 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Online Hate Speech through the Causal Lens
Sep 16, 2021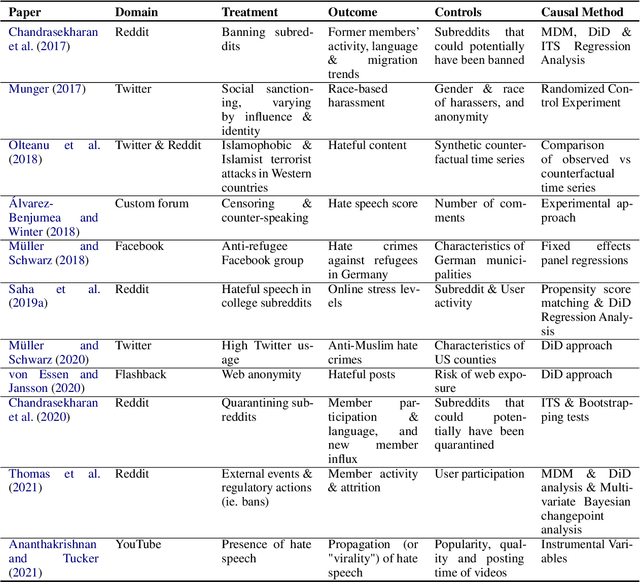
The societal issue of digital hostility has previously attracted a lot of attention. The topic counts an ample body of literature, yet remains prominent and challenging as ever due to its subjective nature. We posit that a better understanding of this problem will require the use of causal inference frameworks. This survey summarises the relevant research that revolves around estimations of causal effects related to online hate speech. Initially, we provide an argumentation as to why re-establishing the exploration of hate speech in causal terms is of the essence. Following that, we give an overview of the leading studies classified with respect to the direction of their outcomes, as well as an outline of all related research, and a summary of open research problems that can influence future work on the topic.
A Unified Deep Learning Architecture for Abuse Detection
Feb 21, 2018
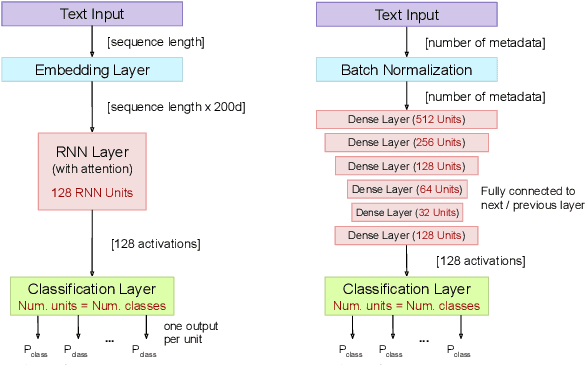
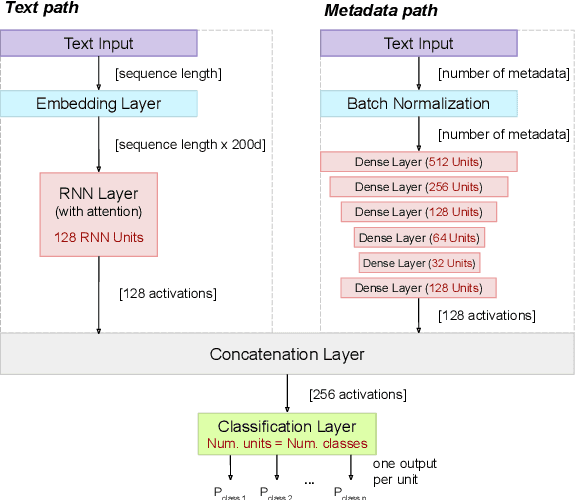
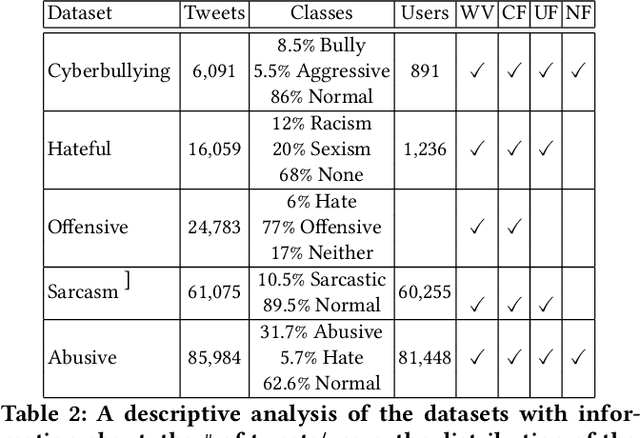
Hate speech, offensive language, sexism, racism and other types of abusive behavior have become a common phenomenon in many online social media platforms. In recent years, such diverse abusive behaviors have been manifesting with increased frequency and levels of intensity. This is due to the openness and willingness of popular media platforms, such as Twitter and Facebook, to host content of sensitive or controversial topics. However, these platforms have not adequately addressed the problem of online abusive behavior, and their responsiveness to the effective detection and blocking of such inappropriate behavior remains limited. In the present paper, we study this complex problem by following a more holistic approach, which considers the various aspects of abusive behavior. To make the approach tangible, we focus on Twitter data and analyze user and textual properties from different angles of abusive posting behavior. We propose a deep learning architecture, which utilizes a wide variety of available metadata, and combines it with automatically-extracted hidden patterns within the text of the tweets, to detect multiple abusive behavioral norms which are highly inter-related. We apply this unified architecture in a seamless, transparent fashion to detect different types of abusive behavior (hate speech, sexism vs. racism, bullying, sarcasm, etc.) without the need for any tuning of the model architecture for each task. We test the proposed approach with multiple datasets addressing different and multiple abusive behaviors on Twitter. Our results demonstrate that it largely outperforms the state-of-art methods (between 21 and 45\% improvement in AUC, depending on the dataset).