 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scalable Multi-View Reconstruction of Geometry and Materials
Jun 06, 2023In this paper, we propose a novel method for joint recovery of camera pose, object geometry and spatially-varying Bidirectional Reflectance Distribution Function (svBRDF) of 3D scenes that exceed object-scale and hence cannot be captured with stationary light stages. The input are high-resolution RGB-D images captured by a mobile, hand-held capture system with point lights for active illumination. Compared to previous works that jointly estimate geometry and materials from a hand-held scanner, we formulate this problem using a single objective function that can be minimized using off-the-shelf gradient-based solvers. To facilitate scalability to large numbers of observation views and optimization variables, we introduce a distributed optimization algorithm that reconstructs 2.5D keyframe-based representations of the scene. A novel multi-view consistency regularizer effectively synchronizes neighboring keyframes such that the local optimization results allow for seamless integration into a globally consistent 3D model. We provide a study on the importance of each component in our formulation and show that our method compares favorably to baselines. We further demonstrate that our method accurately reconstructs various objects and materials and allows for expansion to spatially larger scenes. We believe that this work represents a significant step towards making geometry and material estimation from hand-held scanners scalable.
Probabilistic Compositional Embeddings for Multimodal Image Retrieval
Apr 12, 2022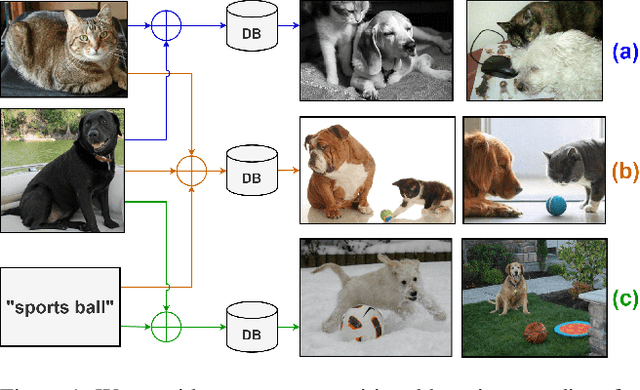
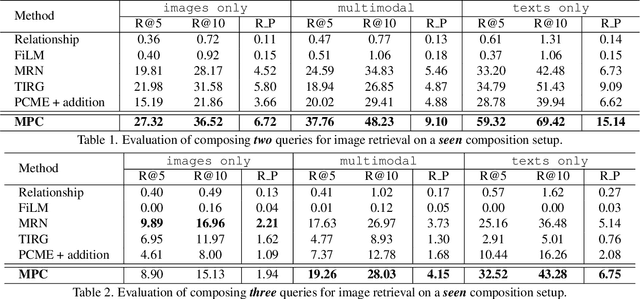


Existing works in image retrieval often consider retrieving images with one or two query inputs, which do not generalize to multiple queries. In this work, we investigate a more challenging scenario for composing multiple multimodal queries in image retrieval. Given an arbitrary number of query images and (or) texts, our goal is to retrieve target images containing the semantic concepts specified in multiple multimodal queries. To learn an informative embedding that can flexibly encode the semantics of various queries, we propose a novel multimodal probabilistic composer (MPC). Specifically, we model input images and texts as probabilistic embeddings, which can be further composed by a probabilistic composition rule to facilitate image retrieval with multiple multimodal queries. We propose a new benchmark based on the MS-COCO dataset and evaluate our model on various setups that compose multiple images and (or) text queries for multimodal image retrieval. Without bells and whistles, we show that our probabilistic model formulation significantly outperforms existing related methods on multimodal image retrieval while generalizing well to query with different amounts of inputs given in arbitrary visual and (or) textual modalities. Code is available here: https://github.com/andreineculai/MPC.