 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking EfficientNet More Efficient: Exploring Batch-Independent Normalization, Group Convolutions and Reduced Resolution Training
Paper and Code
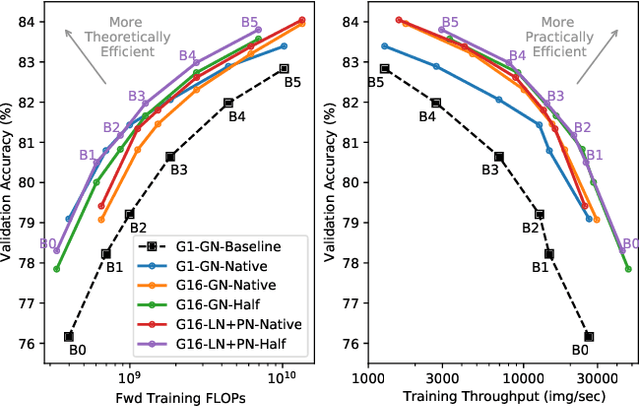

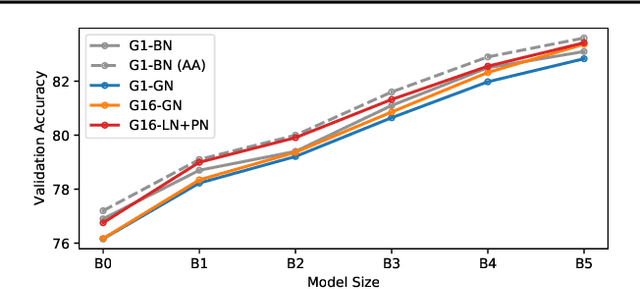
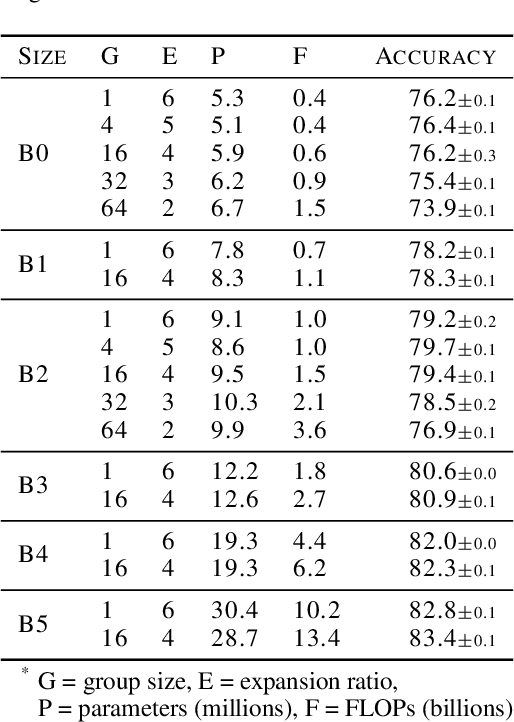
Much recent research has been dedicated to improving the efficiency of training and inference for image classification. This effort has commonly focused on explicitly improving theoretical efficiency, often measured as ImageNet validation accuracy per FLOP. These theoretical savings have, however, proven challenging to achieve in practice, particularly on high-performance training accelerators. In this work, we focus on improving the practical efficiency of the state-of-the-art EfficientNet models on a new class of accelerator, the Graphcore IPU. We do this by extending this family of models in the following ways: (i) generalising depthwise convolutions to group convolutions; (ii) adding proxy-normalized activations to match batch normalization performance with batch-independent statistics; (iii) reducing compute by lowering the training resolution and inexpensively fine-tuning at higher resolution. We find that these three methods improve the practical efficiency for both training and inference. Our code will be made available online.