 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRiemannian generative decoder
Jun 23, 2025Riemannian representation learning typically relies on approximating densities on chosen manifolds. This involves optimizing difficult objectives, potentially harming models. To completely circumvent this issue, we introduce the Riemannian generative decoder which finds manifold-valued maximum likelihood latents with a Riemannian optimizer while training a decoder network. By discarding the encoder, we vastly simplify the manifold constraint compared to current approaches which often only handle few specific manifolds. We validate our approach on three case studies -- a synthetic branching diffusion process, human migrations inferred from mitochondrial DNA, and cells undergoing a cell division cycle -- each showing that learned representations respect the prescribed geometry and capture intrinsic non-Euclidean structure. Our method requires only a decoder, is compatible with existing architectures, and yields interpretable latent spaces aligned with data geometry.
A primer on synthetic health data
Jan 31, 2024


Recent advances in deep generative models have greatly expanded the potential to create realistic synthetic health datasets. These synthetic datasets aim to preserve the characteristics, patterns, and overall scientific conclusions derived from sensitive health datasets without disclosing patient identity or sensitive information. Thus, synthetic data can facilitate safe data sharing that supports a range of initiatives including the development of new predictive models, advanced health IT platforms, and general project ideation and hypothesis development. However, many questions and challenges remain, including how to consistently evaluate a synthetic dataset's similarity and predictive utility in comparison to the original real dataset and risk to privacy when shared. Additional regulatory and governance issues have not been widely addressed. In this primer, we map the state of synthetic health data, including generation and evaluation methods and tools, existing examples of deployment, the regulatory and ethical landscape, access and governance options, and opportunities for further development.
The deep generative decoder: Using MAP estimates of representations
Oct 13, 2021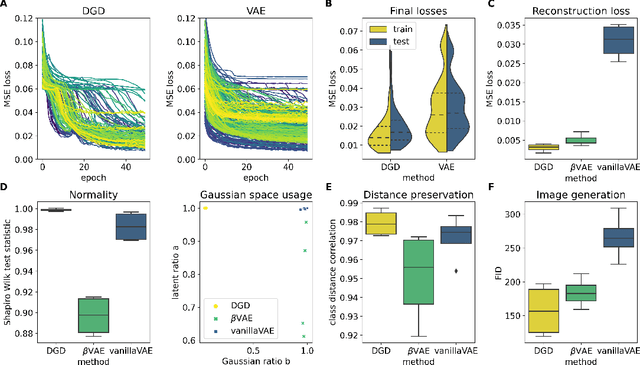


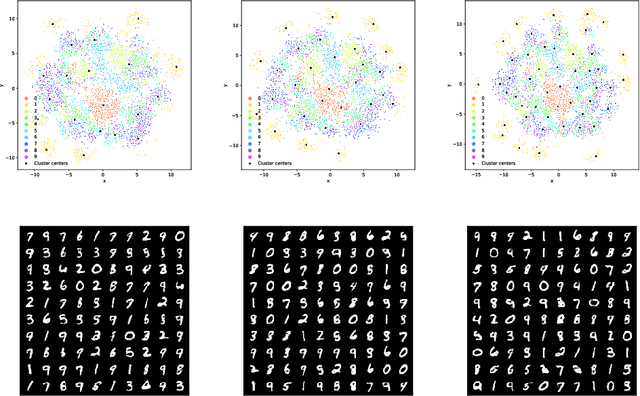
A deep generative model is characterized by a representation space, its distribution, and a neural network mapping the representation to a distribution over vectors in feature space. Common methods such as variational autoencoders (VAEs) apply variational inference for training the neural network, but optimizing these models is often non-trivial. The encoder adds to the complexity of the model and introduces an amortization gap and the quality of the variational approximation is usually unknown. Additionally, the balance of the loss terms of the objective function heavily influences performance. Therefore, we argue that it is worthwhile to investigate a much simpler approximation which finds representations and their distribution by maximizing the model likelihood via back-propagation. In this approach, there is no encoder, and we therefore call it a Deep Generative Decoder (DGD). Using the CIFAR10 data set, we show that the DGD is easier and faster to optimize than the VAE, achieves more consistent low reconstruction errors of test data, and alleviates the problem of balancing the reconstruction and distribution loss terms. Although the model in its simple form cannot compete with state-of-the-art image generation approaches, it obtains better image generation scores than the variational approach on the CIFAR10 data. We demonstrate on MNIST data how the use of a Gaussian mixture with priors can lead to a clear separation of classes in a 2D representation space, and how the DGD can be used with labels to obtain a supervised representation.
A manifold learning perspective on representation learning: Learning decoder and representations without an encoder
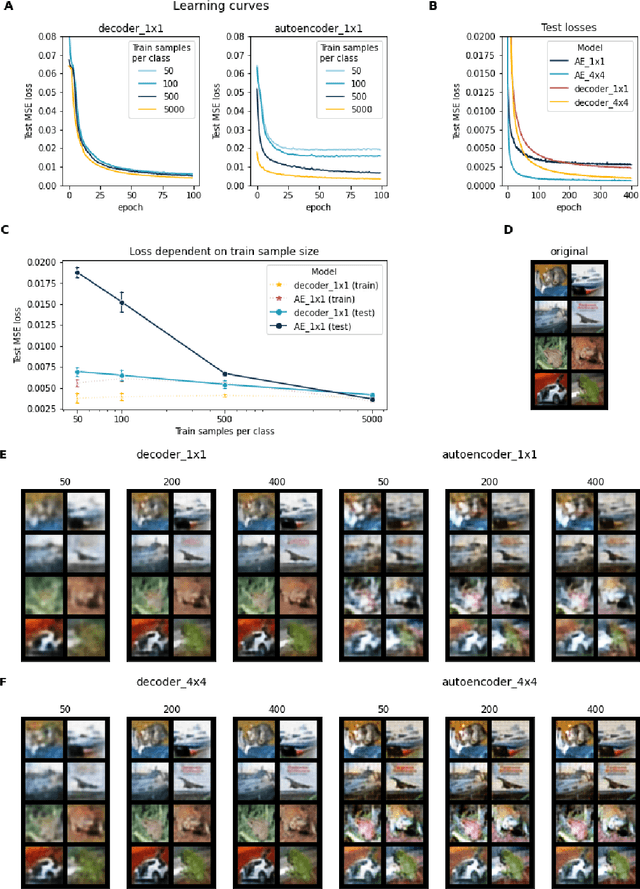
Aug 31, 2021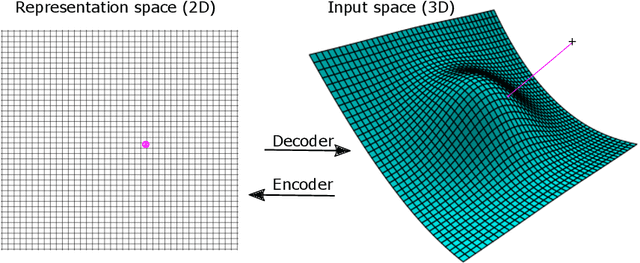


Autoencoders are commonly used in representation learning. They consist of an encoder and a decoder, which provide a straightforward way to map $n$-dimensional data in input space to a lower $m$-dimensional representation space and back. The decoder itself defines an $m$-dimensional manifold in input space. Inspired by manifold learning, we show that the decoder can be trained on its own by learning the representations of the training samples along with the decoder weights using gradient descent. A sum-of-squares loss then corresponds to optimizing the manifold to have the smallest Euclidean distance to the training samples, and similarly for other loss functions. We derive expressions for the number of samples needed to specify the encoder and decoder and show that the decoder generally requires much less training samples to be well-specified compared to the encoder. We discuss training of autoencoders in this perspective and relate to previous work in the field that use noisy training examples and other types of regularization. On the natural image data sets MNIST and CIFAR10, we demonstrate that the decoder is much better suited to learn a low-dimensional representation, especially when trained on small data sets. Using simulated gene regulatory data, we further show that the decoder alone leads to better generalization and meaningful representations. Our approach of training the decoder alone facilitates representation learning even on small data sets and can lead to improved training of autoencoders. We hope that the simple analyses presented will also contribute to an improved conceptual understanding of representation learning.