 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAESTRO: Masked AutoEncoders for Multimodal, Multitemporal, and Multispectral Earth Observation Data
Aug 14, 2025Self-supervised learning holds great promise for remote sensing, but standard self-supervised methods must be adapted to the unique characteristics of Earth observation data. We take a step in this direction by conducting a comprehensive benchmark of fusion strategies and reconstruction target normalization schemes for multimodal, multitemporal, and multispectral Earth observation data. Based on our findings, we propose MAESTRO, a novel adaptation of the Masked Autoencoder, featuring optimized fusion strategies and a tailored target normalization scheme that introduces a spectral prior as a self-supervisory signal. Evaluated on four Earth observation datasets, MAESTRO sets a new state-of-the-art on tasks that strongly rely on multitemporal dynamics, while remaining highly competitive on tasks dominated by a single mono-temporal modality. Code to reproduce all our experiments is available at https://github.com/ignf/maestro.
Making EfficientNet More Efficient: Exploring Batch-Independent Normalization, Group Convolutions and Reduced Resolution Training
Jun 15, 2021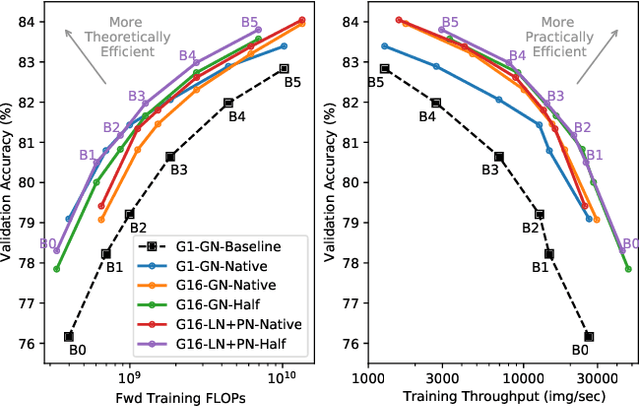

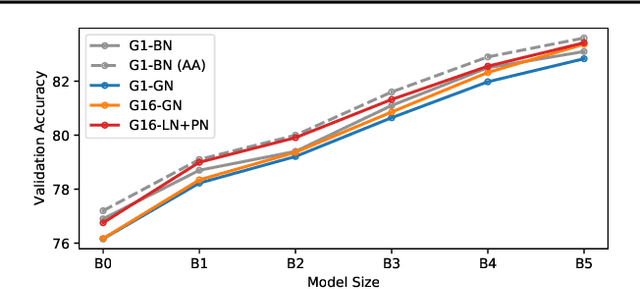
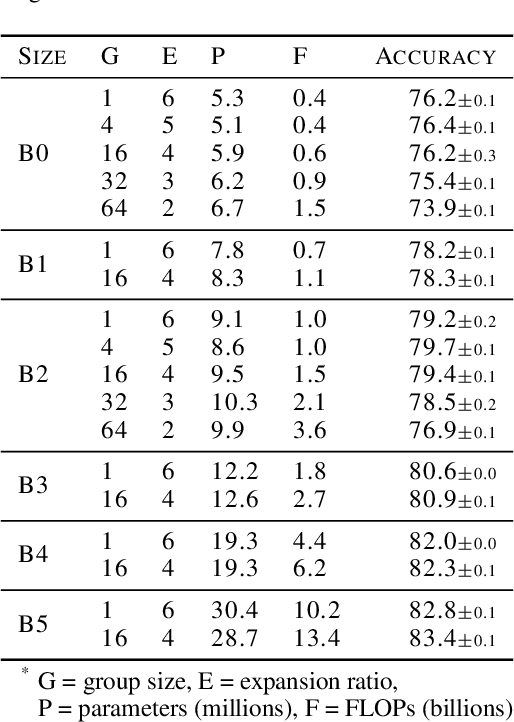
Much recent research has been dedicated to improving the efficiency of training and inference for image classification. This effort has commonly focused on explicitly improving theoretical efficiency, often measured as ImageNet validation accuracy per FLOP. These theoretical savings have, however, proven challenging to achieve in practice, particularly on high-performance training accelerators. In this work, we focus on improving the practical efficiency of the state-of-the-art EfficientNet models on a new class of accelerator, the Graphcore IPU. We do this by extending this family of models in the following ways: (i) generalising depthwise convolutions to group convolutions; (ii) adding proxy-normalized activations to match batch normalization performance with batch-independent statistics; (iii) reducing compute by lowering the training resolution and inexpensively fine-tuning at higher resolution. We find that these three methods improve the practical efficiency for both training and inference. Our code will be made available online.
Proxy-Normalizing Activations to Match Batch Normalization while Removing Batch Dependence
Jun 11, 2021
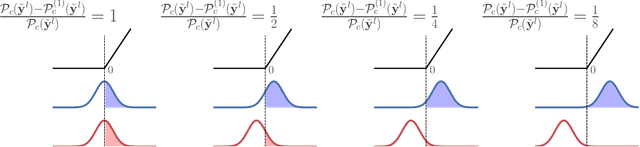

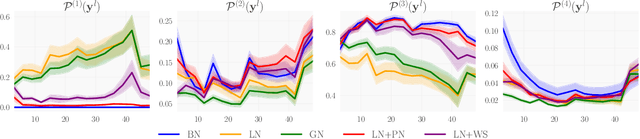
We investigate the reasons for the performance degradation incurred with batch-independent normalization. We find that the prototypical techniques of layer normalization and instance normalization both induce the appearance of failure modes in the neural network's pre-activations: (i) layer normalization induces a collapse towards channel-wise constant functions; (ii) instance normalization induces a lack of variability in instance statistics, symptomatic of an alteration of the expressivity. To alleviate failure mode (i) without aggravating failure mode (ii), we introduce the technique "Proxy Normalization" that normalizes post-activations using a proxy distribution. When combined with layer normalization or group normalization, this batch-independent normalization emulates batch normalization's behavior and consistently matches or exceeds its performance.
Characterizing Well-behaved vs. Pathological Deep Neural Network Architectures
Nov 07, 2018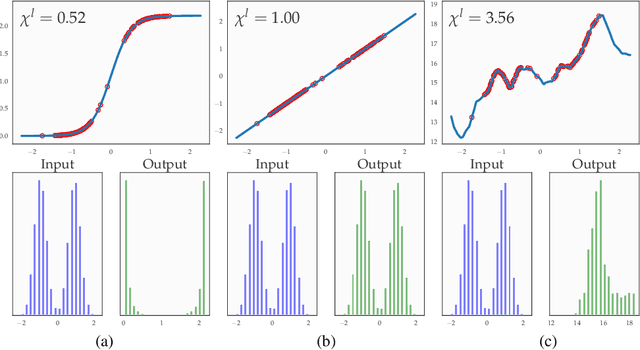
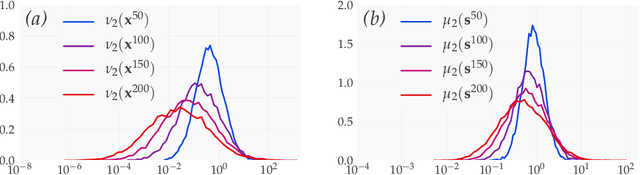
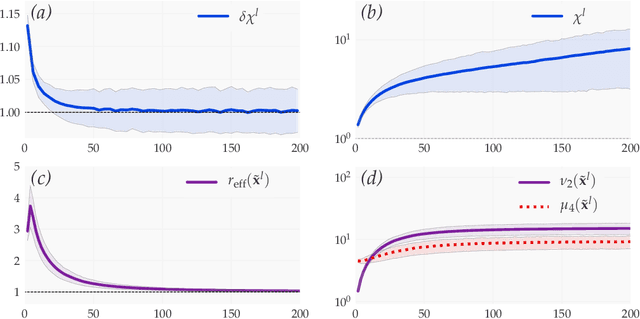
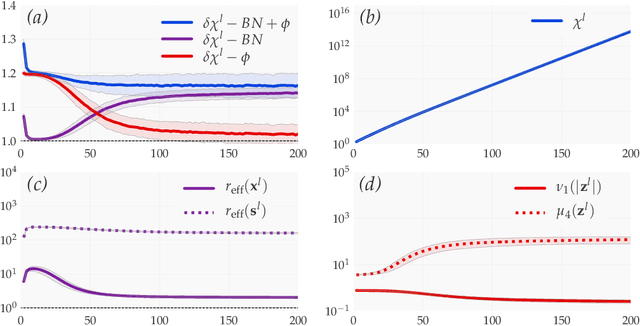
We introduce a principled approach, requiring only mild assumptions, for the characterization of deep neural networks at initialization. Our approach applies both to fully-connected and convolutional networks and incorporates the commonly used techniques of batch normalization and skip-connections. Our key insight is to consider the evolution with depth of statistical moments of signal and sensitivity, thereby characterizing the well-behaved or pathological behaviour of input-output mappings encoded by different choices of architecture. We establish: (i) for feedforward networks with and without batch normalization, depth multiplicativity inevitably leads to ill-behaved moments and distributional pathologies; (ii) for residual networks, on the other hand, the mechanism of identity skip-connection induces power-law rather than exponential behaviour, leading to well-behaved moments and no distributional pathology.