 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolution Is All You Need: Phylogenetic Augmentation for Contrastive Learning
Dec 25, 2020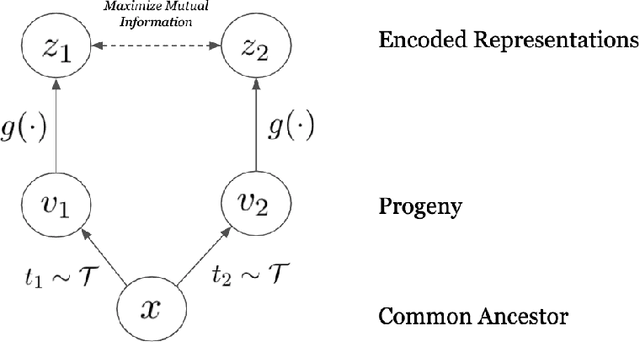
Self-supervised representation learning of biological sequence embeddings alleviates computational resource constraints on downstream tasks while circumventing expensive experimental label acquisition. However, existing methods mostly borrow directly from large language models designed for NLP, rather than with bioinformatics philosophies in mind. Recently, contrastive mutual information maximization methods have achieved state-of-the-art representations for ImageNet. In this perspective piece, we discuss how viewing evolution as natural sequence augmentation and maximizing information across phylogenetic "noisy channels" is a biologically and theoretically desirable objective for pretraining encoders. We first provide a review of current contrastive learning literature, then provide an illustrative example where we show that contrastive learning using evolutionary augmentation can be used as a representation learning objective which maximizes the mutual information between biological sequences and their conserved function, and finally outline rationale for this approach.
Hurtful Words: Quantifying Biases in Clinical Contextual Word Embeddings
Mar 11, 2020
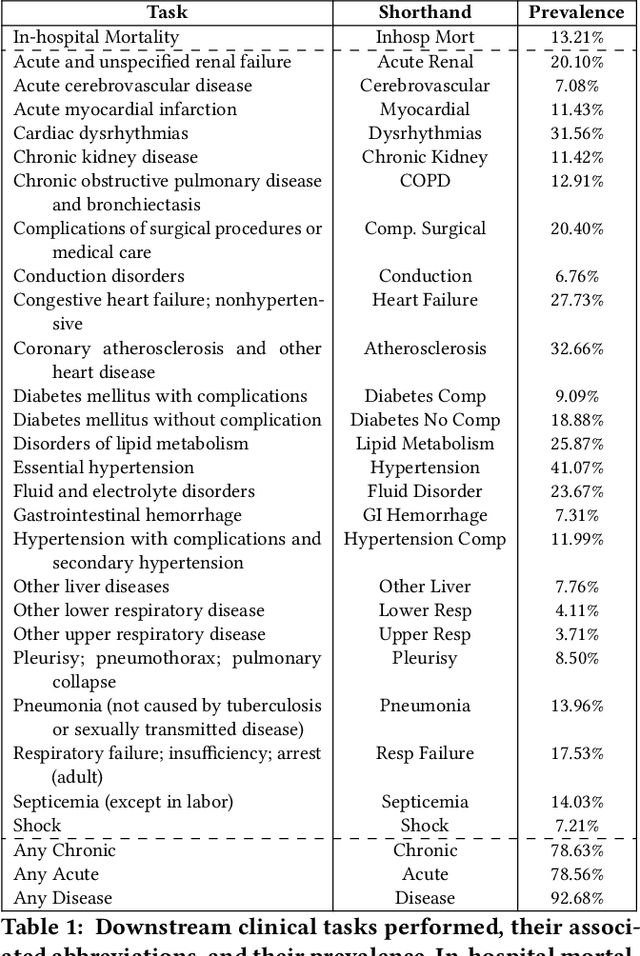


In this work, we examine the extent to which embeddings may encode marginalized populations differently, and how this may lead to a perpetuation of biases and worsened performance on clinical tasks. We pretrain deep embedding models (BERT) on medical notes from the MIMIC-III hospital dataset, and quantify potential disparities using two approaches. First, we identify dangerous latent relationships that are captured by the contextual word embeddings using a fill-in-the-blank method with text from real clinical notes and a log probability bias score quantification. Second, we evaluate performance gaps across different definitions of fairness on over 50 downstream clinical prediction tasks that include detection of acute and chronic conditions. We find that classifiers trained from BERT representations exhibit statistically significant differences in performance, often favoring the majority group with regards to gender, language, ethnicity, and insurance status. Finally, we explore shortcomings of using adversarial debiasing to obfuscate subgroup information in contextual word embeddings, and recommend best practices for such deep embedding models in clinical settings.
The Cells Out of Sample dataset and benchmarks for measuring out-of-sample generalization of image classifiers
Jun 17, 2019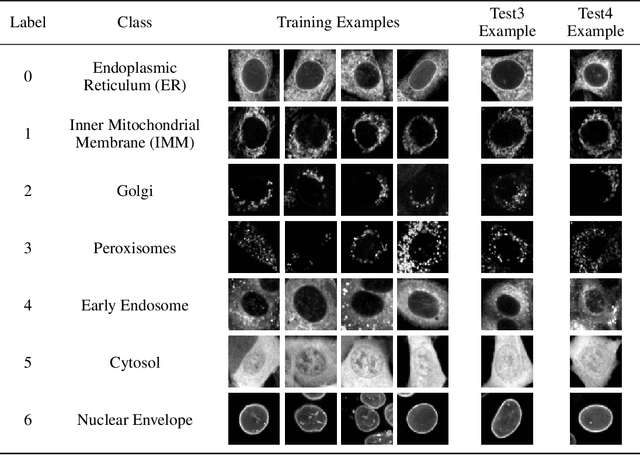

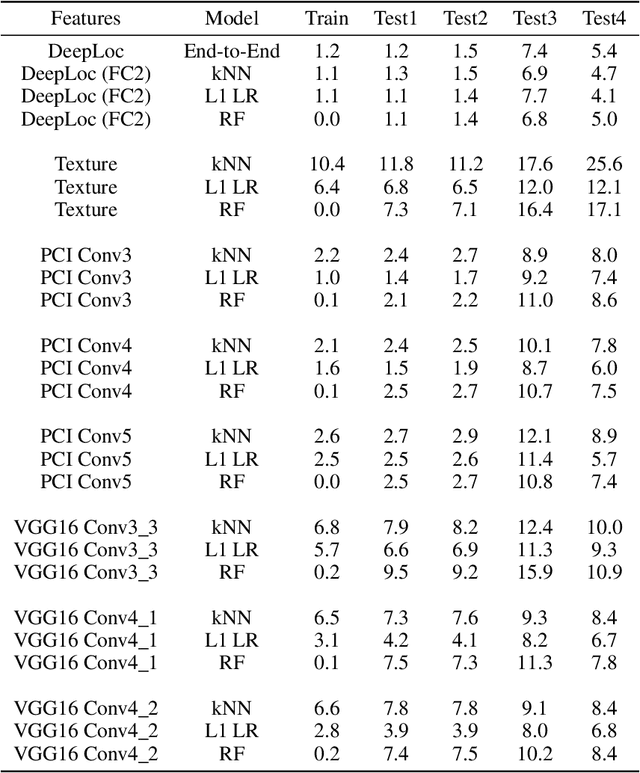
Understanding if classifiers generalize to out-of-sample datasets is a central problem in machine learning. Microscopy images provide a standardized way to measure the generalization capacity of image classifiers, as we can image the same classes of objects under increasingly divergent, but controlled factors of variation. We created a public dataset of 132,209 images of mouse cells, COOS-7 (Cells Out Of Sample 7-Class). COOS-7 provides a classification setting where four test datasets have increasing degrees of covariate shift: some images are random subsets of the training data, while others are from experiments reproduced months later and imaged by different instruments. We benchmarked a range of classification models using different representations, including transferred neural network features, end-to-end classification with a supervised deep CNN, and features from a self-supervised CNN. While most classifiers perform well on test datasets similar to the training dataset, all classifiers failed to generalize their performance to datasets with greater covariate shifts. These baselines highlight the challenges of covariate shifts in image data, and establish metrics for improving the generalization capacity of image classifiers.