 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-AD: Large Language Model based Audio Description System
May 02, 2024The development of Audio Description (AD) has been a pivotal step forward in making video content more accessible and inclusive. Traditionally, AD production has demanded a considerable amount of skilled labor, while existing automated approaches still necessitate extensive training to integrate multimodal inputs and tailor the output from a captioning style to an AD style. In this paper, we introduce an automated AD generation pipeline that harnesses the potent multimodal and instruction-following capacities of GPT-4V(ision). Notably, our methodology employs readily available components, eliminating the need for additional training. It produces ADs that not only comply with established natural language AD production standards but also maintain contextually consistent character information across frames, courtesy of a tracking-based character recognition module. A thorough analysis on the MAD dataset reveals that our approach achieves a performance on par with learning-based methods in automated AD production, as substantiated by a CIDEr score of 20.5.
RefineVIS: Video Instance Segmentation with Temporal Attention Refinement
Jun 07, 2023We introduce a novel framework called RefineVIS for Video Instance Segmentation (VIS) that achieves good object association between frames and accurate segmentation masks by iteratively refining the representations using sequence context. RefineVIS learns two separate representations on top of an off-the-shelf frame-level image instance segmentation model: an association representation responsible for associating objects across frames and a segmentation representation that produces accurate segmentation masks. Contrastive learning is utilized to learn temporally stable association representations. A Temporal Attention Refinement (TAR) module learns discriminative segmentation representations by exploiting temporal relationships and a novel temporal contrastive denoising technique. Our method supports both online and offline inference. It achieves state-of-the-art video instance segmentation accuracy on YouTube-VIS 2019 (64.4 AP), Youtube-VIS 2021 (61.4 AP), and OVIS (46.1 AP) datasets. The visualization shows that the TAR module can generate more accurate instance segmentation masks, particularly for challenging cases such as highly occluded objects.
Consistent Video Instance Segmentation with Inter-Frame Recurrent Attention
Jun 14, 2022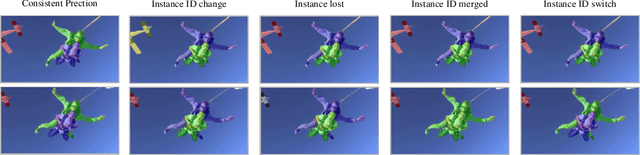
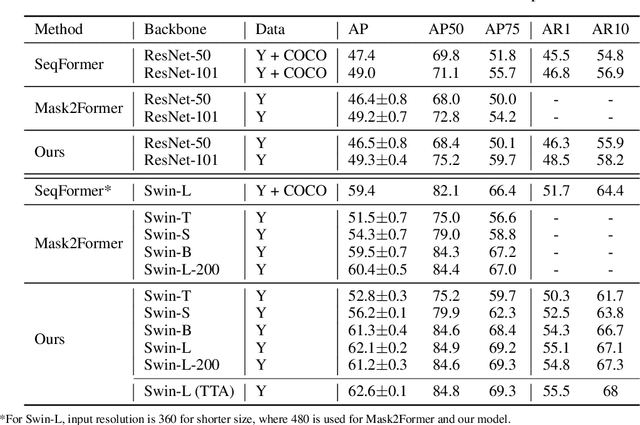
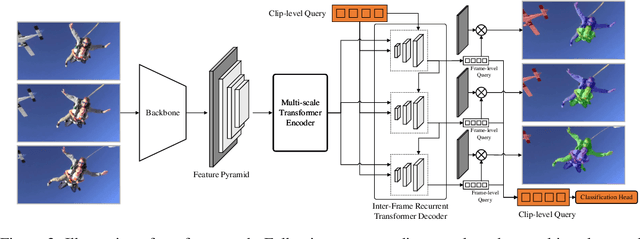
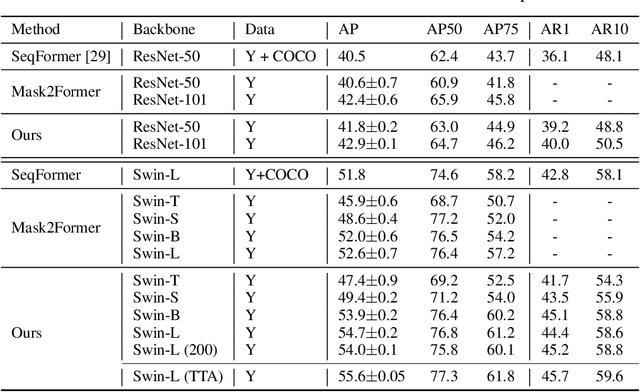
Video instance segmentation aims at predicting object segmentation masks for each frame, as well as associating the instances across multiple frames. Recent end-to-end video instance segmentation methods are capable of performing object segmentation and instance association together in a direct parallel sequence decoding/prediction framework. Although these methods generally predict higher quality object segmentation masks, they can fail to associate instances in challenging cases because they do not explicitly model the temporal instance consistency for adjacent frames. We propose a consistent end-to-end video instance segmentation framework with Inter-Frame Recurrent Attention to model both the temporal instance consistency for adjacent frames and the global temporal context. Our extensive experiments demonstrate that the Inter-Frame Recurrent Attention significantly improves temporal instance consistency while maintaining the quality of the object segmentation masks. Our model achieves state-of-the-art accuracy on both YouTubeVIS-2019 (62.1\%) and YouTubeVIS-2021 (54.7\%) datasets. In addition, quantitative and qualitative results show that the proposed methods predict more temporally consistent instance segmentation masks.