 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs this Harmful? Learning to Predict Harmfulness Ratings from Video
Jun 15, 2021


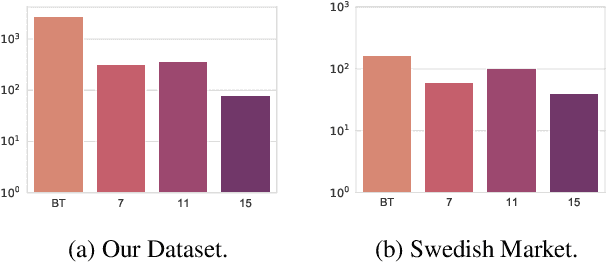
Automatically identifying harmful content in video is an important task with a wide range of applications. However, due to the difficulty of collecting high-quality labels as well as demanding computational requirements, the task has not had a satisfying general approach. Typically, only small subsets of the problem are considered, such as identifying violent content. In cases where the general problem is tackled, rough approximations and simplifications are made to deal with the lack of labels and computational complexity. In this work, we identify and tackle the two main obstacles. First, we create a dataset of approximately 4000 video clips, annotated by professionals in the field. Secondly, we demonstrate that advances in video recognition enable training models on our dataset that consider the full context of the scene. We conduct an in-depth study on our modeling choices and find that we greatly benefit from combining the visual and audio modality and that pretraining on large-scale video recognition datasets and class balanced sampling further improves performance. We additionally perform a qualitative study that reveals the heavily multi-modal nature of our dataset. Our dataset will be made available upon publication.