 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Deviation Learning for Visual Anomaly Detection with Data Contamination
Paper and Code
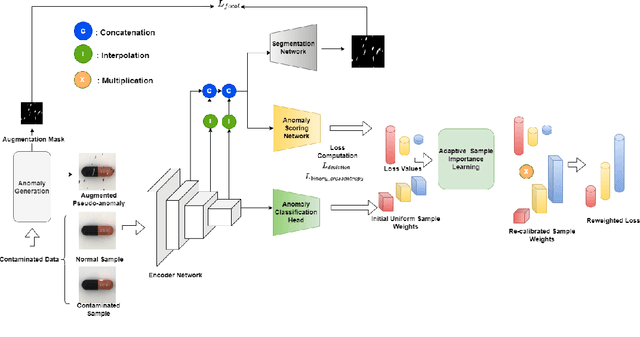


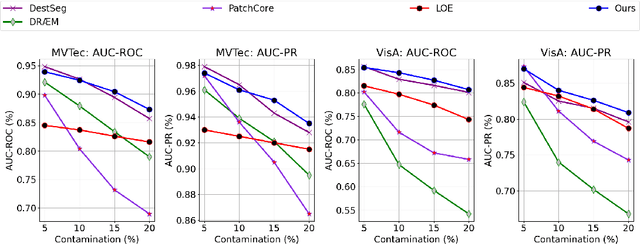
Visual anomaly detection targets to detect images that notably differ from normal pattern, and it has found extensive application in identifying defective parts within the manufacturing industry. These anomaly detection paradigms predominantly focus on training detection models using only clean, unlabeled normal samples, assuming an absence of contamination; a condition often unmet in real-world scenarios. The performance of these methods significantly depends on the quality of the data and usually decreases when exposed to noise. We introduce a systematic adaptive method that employs deviation learning to compute anomaly scores end-to-end while addressing data contamination by assigning relative importance to the weights of individual instances. In this approach, the anomaly scores for normal instances are designed to approximate scalar scores obtained from the known prior distribution. Meanwhile, anomaly scores for anomaly examples are adjusted to exhibit statistically significant deviations from these reference scores. Our approach incorporates a constrained optimization problem within the deviation learning framework to update instance weights, resolving this problem for each mini-batch. Comprehensive experiments on the MVTec and VisA benchmark datasets indicate that our proposed method surpasses competing techniques and exhibits both stability and robustness in the presence of data contamination.