 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Transformers and Beyond: Large Language Models for the Genome
Nov 13, 2023In the rapidly evolving landscape of genomics, deep learning has emerged as a useful tool for tackling complex computational challenges. This review focuses on the transformative role of Large Language Models (LLMs), which are mostly based on the transformer architecture, in genomics. Building on the foundation of traditional convolutional neural networks and recurrent neural networks, we explore both the strengths and limitations of transformers and other LLMs for genomics. Additionally, we contemplate the future of genomic modeling beyond the transformer architecture based on current trends in research. The paper aims to serve as a guide for computational biologists and computer scientists interested in LLMs for genomic data. We hope the paper can also serve as an educational introduction and discussion for biologists to a fundamental shift in how we will be analyzing genomic data in the future.
Evolution Is All You Need: Phylogenetic Augmentation for Contrastive Learning
Dec 25, 2020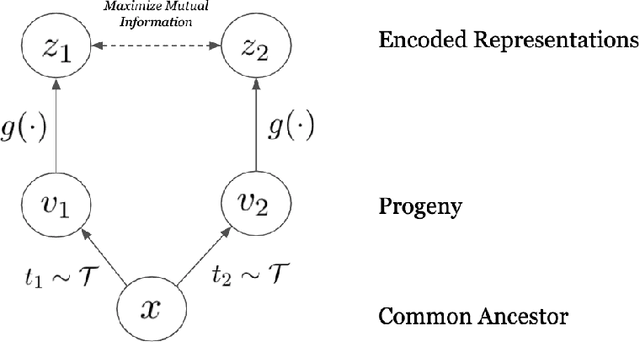
Self-supervised representation learning of biological sequence embeddings alleviates computational resource constraints on downstream tasks while circumventing expensive experimental label acquisition. However, existing methods mostly borrow directly from large language models designed for NLP, rather than with bioinformatics philosophies in mind. Recently, contrastive mutual information maximization methods have achieved state-of-the-art representations for ImageNet. In this perspective piece, we discuss how viewing evolution as natural sequence augmentation and maximizing information across phylogenetic "noisy channels" is a biologically and theoretically desirable objective for pretraining encoders. We first provide a review of current contrastive learning literature, then provide an illustrative example where we show that contrastive learning using evolutionary augmentation can be used as a representation learning objective which maximizes the mutual information between biological sequences and their conserved function, and finally outline rationale for this approach.