 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Image-to-Text and Text-to-Image Synthesis
Paper and Code
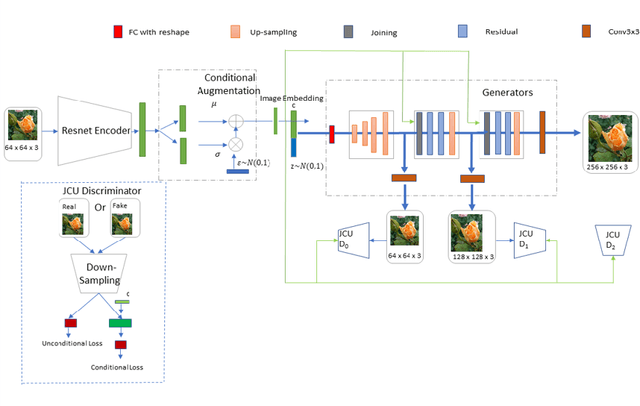

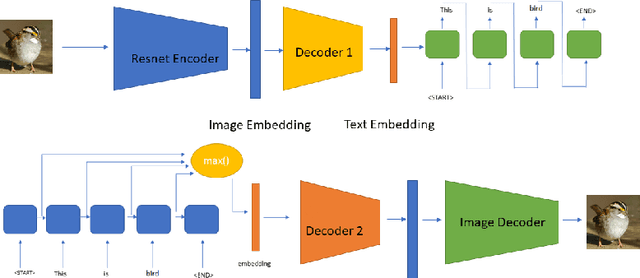
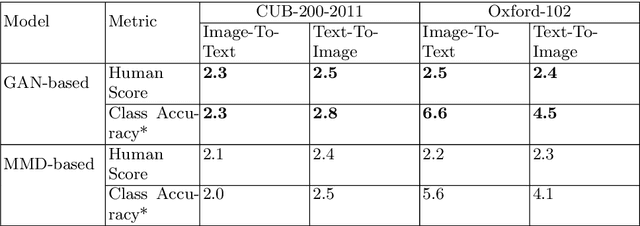
A comprehensive understanding of vision and language and their interrelation are crucial to realize the underlying similarities and differences between these modalities and to learn more generalized, meaningful representations. In recent years, most of the works related to Text-to-Image synthesis and Image-to-Text generation, focused on supervised generative deep architectures to solve the problems, where very little interest was placed on learning the similarities between the embedding spaces across modalities. In this paper, we propose a novel self-supervised deep learning based approach towards learning the cross-modal embedding spaces; for both image to text and text to image generations. In our approach, we first obtain dense vector representations of images using StackGAN-based autoencoder model and also dense vector representations on sentence-level utilizing LSTM based text-autoencoder; then we study the mapping from embedding space of one modality to embedding space of the other modality utilizing GAN and maximum mean discrepancy based generative networks. We, also demonstrate that our model learns to generate textual description from image data as well as images from textual data both qualitatively and quantitatively.