 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHLF-FSL. A Decentralized Federated Split Learning Solution for IoT on Hyperledger Fabric
Jul 10, 2025Collaborative machine learning in sensitive domains demands scalable, privacy preserving solutions for enterprise deployment. Conventional Federated Learning (FL) relies on a central server, introducing single points of failure and privacy risks, while Split Learning (SL) partitions models for privacy but scales poorly due to sequential training. We present a decentralized architecture that combines Federated Split Learning (FSL) with the permissioned blockchain Hyperledger Fabric (HLF). Our chaincode orchestrates FSL's split model execution and peer-to-peer aggregation without any central coordinator, leveraging HLF's transient fields and Private Data Collections (PDCs) to keep raw data and model activations private. On CIFAR-10 and MNIST benchmarks, HLF-FSL matches centralized FSL accuracy while reducing per epoch training time compared to Ethereum-based works. Performance and scalability tests show minimal blockchain overhead and preserved accuracy, demonstrating enterprise grade viability.
Privacy-aware Berrut Approximated Coded Computing for Federated Learning
May 02, 2024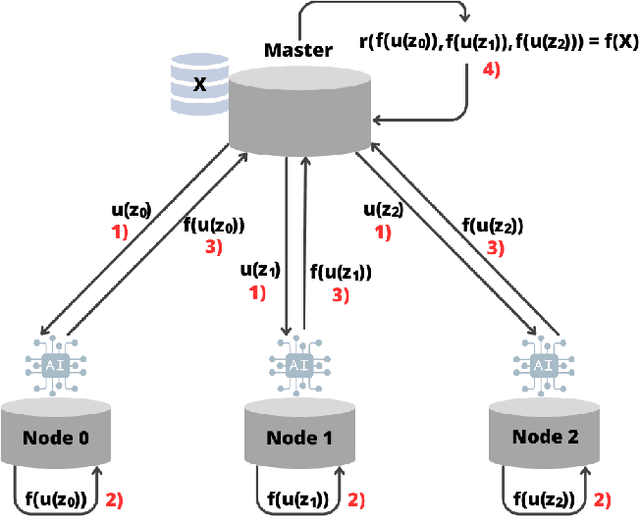
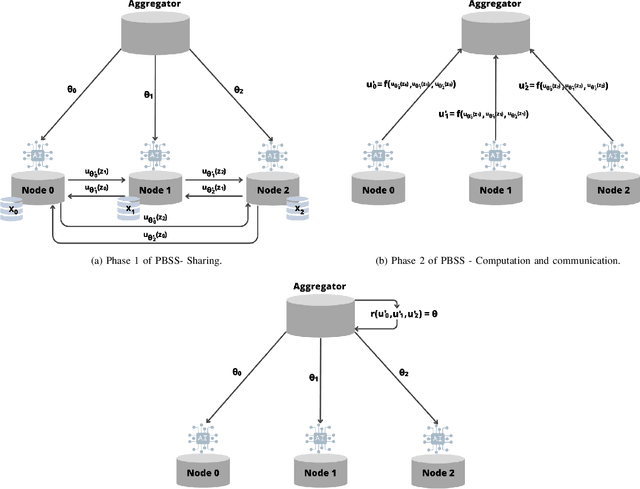
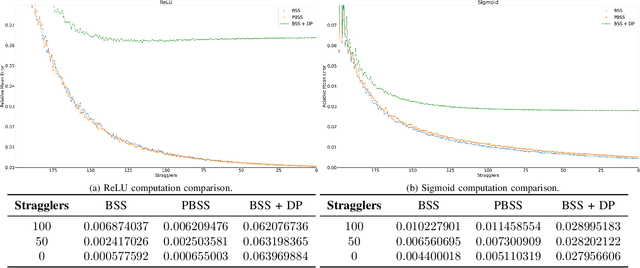
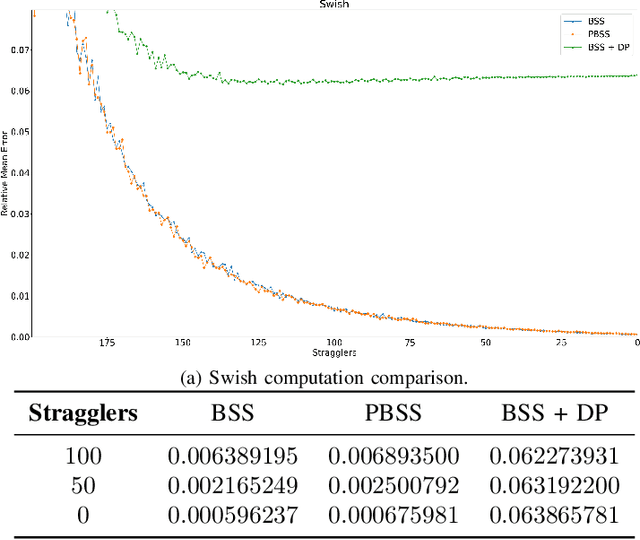
Federated Learning (FL) is an interesting strategy that enables the collaborative training of an AI model among different data owners without revealing their private datasets. Even so, FL has some privacy vulnerabilities that have been tried to be overcome by applying some techniques like Differential Privacy (DP), Homomorphic Encryption (HE), or Secure Multi-Party Computation (SMPC). However, these techniques have some important drawbacks that might narrow their range of application: problems to work with non-linear functions and to operate large matrix multiplications and high communication and computational costs to manage semi-honest nodes. In this context, we propose a solution to guarantee privacy in FL schemes that simultaneously solves the previously mentioned problems. Our proposal is based on the Berrut Approximated Coded Computing, a technique from the Coded Distributed Computing paradigm, adapted to a Secret Sharing configuration, to provide input privacy to FL in a scalable way. It can be applied for computing non-linear functions and treats the special case of distributed matrix multiplication, a key primitive at the core of many automated learning tasks. Because of these characteristics, it could be applied in a wide range of FL scenarios, since it is independent of the machine learning models or aggregation algorithms used in the FL scheme. We provide analysis of the achieve privacy and complexity of our solution and, due to the extensive numerical results performed, it can be observed a good trade-off between privacy and precision.
Twitter Permeability to financial events: an experiment towards a model for sensing irregularities
Dec 14, 2023There is a general consensus of the good sensing and novelty characteristics of Twitter as an information media for the complex financial market. This paper investigates the permeability of Twittersphere, the total universe of Twitter users and their habits, towards relevant events in the financial market. Analysis shows that a general purpose social media is permeable to financial-specific events and establishes Twitter as a relevant feeder for taking decisions regarding the financial market and event fraudulent activities in that market. However, the provenance of contributions, their different levels of credibility and quality and even the purpose or intention behind them should to be considered and carefully contemplated if Twitter is used as a single source for decision taking. With the overall aim of this research, to deploy an architecture for real-time monitoring of irregularities in the financial market, this paper conducts a series of experiments on the level of permeability and the permeable features of Twitter in the event of one of these irregularities. To be precise, Twitter data is collected concerning an event comprising of a specific financial action on the 27th January 2017:{~ }the announcement about the merge of two companies Tesco PLC and Booker Group PLC, listed in the main market of the London Stock Exchange (LSE), to create the UK's Leading Food Business. The experiment attempts to answer five key research questions which aim to characterize the features of Twitter permeability to the financial market. The experimental results confirm that a far-impacting financial event, such as the merger considered, caused apparent disturbances in all the features considered, that is, information volume, content and sentiment as well as geographical provenance. Analysis shows that despite, Twitter not being a specific financial forum, it is permeable to financial events.
Pneumonia Detection on chest X-ray images Using Ensemble of Deep Convolutional Neural Networks
Dec 13, 2023Pneumonia is a life-threatening lung infection resulting from several different viral infections. Identifying and treating pneumonia on chest X-ray images can be difficult due to its similarity to other pulmonary diseases. Thus, the existing methods for predicting pneumonia cannot attain substantial levels of accuracy. Therefore, this paper presents a computer-aided classification of pneumonia, coined as Ensemble Learning (EL), to simplify the diagnosis process on chest X-ray images. Our proposal is based on Convolutional Neural Network (CNN) models, which are pre-trained CNN models that have been recently employed to enhance the performance of many medical tasks instead of training CNN models from scratch. We propose to use three well-known CNN pre-trained (DenseNet169, MobileNetV2 and Vision Transformer) using the ImageNet database. Then, these models are trained on the chest X-ray data set using fine-tuning. Finally, the results are obtained by combining the extracted features from these three models during the experimental phase. The proposed EL approach outperforms other existing state-of-the-art methods, and it obtains an accuracy of 93.91% and a F1-Score of 93.88% on the testing phase.
* 14 pages, 4 figures, journal
Medical Image Classification Using Transfer Learning and Chaos Game Optimization on the Internet of Medical Things
Dec 12, 2023The Internet of Medical Things (IoMT) has dramatically benefited medical professionals that patients and physicians can access from all regions. Although the automatic detection and prediction of diseases such as melanoma and leukemia is still being researched and studied in IoMT, existing approaches are not able to achieve a high degree of efficiency. Thus, with a new approach that provides better results, patients would access the adequate treatments earlier and the death rate would be reduced. Therefore, this paper introduces an IoMT proposal for medical images classification that may be used anywhere, i.e. it is an ubiquitous approach. It was design in two stages: first, we employ a Transfer Learning (TL)-based method for feature extraction, which is carried out using MobileNetV3; second, we use the Chaos Game Optimization (CGO) for feature selection, with the aim of excluding unnecessary features and improving the performance, which is key in IoMT. Our methodology was evaluated using ISIC-2016, PH2, and Blood-Cell datasets. The experimental results indicated that the proposed approach obtained an accuracy of 88.39% on ISIC-2016, 97.52% on PH2, and 88.79% on Blood-cell. Moreover, our approach had successful performances for the metrics employed compared to other existing methods.
* 22 pages, 12 figures, journal
Multi-criteria recommendation systems to foster online grocery
Dec 12, 2023With the exponential increase in information, it has become imperative to design mechanisms that allow users to access what matters to them as quickly as possible. The recommendation system ($RS$) with information technology development is the solution, it is an intelligent system. Various types of data can be collected on items of interest to users and presented as recommendations. $RS$ also play a very important role in e-commerce. The purpose of recommending a product is to designate the most appropriate designation for a specific product. The major challenges when recommending products are insufficient information about the products and the categories to which they belong. In this paper, we transform the product data using two methods of document representation: bag-of-words (BOW) and the neural network-based document combination known as vector-based (Doc2Vec). We propose three-criteria recommendation systems (product, package, and health) for each document representation method to foster online grocery, which depends on product characteristics such as (composition, packaging, nutrition table, allergen, etc.). For our evaluation, we conducted a user and expert survey. Finally, we have compared the performance of these three criteria for each document representation method, discovering that the neural network-based (Doc2Vec) performs better and completely alters the results.
* 30 pages, 8 images, journal
QSMVM: QoS-aware and social-aware multimetric routing protocol for video-streaming services over MANETs
Dec 12, 2023
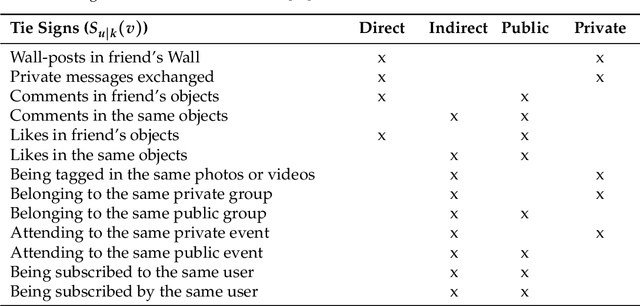
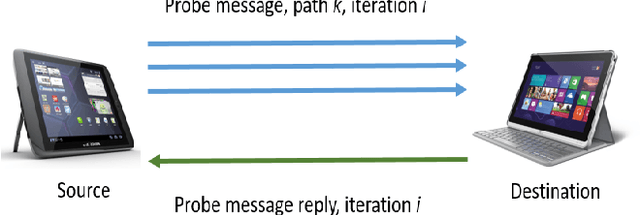
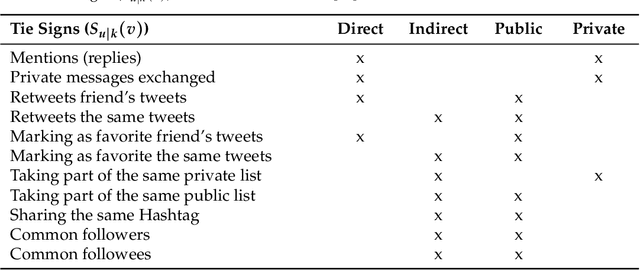
A mobile ad hoc network (MANET) is a set of autonomous mobile devices connected by wireless links in a distributed manner and without a fixed infrastructure. Real-time multimedia services, such as video-streaming over MANETs, offers very promising applications, e.g. two members of a group of tourists who want to share a video transmitted through the MANET they form; a video-streaming service deployed over a MANET where users watch a film; among other examples. On the other hand, social web technologies, where people actively interact online with others through social networks, are leading to a socialization of networks. Information of interaction among users is being used to provide socially-enhanced software. To achieve this, we need to know the strength of the relationship between a given user and each user they interact with. This strength of the relationship can be measured through a concept called tie strength (TS), first introduced by Mark Granovetter in 1973. In this article, we modify our previous proposal named multipath multimedia dynamic source routing (MMDSR) protocol to include a social metric TS in the decisions taken by the forwarding algorithm. We find a trade-off between the quality of service (QoS) and the trust level between users who form the forwarding path in the MANET. Our goal is to increase the trust metric while the QoS is not affected significantly.
Classification of retail products: From probabilistic ranking to neural networks
Dec 12, 2023Food retailing is now on an accelerated path to a success penetration into the digital market by new ways of value creation at all stages of the consumer decision process. One of the most important imperatives in this path is the availability of quality data to feed all the process in digital transformation. But the quality of data is not so obvious if we consider the variety of products and suppliers in the grocery market. Within this context of digital transformation of grocery industry, \textit{Midiadia} is Spanish data provider company that works on converting data from the retailers' products into knowledge with attributes and insights from the product labels, that is, maintaining quality data in a dynamic market with a high dispersion of products. Currently, they manually categorize products (groceries) according to the information extracted directly (text processing) from the product labelling and packaging. This paper introduces a solution to automatically categorize the constantly changing product catalogue into a 3-level food taxonomy. Our proposal studies three different approaches: a score-based ranking method, traditional machine learning algorithms, and deep neural networks. Thus, we provide four different classifiers that support a more efficient and less error-prone maintenance of groceries catalogues, the main asset of the company. Finally, we have compared the performance of these three alternatives, concluding that traditional machine learning algorithms perform better, but closely followed by the score-based approach.
* 17 pages, 8 figures, journal
Ensemble Federated Learning: an approach for collaborative pneumonia diagnosis
Dec 12, 2023Federated learning is a very convenient approach for scenarios where (i) the exchange of data implies privacy concerns and/or (ii) a quick reaction is needed. In smart healthcare systems, both aspects are usually required. In this paper, we work on the first scenario, where preserving privacy is key and, consequently, building a unique and massive medical image data set by fusing different data sets from different medical institutions or research centers (computation nodes) is not an option. We propose an ensemble federated learning (EFL) approach that is based on the following characteristics: First, each computation node works with a different data set (but of the same type). They work locally and apply an ensemble approach combining eight well-known CNN models (densenet169, mobilenetv2, xception, inceptionv3, vgg16, resnet50, densenet121, and resnet152v2) on Chest X-ray images. Second, the best two local models are used to create a local ensemble model that is shared with a central node. Third, the ensemble models are aggregated to obtain a global model, which is shared with the computation nodes to continue with a new iteration. This procedure continues until there are no changes in the best local models. We have performed different experiments to compare our approach with centralized ones (with or without an ensemble approach)\color{black}. The results conclude that our proposal outperforms these ones in Chest X-ray images (achieving an accuracy of 96.63\%) and offers very competitive results compared to other proposals in the literature.
* 15 pages, 9 figures, journal
Anti-Sexism Alert System: Identification of Sexist Comments on Social Media Using AI Techniques
Nov 28, 2023Social relationships in the digital sphere are becoming more usual and frequent, and they constitute a very important aspect for all of us. {Violent interactions in this sphere are very frequent, and have serious effects on the victims}. Within this global scenario, there is one kind of digital violence that is becoming really worrying: sexism against women. Sexist comments that are publicly posted in social media (newspaper comments, social networks, etc.), usually obtain a lot of attention and become viral, with consequent damage to the persons involved. In this paper, we introduce an anti-sexism alert system, based on natural language processing (NLP) and artificial intelligence (AI), that analyzes any public post, and decides if it could be considered a sexist comment or not. Additionally, this system also works on analyzing all the public comments linked to any multimedia content (piece of news, video, tweet, etc.) and decides, using a color-based system similar to traffic lights, if there is sexism in the global set of posts. We have created a labeled data set in Spanish, since the majority of studies focus on English, to train our system, which offers a very good performance after the validation experiments.