propose-Test-Release (PTR) framework for private PC. Although computationally expensive in general, we design a novel approach for implementing PTR in the same time as computation of a non-private PC, while offering good utility for \DkS{}. Additionally, we also consider the iterative private power method (PPM) for private PC, albeit it is significantly slower than PTR on large networks. We run our methods on diverse real-world networks, with the largest having 3 million vertices, and show good privacy-utility trade-offs. Although PTR requires a slightly larger privacy budget, on average, it achieves a 180-fold improvement in runtime over PPM.
Finding the smallest or largest element of a tensor from its low-rank factors
Oct 16, 2022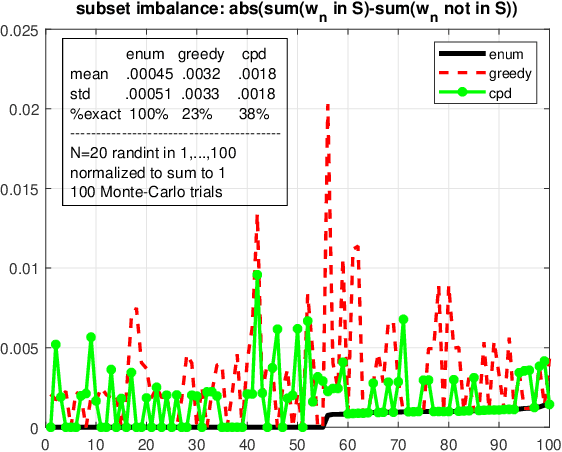
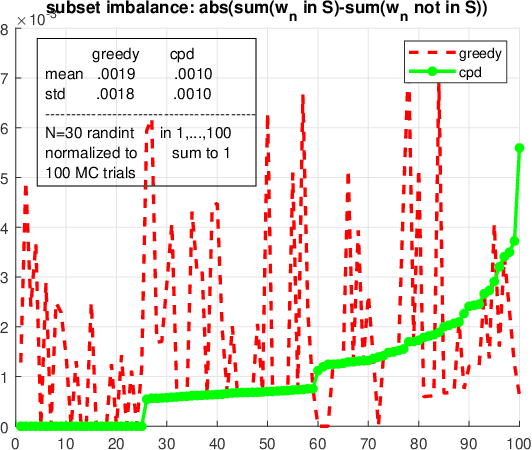
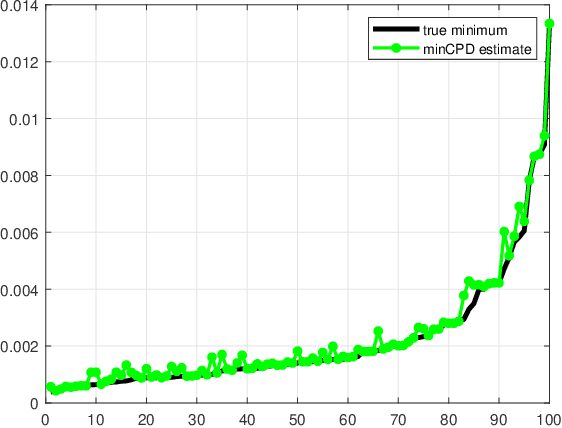
We consider the problem of finding the smallest or largest entry of a tensor of order $N$ that is specified via its rank decomposition. Stated in a different way, we are given $N$ sets of $R$-dimensional vectors and we wish to select one vector from each set such that the sum of the Hadamard product of the selected vectors is minimized or maximized. This is a fundamental tensor problem with numerous applications in embedding similarity search, recommender systems, graph mining, multivariate probability, and statistics. We show that this discrete optimization problem is NP-hard for any tensor rank higher than one, but also provide an equivalent continuous problem reformulation which is amenable to disciplined non-convex optimization. We propose a suite of gradient-based approximation algorithms whose performance in preliminary experiments appears to be promising.
PHASED: Phase-Aware Submodularity-Based Energy Disaggregation
Oct 01, 2020
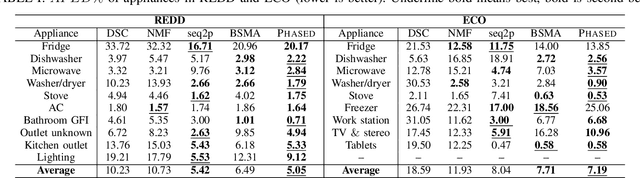
Energy disaggregation is the task of discerning the energy consumption of individual appliances from aggregated measurements, which holds promise for understanding and reducing energy usage. In this paper, we propose PHASED, an optimization approach for energy disaggregation that has two key features: PHASED (i) exploits the structure of power distribution systems to make use of readily available measurements that are neglected by existing methods, and (ii) poses the problem as a minimization of a difference of submodular functions. We leverage this form by applying a discrete optimization variant of the majorization-minimization algorithm to iteratively minimize a sequence of global upper bounds of the cost function to obtain high-quality approximate solutions. PHASED improves the disaggregation accuracy of state-of-the-art models by up to 61% and achieves better prediction on heavy load appliances.
Mining Large Quasi-cliques with Quality Guarantees from Vertex Neighborhoods
Aug 18, 2020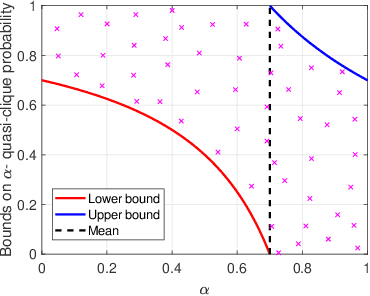
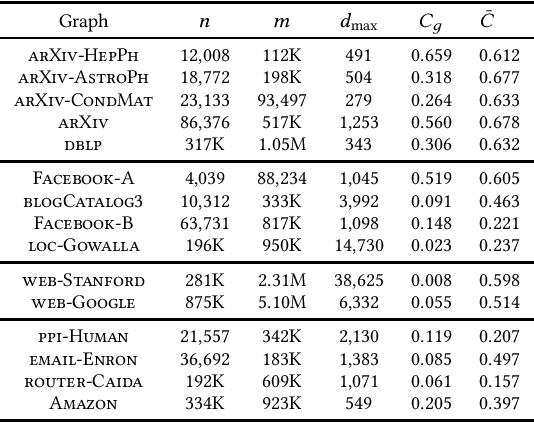
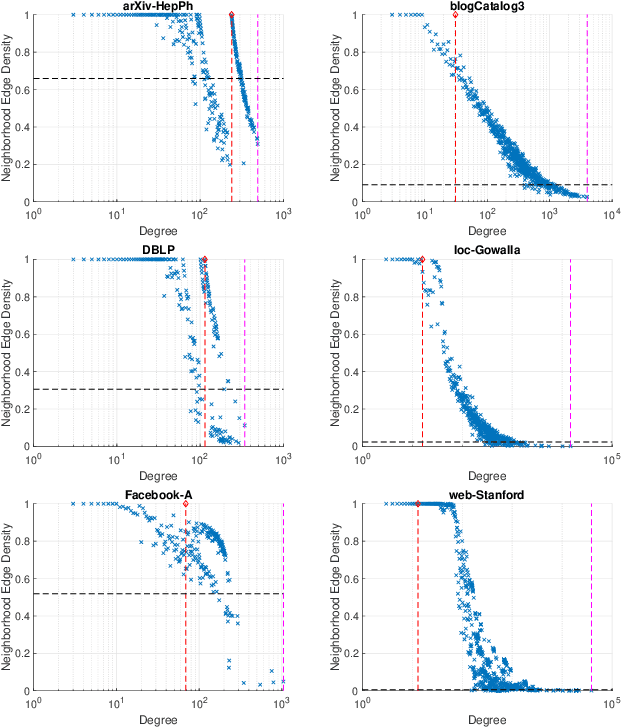
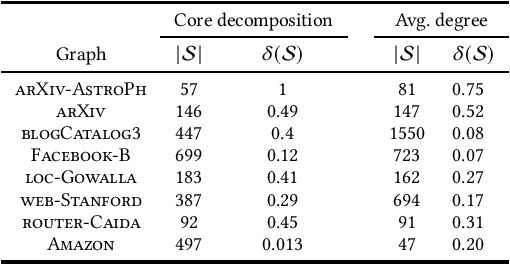
Mining dense subgraphs is an important primitive across a spectrum of graph-mining tasks. In this work, we formally establish that two recurring characteristics of real-world graphs, namely heavy-tailed degree distributions and large clustering coefficients, imply the existence of substantially large vertex neighborhoods with high edge-density. This observation suggests a very simple approach for extracting large quasi-cliques: simply scan the vertex neighborhoods, compute the clustering coefficient of each vertex, and output the best such subgraph. The implementation of such a method requires counting the triangles in a graph, which is a well-studied problem in graph mining. When empirically tested across a number of real-world graphs, this approach reveals a surprise: vertex neighborhoods include maximal cliques of non-trivial sizes, and the density of the best neighborhood often compares favorably to subgraphs produced by dedicated algorithms for maximizing subgraph density. For graphs with small clustering coefficients, we demonstrate that small vertex neighborhoods can be refined using a local-search method to ``grow'' larger cliques and near-cliques. Our results indicate that contrary to worst-case theoretical results, mining cliques and quasi-cliques of non-trivial sizes from real-world graphs is often not a difficult problem, and provides motivation for further work geared towards a better explanation of these empirical successes.