 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Risk-averse Human-AI Hybrid Teams
Mar 13, 2024



We anticipate increased instances of humans and AI systems working together in what we refer to as a hybrid team. The increase in collaboration is expected as AI systems gain proficiency and their adoption becomes more widespread. However, their behavior is not error-free, making hybrid teams a very suitable solution. As such, we consider methods for improving performance for these teams of humans and AI systems. For hybrid teams, we will refer to both the humans and AI systems as agents. To improve team performance over that seen for agents operating individually, we propose a manager which learns, through a standard Reinforcement Learning scheme, how to best delegate, over time, the responsibility of taking a decision to any of the agents. We further guide the manager's learning so they also minimize how many changes in delegation are made resulting from undesirable team behavior. We demonstrate the optimality of our manager's performance in several grid environments which include failure states which terminate an episode and should be avoided. We perform our experiments with teams of agents with varying degrees of acceptable risk, in the form of proximity to a failure state, and measure the manager's ability to make effective delegation decisions with respect to its own risk-based constraints, then compare these to the optimal decisions. Our results show our manager can successfully learn desirable delegations which result in team paths near/exactly optimal with respect to path length and number of delegations.
Optimizing Delegation in Collaborative Human-AI Hybrid Teams
Feb 08, 2024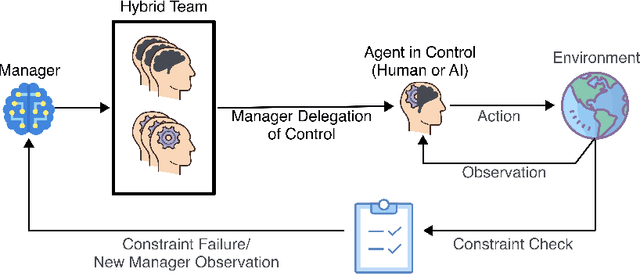

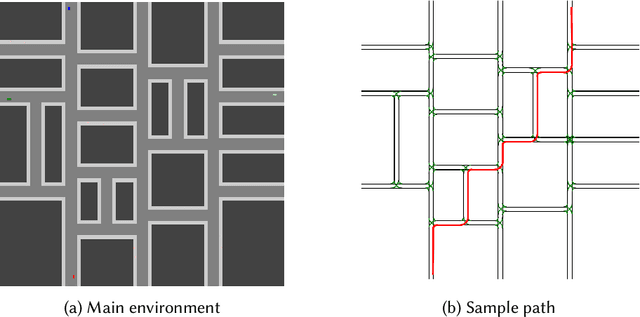

When humans and autonomous systems operate together as what we refer to as a hybrid team, we of course wish to ensure the team operates successfully and effectively. We refer to team members as agents. In our proposed framework, we address the case of hybrid teams in which, at any time, only one team member (the control agent) is authorized to act as control for the team. To determine the best selection of a control agent, we propose the addition of an AI manager (via Reinforcement Learning) which learns as an outside observer of the team. The manager learns a model of behavior linking observations of agent performance and the environment/world the team is operating in, and from these observations makes the most desirable selection of a control agent. We restrict the manager task by introducing a set of constraints. The manager constraints indicate acceptable team operation, so a violation occurs if the team enters a condition which is unacceptable and requires manager intervention. To ensure minimal added complexity or potential inefficiency for the team, the manager should attempt to minimize the number of times the team reaches a constraint violation and requires subsequent manager intervention. Therefore our manager is optimizing its selection of authorized agents to boost overall team performance while minimizing the frequency of manager intervention. We demonstrate our manager performance in a simulated driving scenario representing the case of a hybrid team of agents composed of a human driver and autonomous driving system. We perform experiments for our driving scenario with interfering vehicles, indicating the need for collision avoidance and proper speed control. Our results indicate a positive impact of our manager, with some cases resulting in increased team performance up to ~187% that of the best solo agent performance.
Optimizing delegation between human and AI collaborative agents
Sep 26, 2023



In the context of humans operating with artificial or autonomous agents in a hybrid team, it is essential to accurately identify when to authorize those team members to perform actions. Given past examples where humans and autonomous systems can either succeed or fail at tasks, we seek to train a delegating manager agent to make delegation decisions with respect to these potential performance deficiencies. Additionally, we cannot always expect the various agents to operate within the same underlying model of the environment. It is possible to encounter cases where the actions and transitions would vary between agents. Therefore, our framework provides a manager model which learns through observations of team performance without restricting agents to matching dynamics. Our results show our manager learns to perform delegation decisions with teams of agents operating under differing representations of the environment, significantly outperforming alternative methods to manage the team.
Compensating for Sensing Failures via Delegation in Human-AI Hybrid Systems
Mar 17, 2023
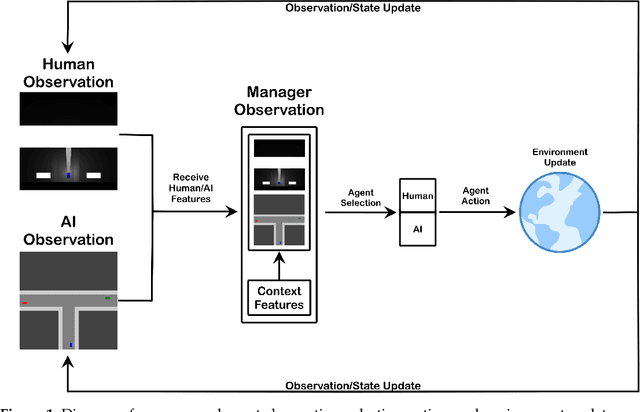

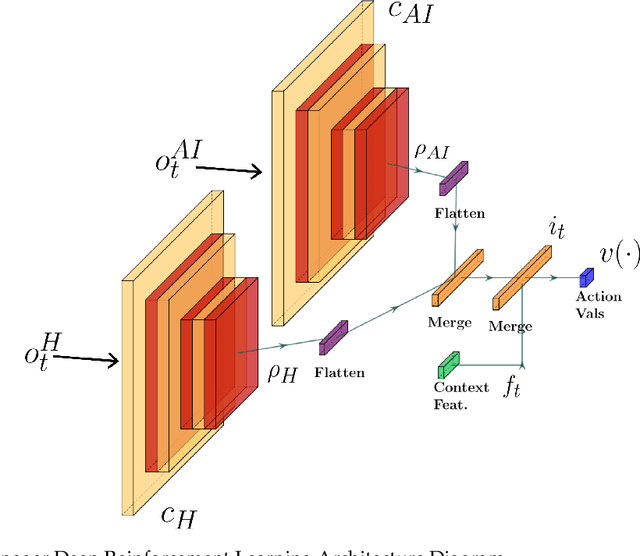
Given an increasing prevalence of intelligent systems capable of autonomous actions or augmenting human activities, it is important to consider scenarios in which the human, autonomous system, or both can exhibit failures as a result of one of several contributing factors (e.g. perception). Failures for either humans or autonomous agents can lead to simply a reduced performance level, or a failure can lead to something as severe as injury or death. For our topic, we consider the hybrid human-AI teaming case where a managing agent is tasked with identifying when to perform a delegation assignment and whether the human or autonomous system should gain control. In this context, the manager will estimate its best action based on the likelihood of either (human, autonomous) agent failure as a result of their sensing capabilities and possible deficiencies. We model how the environmental context can contribute to, or exacerbate, the sensing deficiencies. These contexts provide cases where the manager must learn to attribute capabilities to suitability for decision-making. As such, we demonstrate how a Reinforcement Learning (RL) manager can correct the context-delegation association and assist the hybrid team of agents in outperforming the behavior of any agent working in isolation.
Modeling Human Behavior Part I -- Learning and Belief Approaches
May 13, 2022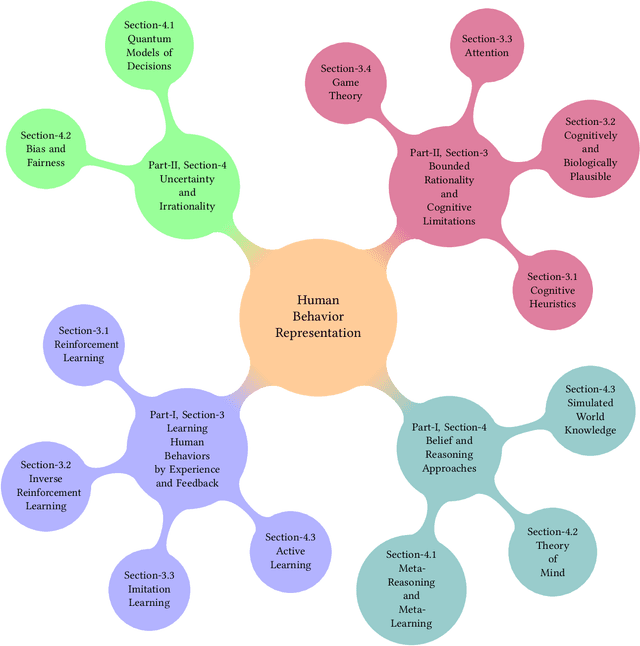

There is a clear desire to model and comprehend human behavior. Trends in research covering this topic show a clear assumption that many view human reasoning as the presupposed standard in artificial reasoning. As such, topics such as game theory, theory of mind, machine learning, etc. all integrate concepts which are assumed components of human reasoning. These serve as techniques to attempt to both replicate and understand the behaviors of humans. In addition, next generation autonomous and adaptive systems will largely include AI agents and humans working together as teams. To make this possible, autonomous agents will require the ability to embed practical models of human behavior, which allow them not only to replicate human models as a technique to "learn", but to to understand the actions of users and anticipate their behavior, so as to truly operate in symbiosis with them. The main objective of this paper it to provide a succinct yet systematic review of the most important approaches in two areas dealing with quantitative models of human behaviors. Specifically, we focus on (i) techniques which learn a model or policy of behavior through exploration and feedback, such as Reinforcement Learning, and (ii) directly model mechanisms of human reasoning, such as beliefs and bias, without going necessarily learning via trial-and-error.
Modeling Human Behavior Part II -- Cognitive approaches and Uncertainty
May 13, 2022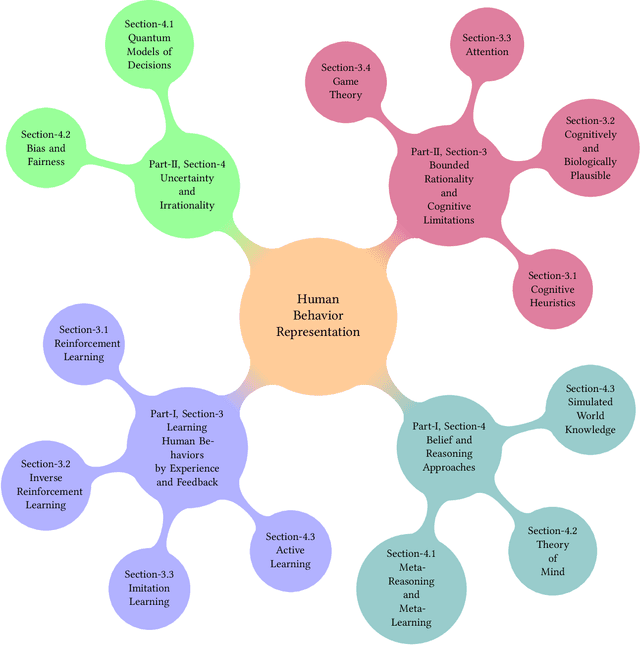
As we discussed in Part I of this topic, there is a clear desire to model and comprehend human behavior. Given the popular presupposition of human reasoning as the standard for learning and decision-making, there have been significant efforts and a growing trend in research to replicate these innate human abilities in artificial systems. In Part I, we discussed learning methods which generate a model of behavior from exploration of the system and feedback based on the exhibited behavior as well as topics relating to the use of or accounting for beliefs with respect to applicable skills or mental states of others. In this work, we will continue the discussion from the perspective of methods which focus on the assumed cognitive abilities, limitations, and biases demonstrated in human reasoning. We will arrange these topics as follows (i) methods such as cognitive architectures, cognitive heuristics, and related which demonstrate assumptions of limitations on cognitive resources and how that impacts decisions and (ii) methods which generate and utilize representations of bias or uncertainty to model human decision-making or the future outcomes of decisions.
A Cognitive Framework for Delegation Between Error-Prone AI and Human Agents
Apr 06, 2022
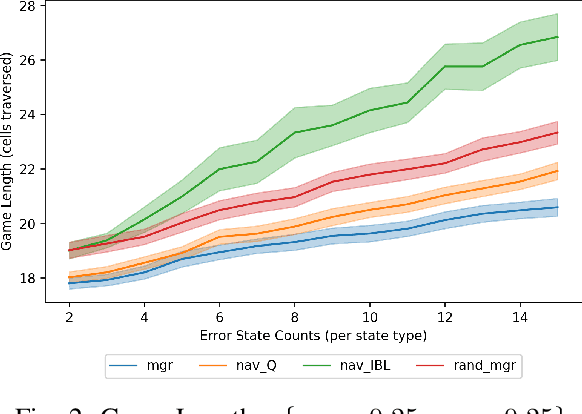
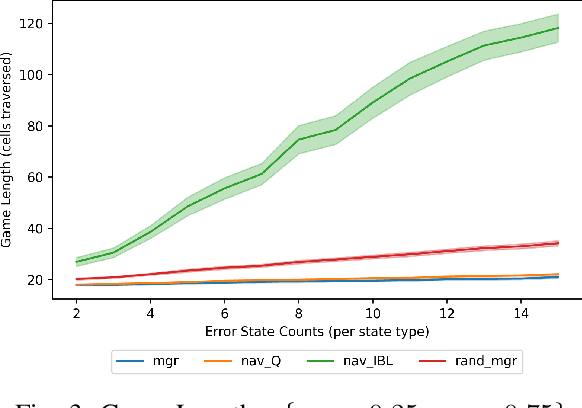
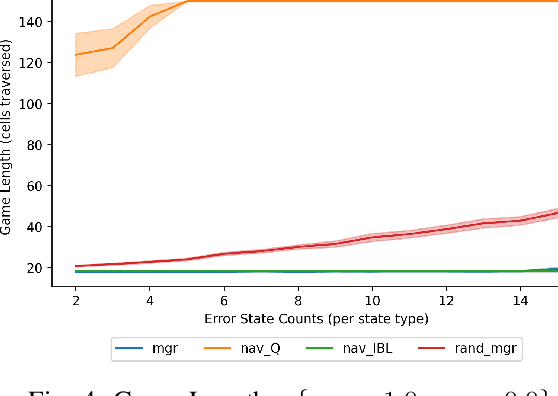
With humans interacting with AI-based systems at an increasing rate, it is necessary to ensure the artificial systems are acting in a manner which reflects understanding of the human. In the case of humans and artificial AI agents operating in the same environment, we note the significance of comprehension and response to the actions or capabilities of a human from an agent's perspective, as well as the possibility to delegate decisions either to humans or to agents, depending on who is deemed more suitable at a certain point in time. Such capabilities will ensure an improved responsiveness and utility of the entire human-AI system. To that end, we investigate the use of cognitively inspired models of behavior to predict the behavior of both human and AI agents. The predicted behavior, and associated performance with respect to a certain goal, is used to delegate control between humans and AI agents through the use of an intermediary entity. As we demonstrate, this allows overcoming potential shortcomings of either humans or agents in the pursuit of a goal.
Theory of Mind for Deep Reinforcement Learning in Hanabi
Jan 22, 2021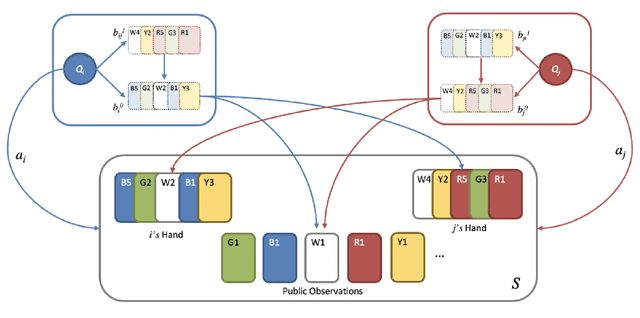

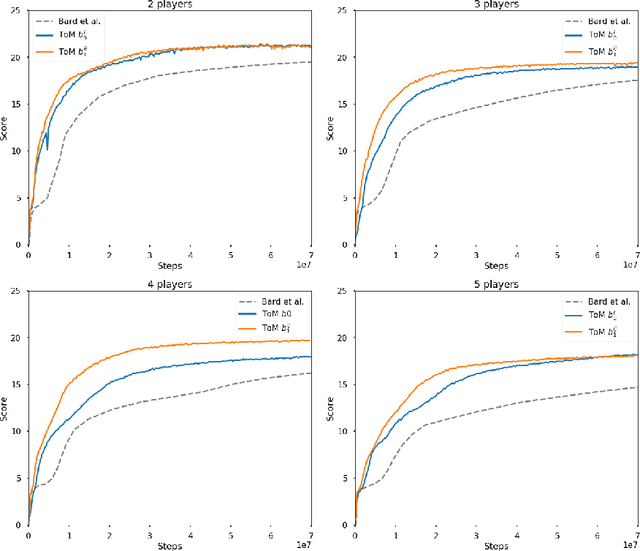
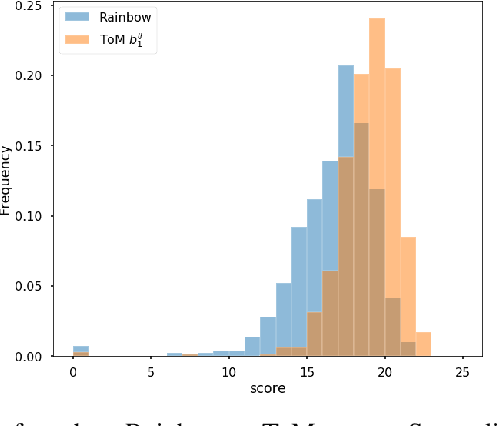
The partially observable card game Hanabi has recently been proposed as a new AI challenge problem due to its dependence on implicit communication conventions and apparent necessity of theory of mind reasoning for efficient play. In this work, we propose a mechanism for imbuing Reinforcement Learning agents with a theory of mind to discover efficient cooperative strategies in Hanabi. The primary contributions of this work are threefold: First, a formal definition of a computationally tractable mechanism for computing hand probabilities in Hanabi. Second, an extension to conventional Deep Reinforcement Learning that introduces reasoning over finitely nested theory of mind belief hierarchies. Finally, an intrinsic reward mechanism enabled by theory of mind that incentivizes agents to share strategically relevant private knowledge with their teammates. We demonstrate the utility of our algorithm against Rainbow, a state-of-the-art Reinforcement Learning agent.