 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColonoscopy Landmark Detection using Vision Transformers
Sep 27, 2022
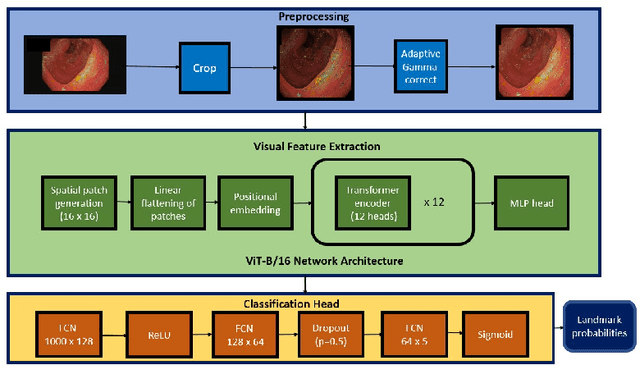
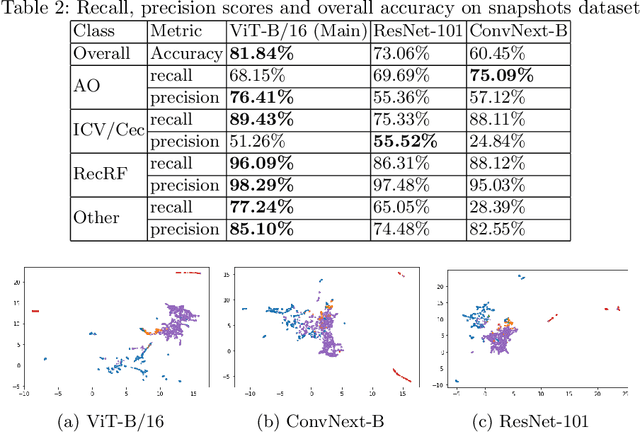
Colonoscopy is a routine outpatient procedure used to examine the colon and rectum for any abnormalities including polyps, diverticula and narrowing of colon structures. A significant amount of the clinician's time is spent in post-processing snapshots taken during the colonoscopy procedure, for maintaining medical records or further investigation. Automating this step can save time and improve the efficiency of the process. In our work, we have collected a dataset of 120 colonoscopy videos and 2416 snapshots taken during the procedure, that have been annotated by experts. Further, we have developed a novel, vision-transformer based landmark detection algorithm that identifies key anatomical landmarks (the appendiceal orifice, ileocecal valve/cecum landmark and rectum retroflexion) from snapshots taken during colonoscopy. Our algorithm uses an adaptive gamma correction during preprocessing to maintain a consistent brightness for all images. We then use a vision transformer as the feature extraction backbone and a fully connected network based classifier head to categorize a given frame into four classes: the three landmarks or a non-landmark frame. We compare the vision transformer (ViT-B/16) backbone with ResNet-101 and ConvNext-B backbones that have been trained similarly. We report an accuracy of 82% with the vision transformer backbone on a test dataset of snapshots.
Pediatric Otoscopy Video Screening with Shift Contrastive Anomaly Detection
Oct 25, 2021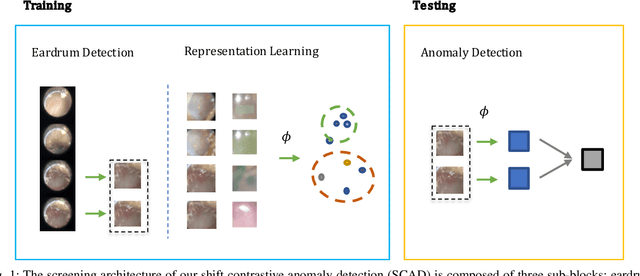
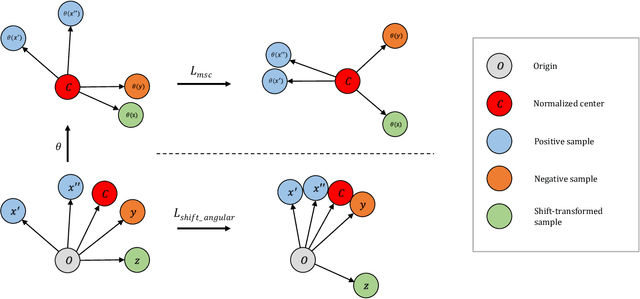

Ear related concerns and symptoms represents the leading indication for seeking pediatric healthcare attention. Despite the high incidence of such encounters, the diagnostic process of commonly encountered disease of the middle and external presents significant challenge. Much of this challenge stems from the lack of cost effective diagnostic testing, which necessitating the presence or absence of ear pathology to be determined clinically. Research has however demonstrated considerable variation among clinicians in their ability to accurately diagnose and consequently manage ear pathology. With recent advances in computer vision and machine learning, there is an increasing interest in helping clinicians to accurately diagnose middle and external ear pathology with computer-aided systems. It has been shown that AI has the capacity to analyse a single clinical image captured during examination of the ear canal and eardrum from which it can determine the likelihood of a pathognomonic pattern for a specific diagnosis being present. The capture of such an image can however be challenging especially to inexperienced clinicians. To help mitigate this technical challenge we have developed and tested a method using video sequences. We present a two stage method that first, identifies valid frames by detecting and extracting ear drum patches from the video sequence, and second, performs the proposed shift contrastive anomaly detection to flag the otoscopy video sequences as normal or abnormal. Our method achieves an AUROC of 88.0% on the patient-level and also outperforms the average of a group of 25 clinicians in a comparative study, which is the largest of such published to date. We conclude that the presented method achieves a promising first step towards automated analysis of otoscopy video.
Multimodal and self-supervised representation learning for automatic gesture recognition in surgical robotics
Oct 31, 2020

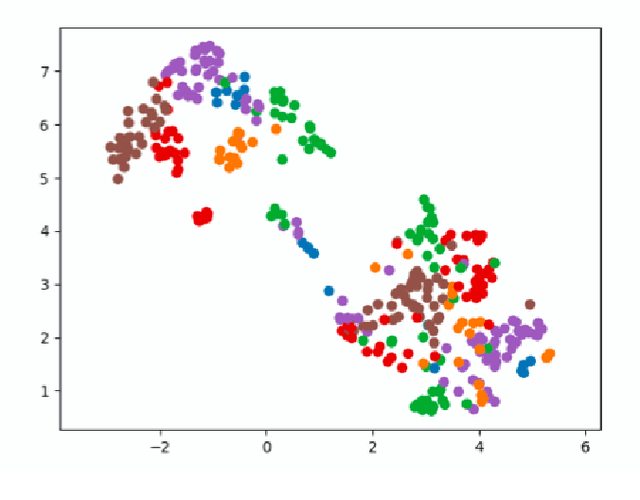

Self-supervised, multi-modal learning has been successful in holistic representation of complex scenarios. This can be useful to consolidate information from multiple modalities which have multiple, versatile uses. Its application in surgical robotics can lead to simultaneously developing a generalised machine understanding of the surgical process and reduce the dependency on quality, expert annotations which are generally difficult to obtain. We develop a self-supervised, multi-modal representation learning paradigm that learns representations for surgical gestures from video and kinematics. We use an encoder-decoder network configuration that encodes representations from surgical videos and decodes them to yield kinematics. We quantitatively demonstrate the efficacy of our learnt representations for gesture recognition (with accuracy between 69.6 % and 77.8 %), transfer learning across multiple tasks (with accuracy between 44.6 % and 64.8 %) and surgeon skill classification (with accuracy between 76.8 % and 81.2 %). Further, we qualitatively demonstrate that our self-supervised representations cluster in semantically meaningful properties (surgeon skill and gestures).