 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePort-Hamiltonian Approach to Neural Network Training
Sep 06, 2019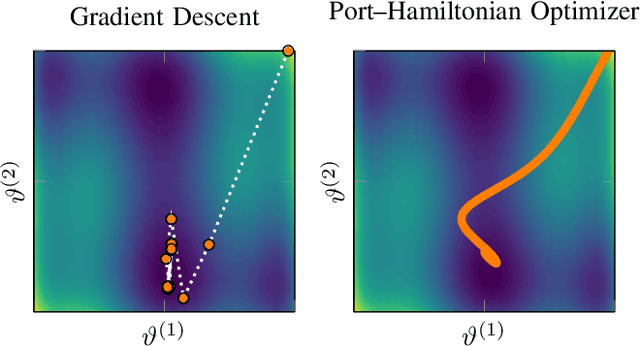
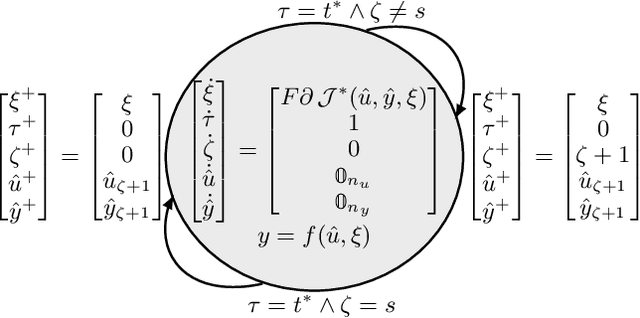
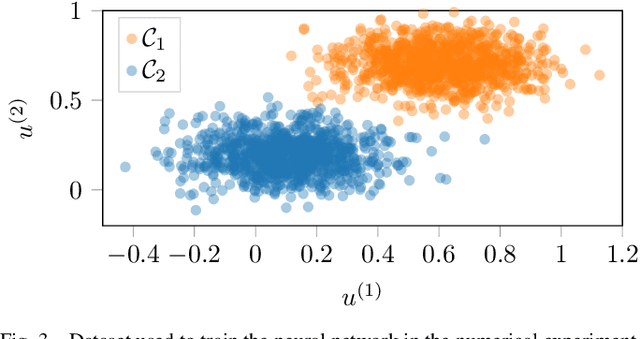

Neural networks are discrete entities: subdivided into discrete layers and parametrized by weights which are iteratively optimized via difference equations. Recent work proposes networks with layer outputs which are no longer quantized but are solutions of an ordinary differential equation (ODE); however, these networks are still optimized via discrete methods (e.g. gradient descent). In this paper, we explore a different direction: namely, we propose a novel framework for learning in which the parameters themselves are solutions of ODEs. By viewing the optimization process as the evolution of a port-Hamiltonian system, we can ensure convergence to a minimum of the objective function. Numerical experiments have been performed to show the validity and effectiveness of the proposed methods.