 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Evaluating Zero-Shot Image Generation in Concept-based Explainability
May 19, 2026Concept-based Explainable Artificial Intelligence (XAI) interprets deep learning models using human-understandable visual features (e.g., textures or object parts) by linking internal representations to class predictions, thereby bridging the gap between low-level image data and high-level semantics. A major challenge, however, is the reliance on large sets of labeled images to represent each concept, which limits scalability. In this work, we investigate the use of zero-shot Text-to-Image (T2I) generative models as a source of synthetic concept datasets for concept-based XAI methods. Specifically, we generate concepts using predefined prompts and evaluate their faithfulness to real ones through four complementary analyses: (1) comparing synthetic vs. real concept images via concept representation similarity; (2) evaluating their intra-similarity by comparing pairs of subsets of the same concept with progressively increasing size; (3) evaluating their performance for downstream explanation tasks using relevant class images; (4) evaluating how removing a concept from tested class images affects explanations of generated concepts. While current T2I generative models promise a shortcut to concept-based XAI, our study highlights challenges and raises open questions about the use of synthetic data generated by zero-shot pipelines in model analyses. The resulting dataset is available at https://github.com/DataSciencePolimi/ZeroShot-T2I-Concepts.
LLM-Enhanced Semantic Data Integration of Electronic Component Qualifications in the Aerospace Domain
Mar 20, 2026Large manufacturing companies face challenges in information retrieval due to data silos maintained by different departments, leading to inconsistencies and misalignment across databases. This paper presents an experience in integrating and retrieving qualification data for electronic components used in satellite board design. Due to data silos, designers cannot immediately determine the qualification status of individual components. However, this process is critical during the planning phase, when assembly drawings are issued before production, to optimize new qualifications and avoid redundant efforts. To address this, we propose a pipeline that uses Virtual Knowledge Graphs for a unified view over heterogeneous data sources and LLMs to enhance retrieval and reduce manual effort in data cleansing. The retrieval of qualifications is then performed through an Ontology-based Data Access approach for structured queries and a vector search mechanism for retrieving qualifications based on similar textual properties. We perform a comparative cost-benefit analysis, demonstrating that the proposed pipeline also outperforms approaches relying solely on LLMs, such as Retrieval-Augmented Generation (RAG), in terms of long-term efficiency.
Visual-TCAV: Concept-based Attribution and Saliency Maps for Post-hoc Explainability in Image Classification
Nov 08, 2024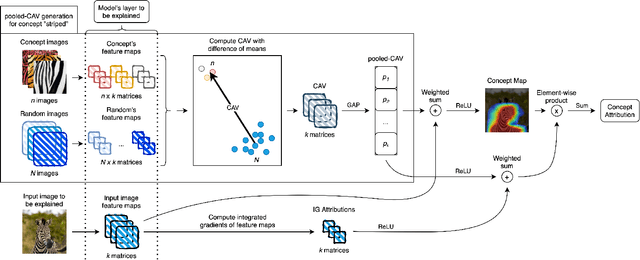

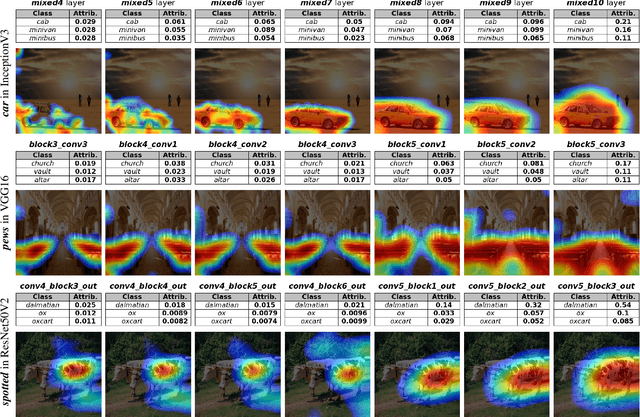
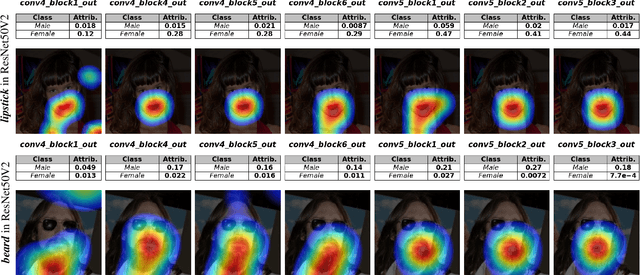
Convolutional Neural Networks (CNNs) have seen significant performance improvements in recent years. However, due to their size and complexity, they function as black-boxes, leading to transparency concerns. State-of-the-art saliency methods generate local explanations that highlight the area in the input image where a class is identified but cannot explain how a concept of interest contributes to the prediction, which is essential for bias mitigation. On the other hand, concept-based methods, such as TCAV (Testing with Concept Activation Vectors), provide insights into how sensitive is the network to a concept, but cannot compute its attribution in a specific prediction nor show its location within the input image. This paper introduces a novel post-hoc explainability framework, Visual-TCAV, which aims to bridge the gap between these methods by providing both local and global explanations for CNN-based image classification. Visual-TCAV uses Concept Activation Vectors (CAVs) to generate saliency maps that show where concepts are recognized by the network. Moreover, it can estimate the attribution of these concepts to the output of any class using a generalization of Integrated Gradients. This framework is evaluated on popular CNN architectures, with its validity further confirmed via experiments where ground truth for explanations is known, and a comparison with TCAV. Our code will be made available soon.
Enriching Ontologies with Disjointness Axioms using Large Language Models
Oct 04, 2024

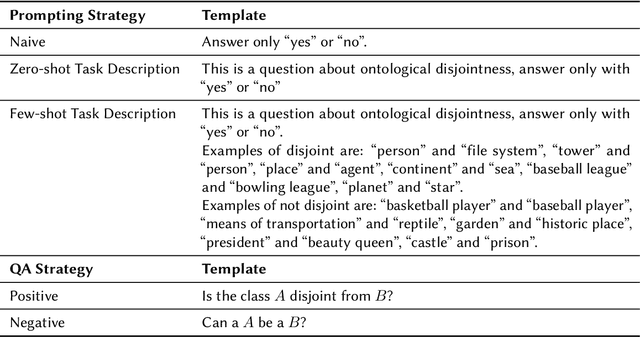
Ontologies often lack explicit disjointness declarations between classes, despite their usefulness for sophisticated reasoning and consistency checking in Knowledge Graphs. In this study, we explore the potential of Large Language Models (LLMs) to enrich ontologies by identifying and asserting class disjointness axioms. Our approach aims at leveraging the implicit knowledge embedded in LLMs, using prompt engineering to elicit this knowledge for classifying ontological disjointness. We validate our methodology on the DBpedia ontology, focusing on open-source LLMs. Our findings suggest that LLMs, when guided by effective prompt strategies, can reliably identify disjoint class relationships, thus streamlining the process of ontology completion without extensive manual input. For comprehensive disjointness enrichment, we propose a process that takes logical relationships between disjointness and subclass statements into account in order to maintain satisfiability and reduce the number of calls to the LLM. This work provides a foundation for future applications of LLMs in automated ontology enhancement and offers insights into optimizing LLM performance through strategic prompt design. Our code is publicly available on GitHub at https://github.com/n28div/llm-disjointness.
Integrating Large Language Models and Knowledge Graphs for Extraction and Validation of Textual Test Data
Aug 03, 2024Aerospace manufacturing companies, such as Thales Alenia Space, design, develop, integrate, verify, and validate products characterized by high complexity and low volume. They carefully document all phases for each product but analyses across products are challenging due to the heterogeneity and unstructured nature of the data in documents. In this paper, we propose a hybrid methodology that leverages Knowledge Graphs (KGs) in conjunction with Large Language Models (LLMs) to extract and validate data contained in these documents. We consider a case study focused on test data related to electronic boards for satellites. To do so, we extend the Semantic Sensor Network ontology. We store the metadata of the reports in a KG, while the actual test results are stored in parquet accessible via a Virtual Knowledge Graph. The validation process is managed using an LLM-based approach. We also conduct a benchmarking study to evaluate the performance of state-of-the-art LLMs in executing this task. Finally, we analyze the costs and benefits of automating preexisting processes of manual data extraction and validation for subsequent cross-report analyses.
Interpretable Network Visualizations: A Human-in-the-Loop Approach for Post-hoc Explainability of CNN-based Image Classification
May 06, 2024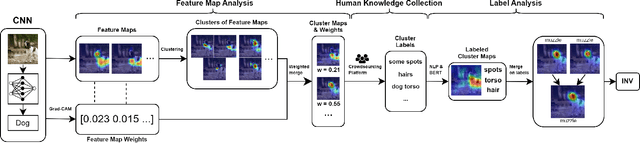
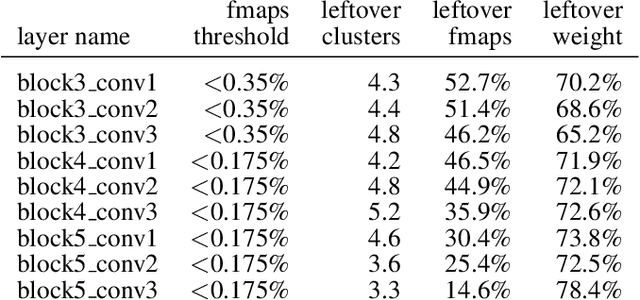
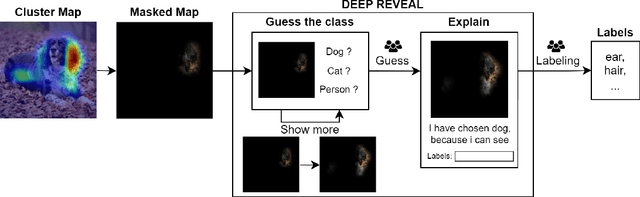

Transparency and explainability in image classification are essential for establishing trust in machine learning models and detecting biases and errors. State-of-the-art explainability methods generate saliency maps to show where a specific class is identified, without providing a detailed explanation of the model's decision process. Striving to address such a need, we introduce a post-hoc method that explains the entire feature extraction process of a Convolutional Neural Network. These explanations include a layer-wise representation of the features the model extracts from the input. Such features are represented as saliency maps generated by clustering and merging similar feature maps, to which we associate a weight derived by generalizing Grad-CAM for the proposed methodology. To further enhance these explanations, we include a set of textual labels collected through a gamified crowdsourcing activity and processed using NLP techniques and Sentence-BERT. Finally, we show an approach to generate global explanations by aggregating labels across multiple images.