 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Cue Anomaly Detection and Localization under Data Contamination
Jan 30, 2026Visual anomaly detection in real-world industrial settings faces two major limitations. First, most existing methods are trained on purely normal data or on unlabeled datasets assumed to be predominantly normal, presuming the absence of contamination, an assumption that is rarely satisfied in practice. Second, they assume no access to labeled anomaly samples, limiting the model from learning discriminative characteristics of true anomalies. Therefore, these approaches often struggle to distinguish anomalies from normal instances, resulting in reduced detection and weak localization performance. In real-world applications, where training data are frequently contaminated with anomalies, such methods fail to deliver reliable performance. In this work, we propose a robust anomaly detection framework that integrates limited anomaly supervision into the adaptive deviation learning paradigm. We introduce a composite anomaly score that combines three complementary components: a deviation score capturing statistical irregularity, an entropy-based uncertainty score reflecting predictive inconsistency, and a segmentation-based score highlighting spatial abnormality. This unified scoring mechanism enables accurate detection and supports gradient-based localization, providing intuitive and explainable visual evidence of anomalous regions. Following the few-anomaly paradigm, we incorporate a small set of labeled anomalies during training while simultaneously mitigating the influence of contaminated samples through adaptive instance weighting. Extensive experiments on the MVTec and VisA benchmarks demonstrate that our framework outperforms state-of-the-art baselines and achieves strong detection and localization performance, interpretability, and robustness under various levels of data contamination.
Unmasking Backdoors: An Explainable Defense via Gradient-Attention Anomaly Scoring for Pre-trained Language Models
Oct 05, 2025Pre-trained language models have achieved remarkable success across a wide range of natural language processing (NLP) tasks, particularly when fine-tuned on large, domain-relevant datasets. However, they remain vulnerable to backdoor attacks, where adversaries embed malicious behaviors using trigger patterns in the training data. These triggers remain dormant during normal usage, but, when activated, can cause targeted misclassifications. In this work, we investigate the internal behavior of backdoored pre-trained encoder-based language models, focusing on the consistent shift in attention and gradient attribution when processing poisoned inputs; where the trigger token dominates both attention and gradient signals, overriding the surrounding context. We propose an inference-time defense that constructs anomaly scores by combining token-level attention and gradient information. Extensive experiments on text classification tasks across diverse backdoor attack scenarios demonstrate that our method significantly reduces attack success rates compared to existing baselines. Furthermore, we provide an interpretability-driven analysis of the scoring mechanism, shedding light on trigger localization and the robustness of the proposed defense.
Adaptive Deviation Learning for Visual Anomaly Detection with Data Contamination
Nov 14, 2024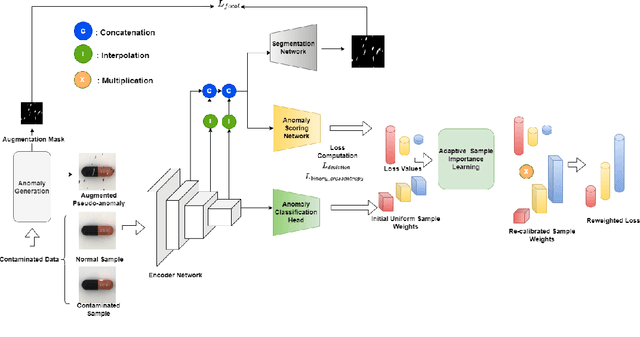


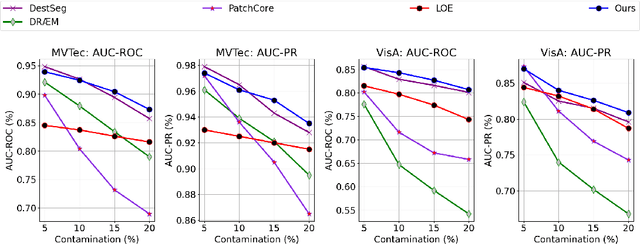
Visual anomaly detection targets to detect images that notably differ from normal pattern, and it has found extensive application in identifying defective parts within the manufacturing industry. These anomaly detection paradigms predominantly focus on training detection models using only clean, unlabeled normal samples, assuming an absence of contamination; a condition often unmet in real-world scenarios. The performance of these methods significantly depends on the quality of the data and usually decreases when exposed to noise. We introduce a systematic adaptive method that employs deviation learning to compute anomaly scores end-to-end while addressing data contamination by assigning relative importance to the weights of individual instances. In this approach, the anomaly scores for normal instances are designed to approximate scalar scores obtained from the known prior distribution. Meanwhile, anomaly scores for anomaly examples are adjusted to exhibit statistically significant deviations from these reference scores. Our approach incorporates a constrained optimization problem within the deviation learning framework to update instance weights, resolving this problem for each mini-batch. Comprehensive experiments on the MVTec and VisA benchmark datasets indicate that our proposed method surpasses competing techniques and exhibits both stability and robustness in the presence of data contamination.
Few-shot Anomaly Detection in Text with Deviation Learning
Aug 22, 2023Most current methods for detecting anomalies in text concentrate on constructing models solely relying on unlabeled data. These models operate on the presumption that no labeled anomalous examples are available, which prevents them from utilizing prior knowledge of anomalies that are typically present in small numbers in many real-world applications. Furthermore, these models prioritize learning feature embeddings rather than optimizing anomaly scores directly, which could lead to suboptimal anomaly scoring and inefficient use of data during the learning process. In this paper, we introduce FATE, a deep few-shot learning-based framework that leverages limited anomaly examples and learns anomaly scores explicitly in an end-to-end method using deviation learning. In this approach, the anomaly scores of normal examples are adjusted to closely resemble reference scores obtained from a prior distribution. Conversely, anomaly samples are forced to have anomalous scores that considerably deviate from the reference score in the upper tail of the prior. Additionally, our model is optimized to learn the distinct behavior of anomalies by utilizing a multi-head self-attention layer and multiple instance learning approaches. Comprehensive experiments on several benchmark datasets demonstrate that our proposed approach attains a new level of state-of-the-art performance.
Self-Supervised Image-to-Text and Text-to-Image Synthesis
Dec 09, 2021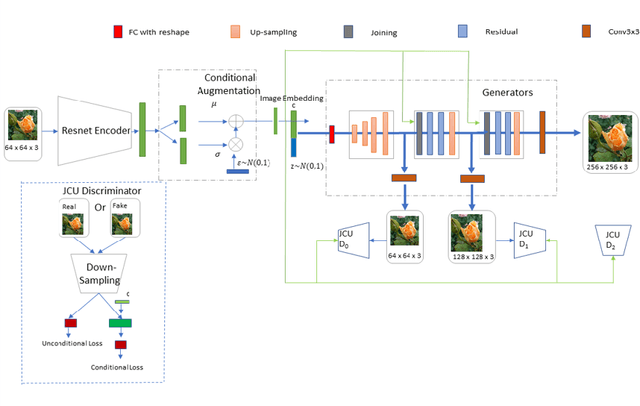

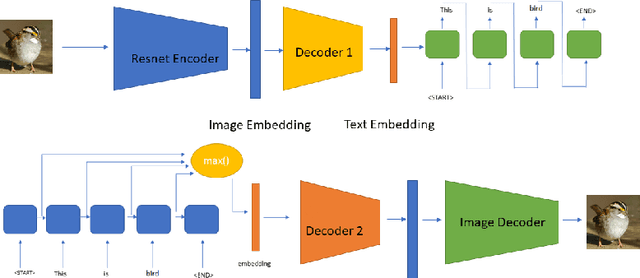
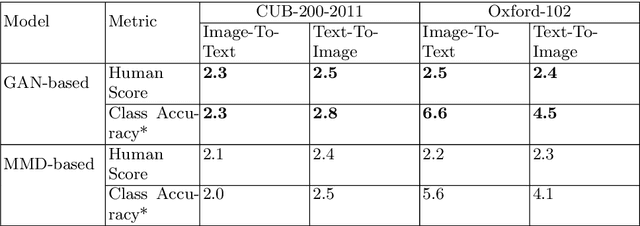
A comprehensive understanding of vision and language and their interrelation are crucial to realize the underlying similarities and differences between these modalities and to learn more generalized, meaningful representations. In recent years, most of the works related to Text-to-Image synthesis and Image-to-Text generation, focused on supervised generative deep architectures to solve the problems, where very little interest was placed on learning the similarities between the embedding spaces across modalities. In this paper, we propose a novel self-supervised deep learning based approach towards learning the cross-modal embedding spaces; for both image to text and text to image generations. In our approach, we first obtain dense vector representations of images using StackGAN-based autoencoder model and also dense vector representations on sentence-level utilizing LSTM based text-autoencoder; then we study the mapping from embedding space of one modality to embedding space of the other modality utilizing GAN and maximum mean discrepancy based generative networks. We, also demonstrate that our model learns to generate textual description from image data as well as images from textual data both qualitatively and quantitatively.
* ICONIP 2021 : The 28th International Conference on Neural Information Processing