 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuccessive Convex Approximation for Phase Retrieval with Dictionary Learning
Sep 13, 2021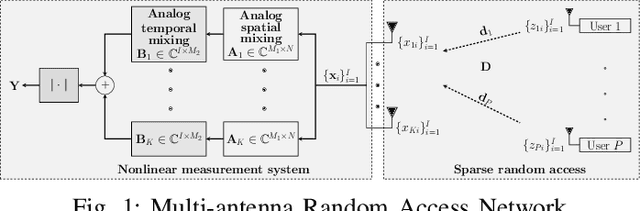


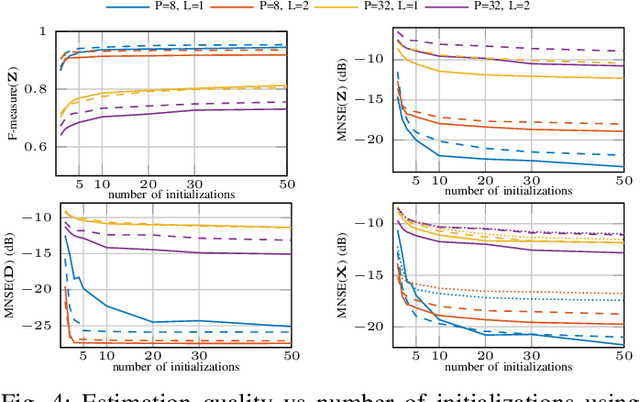
Phase retrieval aims at reconstructing unknown signals from magnitude measurements of linear mixtures. In this paper, we consider the phase retrieval with dictionary learning problem, which includes an additional prior information that the measured signal admits a sparse representation over an unknown dictionary. The task is to jointly estimate the dictionary and the sparse representation from magnitude-only measurements. To this end, we study two complementary formulations and propose efficient parallel algorithms based on the successive convex approximation framework. The first algorithm is termed compact-SCAphase and is preferable in the case of less diverse mixture models. It employs a compact formulation that avoids the use of auxiliary variables. The proposed algorithm is highly scalable and has reduced parameter tuning cost. The second algorithm, referred to as SCAphase, uses auxiliary variables and is favorable in the case of highly diverse mixture models. It also renders simple incorporation of additional side constraints. The performance of both methods is evaluated when applied to blind sparse channel estimation from subband magnitude measurements in a multi-antenna random access network. Simulation results demonstrate the efficiency of the proposed techniques compared to state-of-the-art methods.
DOLPHIn - Dictionary Learning for Phase Retrieval
Aug 03, 2016



We propose a new algorithm to learn a dictionary for reconstructing and sparsely encoding signals from measurements without phase. Specifically, we consider the task of estimating a two-dimensional image from squared-magnitude measurements of a complex-valued linear transformation of the original image. Several recent phase retrieval algorithms exploit underlying sparsity of the unknown signal in order to improve recovery performance. In this work, we consider such a sparse signal prior in the context of phase retrieval, when the sparsifying dictionary is not known in advance. Our algorithm jointly reconstructs the unknown signal - possibly corrupted by noise - and learns a dictionary such that each patch of the estimated image can be sparsely represented. Numerical experiments demonstrate that our approach can obtain significantly better reconstructions for phase retrieval problems with noise than methods that cannot exploit such "hidden" sparsity. Moreover, on the theoretical side, we provide a convergence result for our method.
On the Computational Intractability of Exact and Approximate Dictionary Learning
Aug 03, 2014The efficient sparse coding and reconstruction of signal vectors via linear observations has received a tremendous amount of attention over the last decade. In this context, the automated learning of a suitable basis or overcomplete dictionary from training data sets of certain signal classes for use in sparse representations has turned out to be of particular importance regarding practical signal processing applications. Most popular dictionary learning algorithms involve NP-hard sparse recovery problems in each iteration, which may give some indication about the complexity of dictionary learning but does not constitute an actual proof of computational intractability. In this technical note, we show that learning a dictionary with which a given set of training signals can be represented as sparsely as possible is indeed NP-hard. Moreover, we also establish hardness of approximating the solution to within large factors of the optimal sparsity level. Furthermore, we give NP-hardness and non-approximability results for a recent dictionary learning variation called the sensor permutation problem. Along the way, we also obtain a new non-approximability result for the classical sparse recovery problem from compressed sensing.