 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasi-Newton Compatible Actor-Critic for Deterministic Policies
Nov 12, 2025In this paper, we propose a second-order deterministic actor-critic framework in reinforcement learning that extends the classical deterministic policy gradient method to exploit curvature information of the performance function. Building on the concept of compatible function approximation for the critic, we introduce a quadratic critic that simultaneously preserves the true policy gradient and an approximation of the performance Hessian. A least-squares temporal difference learning scheme is then developed to estimate the quadratic critic parameters efficiently. This construction enables a quasi-Newton actor update using information learned by the critic, yielding faster convergence compared to first-order methods. The proposed approach is general and applicable to any differentiable policy class. Numerical examples demonstrate that the method achieves improved convergence and performance over standard deterministic actor-critic baselines.
Quasi-Newton Iteration in Deterministic Policy Gradient
Mar 25, 2022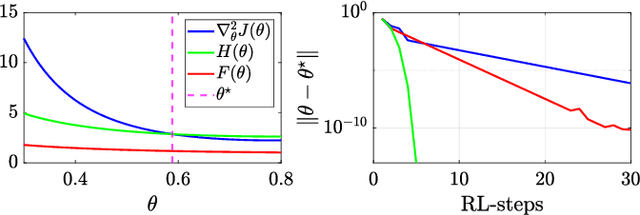
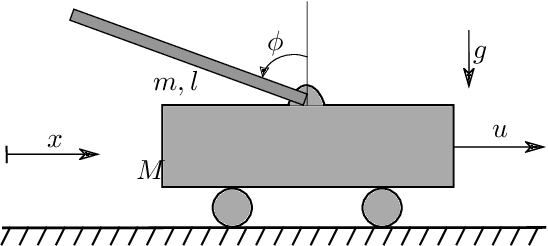

This paper presents a model-free approximation for the Hessian of the performance of deterministic policies to use in the context of Reinforcement Learning based on Quasi-Newton steps in the policy parameters. We show that the approximate Hessian converges to the exact Hessian at the optimal policy, and allows for a superlinear convergence in the learning, provided that the policy parametrization is rich. The natural policy gradient method can be interpreted as a particular case of the proposed method. We analytically verify the formulation in a simple linear case and compare the convergence of the proposed method with the natural policy gradient in a nonlinear example.
Approximate Robust NMPC using Reinforcement Learning
Apr 06, 2021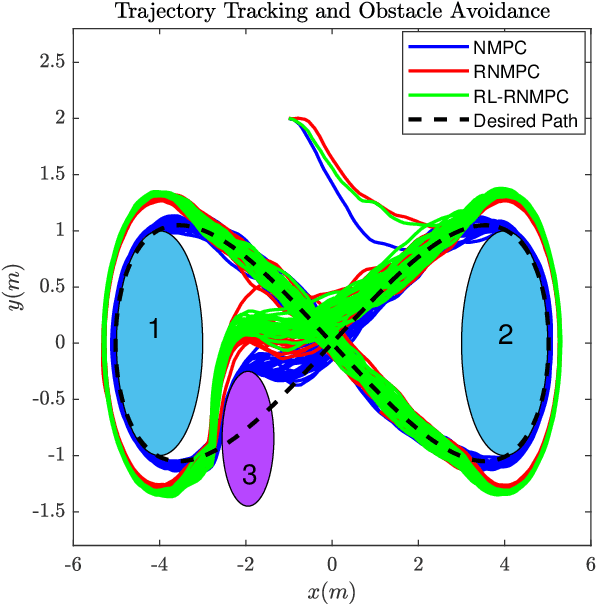
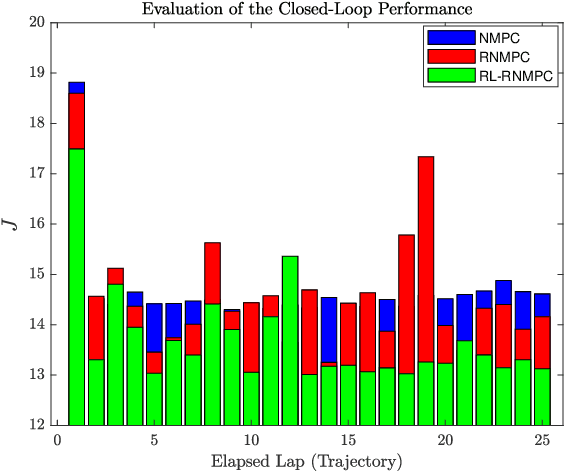
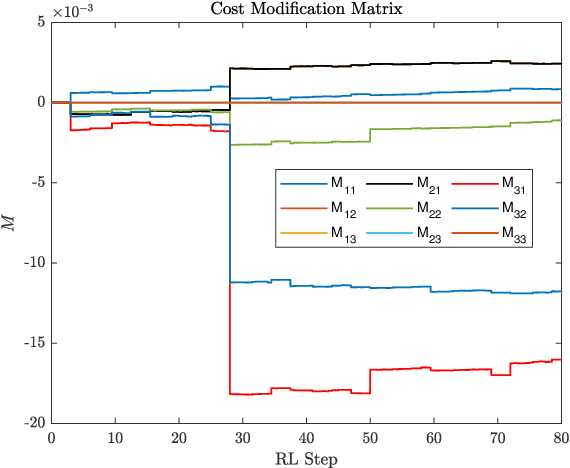
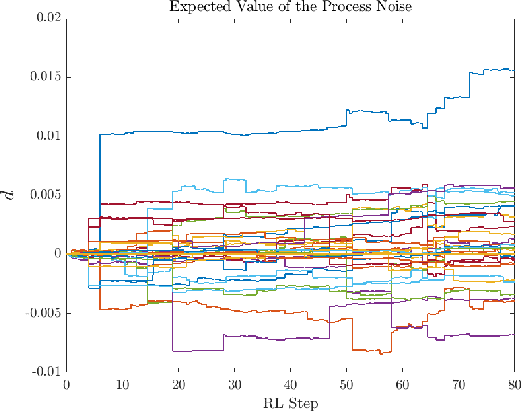
We present a Reinforcement Learning-based Robust Nonlinear Model Predictive Control (RL-RNMPC) framework for controlling nonlinear systems in the presence of disturbances and uncertainties. An approximate Robust Nonlinear Model Predictive Control (RNMPC) of low computational complexity is used in which the state trajectory uncertainty is modelled via ellipsoids. Reinforcement Learning is then used in order to handle the ellipsoidal approximation and improve the closed-loop performance of the scheme by adjusting the MPC parameters generating the ellipsoids. The approach is tested on a simulated Wheeled Mobile Robot (WMR) tracking a desired trajectory while avoiding static obstacles.
MPC-based Reinforcement Learning for Economic Problems with Application to Battery Storage
Apr 06, 2021
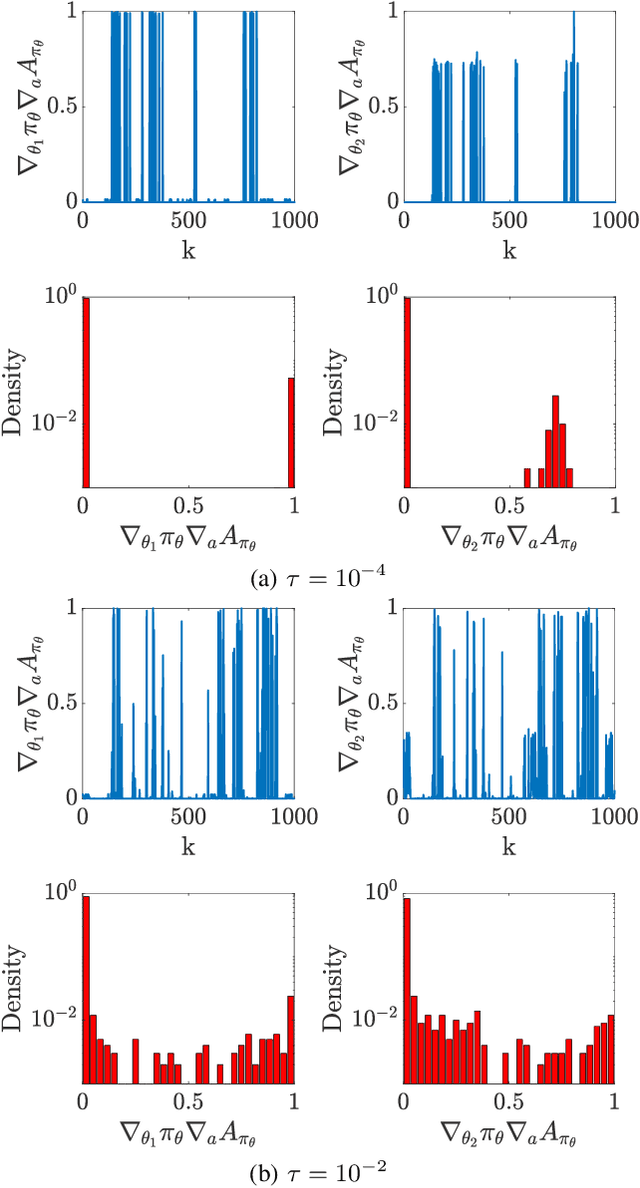

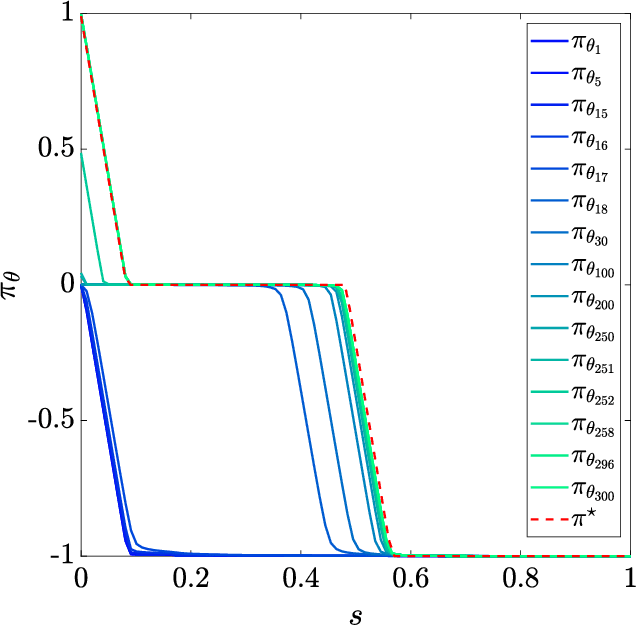
In this paper, we are interested in optimal control problems with purely economic costs, which often yield optimal policies having a (nearly) bang-bang structure. We focus on policy approximations based on Model Predictive Control (MPC) and the use of the deterministic policy gradient method to optimize the MPC closed-loop performance in the presence of unmodelled stochasticity or model error. When the policy has a (nearly) bang-bang structure, we observe that the policy gradient method can struggle to produce meaningful steps in the policy parameters. To tackle this issue, we propose a homotopy strategy based on the interior-point method, providing a relaxation of the policy during the learning. We investigate a specific well-known battery storage problem, and show that the proposed method delivers a homogeneous and faster learning than a classical policy gradient approach.