 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Reward Machines from Partially Observed Optimal Policies
Feb 06, 2025



Inverse reinforcement learning is the problem of inferring a reward function from an optimal policy. In this work, it is assumed that the reward is expressed as a reward machine whose transitions depend on atomic propositions associated with the state of a Markov Decision Process (MDP). Our goal is to identify the true reward machine using finite information. To this end, we first introduce the notion of a prefix tree policy which associates a distribution of actions to each state of the MDP and each attainable finite sequence of atomic propositions. Then, we characterize an equivalence class of reward machines that can be identified given the prefix tree policy. Finally, we propose a SAT-based algorithm that uses information extracted from the prefix tree policy to solve for a reward machine. It is proved that if the prefix tree policy is known up to a sufficient (but finite) depth, our algorithm recovers the exact reward machine up to the equivalence class. This sufficient depth is derived as a function of the number of MDP states and (an upper bound on) the number of states of the reward machine. Several examples are used to demonstrate the effectiveness of the approach.
Positive semi-definite embedding for dimensionality reduction and out-of-sample extensions
Nov 21, 2017
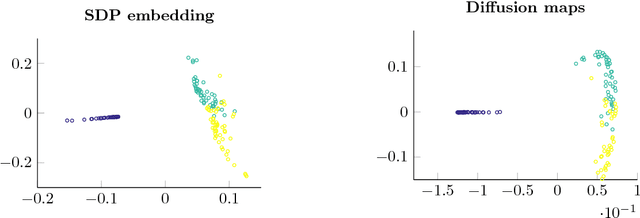
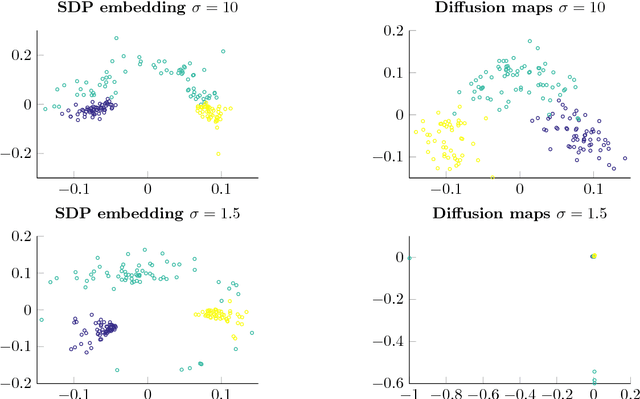
In machine learning or statistics, it is often desirable to reduce the dimensionality of high dimensional data. We propose to obtain the low dimensional embedding coordinates as the eigenvectors of a positive semi-definite kernel matrix. This kernel matrix is the solution of a semi-definite program promoting a low rank solution and defined with the help of a diffusion kernel. Besides, we also discuss an infinite dimensional analogue of the same semi-definite program. From a practical perspective, a main feature of our approach is the existence of a non-linear out-of-sample extension formula of the embedding coordinates that we call a projected Nystr\"om approximation. This extension formula yields an extension of the kernel matrix to a data-dependent Mercer kernel function. Although the semi-definite program may be solved directly, we propose another strategy based on a rank constrained formulation solved thanks to a projected power method algorithm followed by a singular value decomposition. This strategy allows for a reduced computational time.