 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal and self-supervised representation learning for automatic gesture recognition in surgical robotics
Paper and Code
Oct 31, 2020

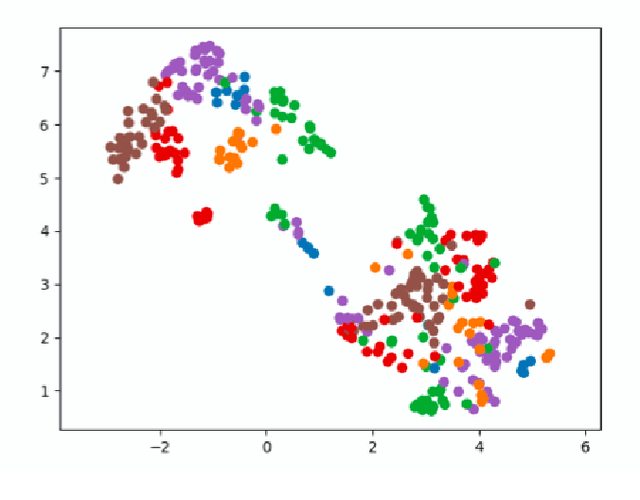

Self-supervised, multi-modal learning has been successful in holistic representation of complex scenarios. This can be useful to consolidate information from multiple modalities which have multiple, versatile uses. Its application in surgical robotics can lead to simultaneously developing a generalised machine understanding of the surgical process and reduce the dependency on quality, expert annotations which are generally difficult to obtain. We develop a self-supervised, multi-modal representation learning paradigm that learns representations for surgical gestures from video and kinematics. We use an encoder-decoder network configuration that encodes representations from surgical videos and decodes them to yield kinematics. We quantitatively demonstrate the efficacy of our learnt representations for gesture recognition (with accuracy between 69.6 % and 77.8 %), transfer learning across multiple tasks (with accuracy between 44.6 % and 64.8 %) and surgeon skill classification (with accuracy between 76.8 % and 81.2 %). Further, we qualitatively demonstrate that our self-supervised representations cluster in semantically meaningful properties (surgeon skill and gestures).