Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasi-Newton Iteration in Deterministic Policy Gradient
Paper and Code
Mar 25, 2022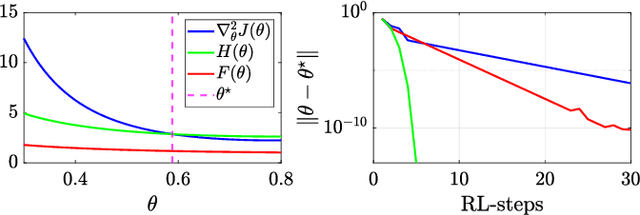
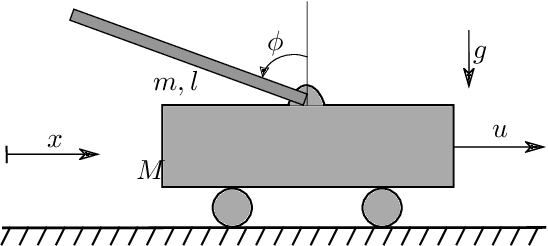

This paper presents a model-free approximation for the Hessian of the performance of deterministic policies to use in the context of Reinforcement Learning based on Quasi-Newton steps in the policy parameters. We show that the approximate Hessian converges to the exact Hessian at the optimal policy, and allows for a superlinear convergence in the learning, provided that the policy parametrization is rich. The natural policy gradient method can be interpreted as a particular case of the proposed method. We analytically verify the formulation in a simple linear case and compare the convergence of the proposed method with the natural policy gradient in a nonlinear example.
* This paper has been accepted to 2022 American Control Conference
(ACC). 6 pages
View paper on