 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Novelty in the Military Domain
Feb 23, 2023A critical factor in utilizing agents with Artificial Intelligence (AI) is their robustness to novelty. AI agents include models that are either engineered or trained. Engineered models include knowledge of those aspects of the environment that are known and considered important by the engineers. Learned models form embeddings of aspects of the environment based on connections made through the training data. In operation, however, a rich environment is likely to present challenges not seen in training sets or accounted for in engineered models. Worse still, adversarial environments are subject to change by opponents. A program at the Defense Advanced Research Project Agency (DARPA) seeks to develop the science necessary to develop and evaluate agents that are robust to novelty. This capability will be required, before AI has the role envisioned within mission critical environments. As part of the Science of AI and Learning for Open-world Novelty (SAIL-ON), we are mapping possible military domain novelty types to a domain-independent ontology developed as part of a theory of novelty. Characterizing the possible space of novelty mathematically and ontologically will allow us to experiment with agent designs that are coming from the DARPA SAIL-ON program in relevant military environments. Utilizing the same techniques as being used in laboratory experiments, we will be able to measure agent ability to detect, characterize, and accommodate novelty.
Theory of Mind for Deep Reinforcement Learning in Hanabi
Jan 22, 2021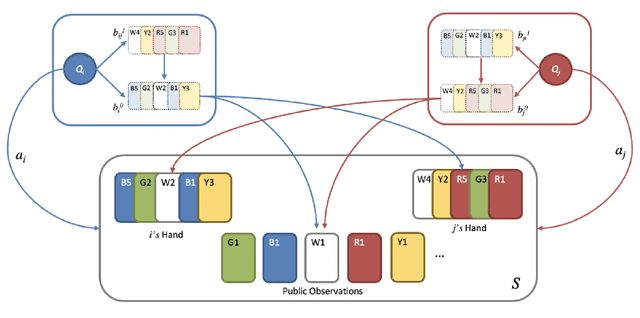

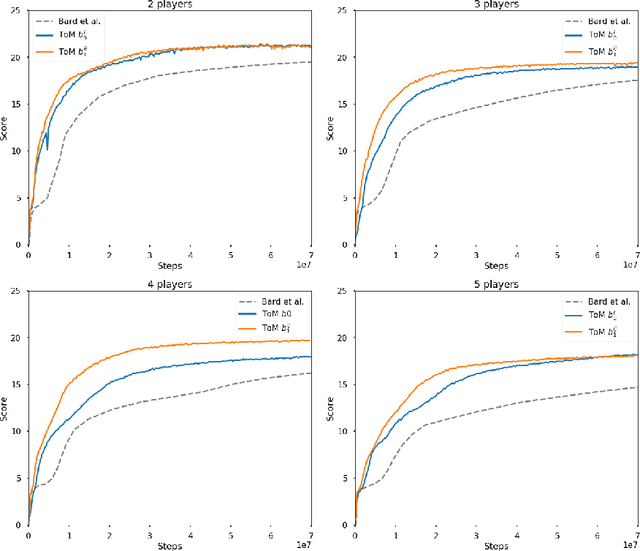
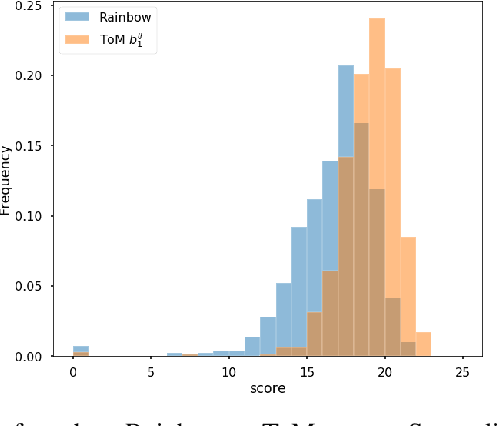
The partially observable card game Hanabi has recently been proposed as a new AI challenge problem due to its dependence on implicit communication conventions and apparent necessity of theory of mind reasoning for efficient play. In this work, we propose a mechanism for imbuing Reinforcement Learning agents with a theory of mind to discover efficient cooperative strategies in Hanabi. The primary contributions of this work are threefold: First, a formal definition of a computationally tractable mechanism for computing hand probabilities in Hanabi. Second, an extension to conventional Deep Reinforcement Learning that introduces reasoning over finitely nested theory of mind belief hierarchies. Finally, an intrinsic reward mechanism enabled by theory of mind that incentivizes agents to share strategically relevant private knowledge with their teammates. We demonstrate the utility of our algorithm against Rainbow, a state-of-the-art Reinforcement Learning agent.