 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Orchestration Architecture for Fluid Computing: A Secure Distributed AI Use Case
Mar 12, 2026Distributed AI and IoT applications increasingly execute across heterogeneous resources spanning end devices, edge/fog infrastructure, and cloud platforms, often under different administrative domains. Fluid Computing has emerged as a promising paradigm for enhancing massive resource management across the computing continuum by treating such resources as a unified fabric, enabling optimal service-agnostic deployments driven by application requirements. However, existing solutions remain largely centralized and often do not explicitly address multi-domain considerations. This paper proposes an agnostic multi-domain orchestration architecture for fluid computing environments. The orchestration plane enables decentralized coordination among domains that maintain local autonomy while jointly realizing intent-based deployment requests from tenants, ensuring end-to-end placement and execution. To this end, the architecture elevates domain-side control services as first-class capabilities to support application-level enhancement at runtime. As a representative use case, we consider a multi-domain Decentralized Federated Learning (DFL) deployment under Byzantine threats. We leverage domain-side capabilities to enhance Byzantine security by introducing FU-HST, an SDN-enabled multi-domain anomaly detection mechanism that complements Byzantine-robust aggregation. We validate the approach via simulation in single- and multi-domain settings, evaluating anomaly detection, DFL performance, and computation/communication overhead.
Realistic Urban Traffic Generator using Decentralized Federated Learning for the SUMO simulator
Jun 09, 2025Realistic urban traffic simulation is essential for sustainable urban planning and the development of intelligent transportation systems. However, generating high-fidelity, time-varying traffic profiles that accurately reflect real-world conditions, especially in large-scale scenarios, remains a major challenge. Existing methods often suffer from limitations in accuracy, scalability, or raise privacy concerns due to centralized data processing. This work introduces DesRUTGe (Decentralized Realistic Urban Traffic Generator), a novel framework that integrates Deep Reinforcement Learning (DRL) agents with the SUMO simulator to generate realistic 24-hour traffic patterns. A key innovation of DesRUTGe is its use of Decentralized Federated Learning (DFL), wherein each traffic detector and its corresponding urban zone function as an independent learning node. These nodes train local DRL models using minimal historical data and collaboratively refine their performance by exchanging model parameters with selected peers (e.g., geographically adjacent zones), without requiring a central coordinator. Evaluated using real-world data from the city of Barcelona, DesRUTGe outperforms standard SUMO-based tools such as RouteSampler, as well as other centralized learning approaches, by delivering more accurate and privacy-preserving traffic pattern generation.
CO-DEFEND: Continuous Decentralized Federated Learning for Secure DoH-Based Threat Detection
Apr 02, 2025
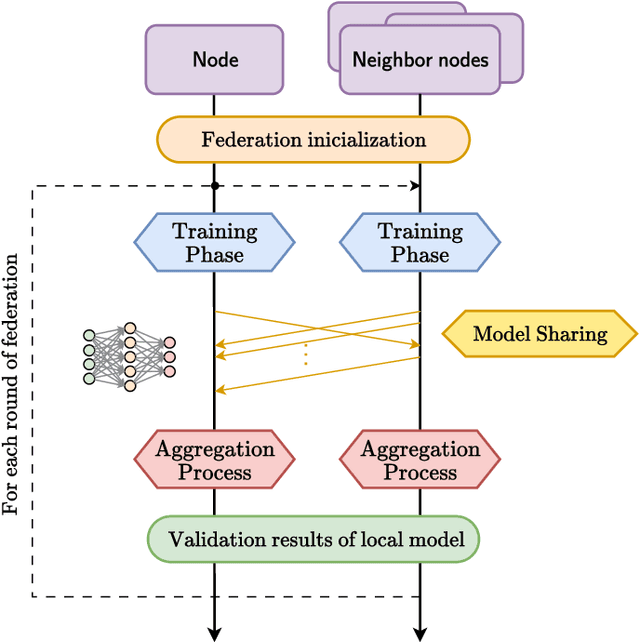


The use of DNS over HTTPS (DoH) tunneling by an attacker to hide malicious activity within encrypted DNS traffic poses a serious threat to network security, as it allows malicious actors to bypass traditional monitoring and intrusion detection systems while evading detection by conventional traffic analysis techniques. Machine Learning (ML) techniques can be used to detect DoH tunnels; however, their effectiveness relies on large datasets containing both benign and malicious traffic. Sharing such datasets across entities is challenging due to privacy concerns. In this work, we propose CO-DEFEND (Continuous Decentralized Federated Learning for Secure DoH-Based Threat Detection), a Decentralized Federated Learning (DFL) framework that enables multiple entities to collaboratively train a classification machine learning model while preserving data privacy and enhancing resilience against single points of failure. The proposed DFL framework, which is scalable and privacy-preserving, is based on a federation process that allows multiple entities to train online their local models using incoming DoH flows in real time as they are processed by the entity. In addition, we adapt four classical machine learning algorithms, Support Vector Machines (SVM), Logistic Regression (LR), Decision Trees (DT), and Random Forest (RF), for federated scenarios, comparing their results with more computationally complex alternatives such as neural networks. We compare our proposed method by using the dataset CIRA-CIC-DoHBrw-2020 with existing machine learning approaches to demonstrate its effectiveness in detecting malicious DoH tunnels and the benefits it brings.
Towards efficient compression and communication for prototype-based decentralized learning
Nov 14, 2024In prototype-based federated learning, the exchange of model parameters between clients and the master server is replaced by transmission of prototypes or quantized versions of the data samples to the aggregation server. A fully decentralized deployment of prototype-based learning, without a central agregartor of prototypes, is more robust upon network failures and reacts faster to changes in the statistical distribution of the data, suggesting potential advantages and quick adaptation in dynamic learning tasks, e.g., when the data sources are IoT devices or when data is non-iid. In this paper, we consider the problem of designing a communication-efficient decentralized learning system based on prototypes. We address the challenge of prototype redundancy by leveraging on a twofold data compression technique, i.e., sending only update messages if the prototypes are informationtheoretically useful (via the Jensen-Shannon distance), and using clustering on the prototypes to compress the update messages used in the gossip protocol. We also use parallel instead of sequential gossiping, and present an analysis of its age-of-information (AoI). Our experimental results show that, with these improvements, the communications load can be substantially reduced without decreasing the convergence rate of the learning algorithm.
Byzantine-Robust Aggregation for Securing Decentralized Federated Learning
Sep 26, 2024Federated Learning (FL) emerges as a distributed machine learning approach that addresses privacy concerns by training AI models locally on devices. Decentralized Federated Learning (DFL) extends the FL paradigm by eliminating the central server, thereby enhancing scalability and robustness through the avoidance of a single point of failure. However, DFL faces significant challenges in optimizing security, as most Byzantine-robust algorithms proposed in the literature are designed for centralized scenarios. In this paper, we present a novel Byzantine-robust aggregation algorithm to enhance the security of Decentralized Federated Learning environments, coined WFAgg. This proposal handles the adverse conditions and strength robustness of dynamic decentralized topologies at the same time by employing multiple filters to identify and mitigate Byzantine attacks. Experimental results demonstrate the effectiveness of the proposed algorithm in maintaining model accuracy and convergence in the presence of various Byzantine attack scenarios, outperforming state-of-the-art centralized Byzantine-robust aggregation schemes (such as Multi-Krum or Clustering). These algorithms are evaluated on an IID image classification problem in both centralized and decentralized scenarios.
Decentralised and collaborative machine learning framework for IoT
Dec 19, 2023Decentralised machine learning has recently been proposed as a potential solution to the security issues of the canonical federated learning approach. In this paper, we propose a decentralised and collaborative machine learning framework specially oriented to resource-constrained devices, usual in IoT deployments. With this aim we propose the following construction blocks. First, an incremental learning algorithm based on prototypes that was specifically implemented to work in low-performance computing elements. Second, two random-based protocols to exchange the local models among the computing elements in the network. Finally, two algorithmics approaches for prediction and prototype creation. This proposal was compared to a typical centralized incremental learning approach in terms of accuracy, training time and robustness with very promising results.
Multi-criteria recommendation systems to foster online grocery
Dec 12, 2023With the exponential increase in information, it has become imperative to design mechanisms that allow users to access what matters to them as quickly as possible. The recommendation system ($RS$) with information technology development is the solution, it is an intelligent system. Various types of data can be collected on items of interest to users and presented as recommendations. $RS$ also play a very important role in e-commerce. The purpose of recommending a product is to designate the most appropriate designation for a specific product. The major challenges when recommending products are insufficient information about the products and the categories to which they belong. In this paper, we transform the product data using two methods of document representation: bag-of-words (BOW) and the neural network-based document combination known as vector-based (Doc2Vec). We propose three-criteria recommendation systems (product, package, and health) for each document representation method to foster online grocery, which depends on product characteristics such as (composition, packaging, nutrition table, allergen, etc.). For our evaluation, we conducted a user and expert survey. Finally, we have compared the performance of these three criteria for each document representation method, discovering that the neural network-based (Doc2Vec) performs better and completely alters the results.
* 30 pages, 8 images, journal
Classification of retail products: From probabilistic ranking to neural networks
Dec 12, 2023Food retailing is now on an accelerated path to a success penetration into the digital market by new ways of value creation at all stages of the consumer decision process. One of the most important imperatives in this path is the availability of quality data to feed all the process in digital transformation. But the quality of data is not so obvious if we consider the variety of products and suppliers in the grocery market. Within this context of digital transformation of grocery industry, \textit{Midiadia} is Spanish data provider company that works on converting data from the retailers' products into knowledge with attributes and insights from the product labels, that is, maintaining quality data in a dynamic market with a high dispersion of products. Currently, they manually categorize products (groceries) according to the information extracted directly (text processing) from the product labelling and packaging. This paper introduces a solution to automatically categorize the constantly changing product catalogue into a 3-level food taxonomy. Our proposal studies three different approaches: a score-based ranking method, traditional machine learning algorithms, and deep neural networks. Thus, we provide four different classifiers that support a more efficient and less error-prone maintenance of groceries catalogues, the main asset of the company. Finally, we have compared the performance of these three alternatives, concluding that traditional machine learning algorithms perform better, but closely followed by the score-based approach.
* 17 pages, 8 figures, journal
Unsupervised KPIs-Based Clustering of Jobs in HPC Data Centers
Dec 11, 2023



Performance analysis is an essential task in High-Performance Computing (HPC) systems and it is applied for different purposes such as anomaly detection, optimal resource allocation, and budget planning. HPC monitoring tasks generate a huge number of Key Performance Indicators (KPIs) to supervise the status of the jobs running in these systems. KPIs give data about CPU usage, memory usage, network (interface) traffic, or other sensors that monitor the hardware. Analyzing this data, it is possible to obtain insightful information about running jobs, such as their characteristics, performance, and failures. The main contribution in this paper is to identify which metric/s (KPIs) is/are the most appropriate to identify/classify different types of jobs according to their behavior in the HPC system. With this aim, we have applied different clustering techniques (partition and hierarchical clustering algorithms) using a real dataset from the Galician Computation Center (CESGA). We have concluded that (i) those metrics (KPIs) related to the Network (interface) traffic monitoring provide the best cohesion and separation to cluster HPC jobs, and (ii) hierarchical clustering algorithms are the most suitable for this task. Our approach was validated using a different real dataset from the same HPC center.
* 22 pages, 6 figures, journal
KPIs-Based Clustering and Visualization of HPC jobs: a Feature Reduction Approach
Dec 11, 2023High-Performance Computing (HPC) systems need to be constantly monitored to ensure their stability. The monitoring systems collect a tremendous amount of data about different parameters or Key Performance Indicators (KPIs), such as resource usage, IO waiting time, etc. A proper analysis of this data, usually stored as time series, can provide insight in choosing the right management strategies as well as the early detection of issues. In this paper, we introduce a methodology to cluster HPC jobs according to their KPI indicators. Our approach reduces the inherent high dimensionality of the collected data by applying two techniques to the time series: literature-based and variance-based feature extraction. We also define a procedure to visualize the obtained clusters by combining the two previous approaches and the Principal Component Analysis (PCA). Finally, we have validated our contributions on a real data set to conclude that those KPIs related to CPU usage provide the best cohesion and separation for clustering analysis and the good results of our visualization methodology.
* 23 pages, 11 figures