 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Column Generation by a Machine-Learning-Based Pricing Heuristic for Graph Coloring
Dec 08, 2021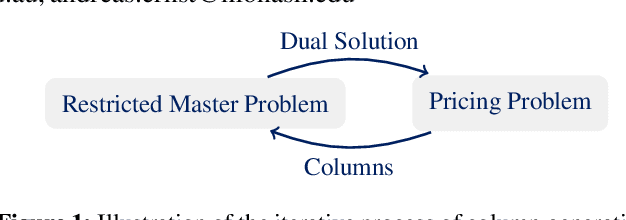


Column Generation (CG) is an effective method for solving large-scale optimization problems. CG starts by solving a sub-problem with a subset of columns (i.e., variables) and gradually includes new columns that can improve the solution of the current subproblem. The new columns are generated as needed by repeatedly solving a pricing problem, which is often NP-hard and is a bottleneck of the CG approach. To tackle this, we propose a Machine-Learning-based Pricing Heuristic (MLPH)that can generate many high-quality columns efficiently. In each iteration of CG, our MLPH leverages an ML model to predict the optimal solution of the pricing problem, which is then used to guide a sampling method to efficiently generate multiple high-quality columns. Using the graph coloring problem, we empirically show that MLPH significantly enhancesCG as compared to six state-of-the-art methods, and the improvement in CG can lead to substantially better performance of the branch-and-price exact method.
Generalization of Machine Learning for Problem Reduction: A Case Study on Travelling Salesman Problems
May 12, 2020
Combinatorial optimization plays an important role in real-world problem solving. In the big data era, the dimensionality of a combinatorial optimization problem is usually very large, which poses a significant challenge to existing solution methods. In this paper, we examine the generalization capability of a machine learning model for problem reduction on the classic traveling salesman problems (TSP). We demonstrate that our method can greedily remove decision variables from an optimization problem that are predicted not to be part of an optimal solution. More specifically, we investigate our model's capability to generalize on test instances that have not been seen during the training phase. We consider three scenarios where training and test instances are different in terms of: 1) problem characteristics; 2) problem sizes; and 3) problem types. Our experiments show that this machine learning based technique can generalize reasonably well over a wide range of TSP test instances with different characteristics or sizes. While the accuracy of predicting unused variables naturally deteriorates the further an instance is from the training set, we observe that even when solving a different TSP problem variant than was used in the training, the machine learning model still makes useful predictions about which variables can be eliminated without significantly impacting solution quality.