 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCytoImageNet: A large-scale pretraining dataset for bioimage transfer learning
Nov 24, 2021
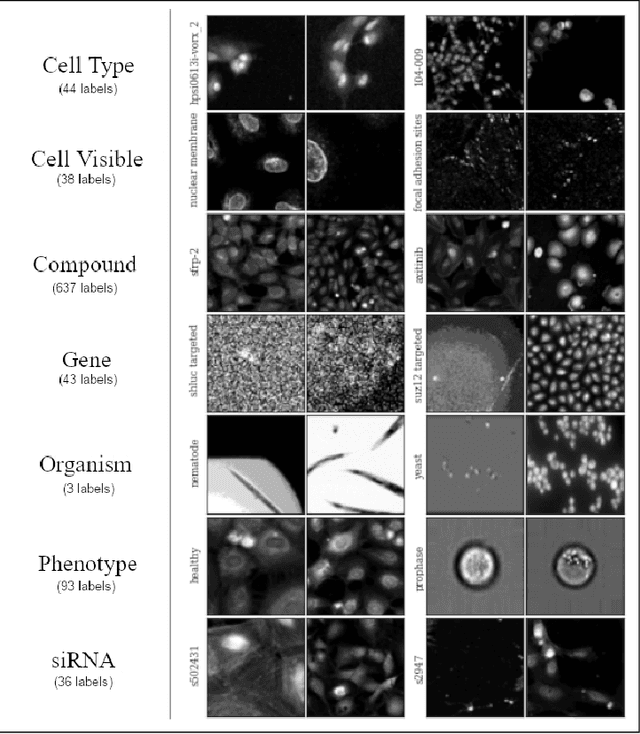
Motivation: In recent years, image-based biological assays have steadily become high-throughput, sparking a need for fast automated methods to extract biologically-meaningful information from hundreds of thousands of images. Taking inspiration from the success of ImageNet, we curate CytoImageNet, a large-scale dataset of openly-sourced and weakly-labeled microscopy images (890K images, 894 classes). Pretraining on CytoImageNet yields features that are competitive to ImageNet features on downstream microscopy classification tasks. We show evidence that CytoImageNet features capture information not available in ImageNet-trained features. The dataset is made available at https://www.kaggle.com/stanleyhua/cytoimagenet.
Random Embeddings and Linear Regression can Predict Protein Function
Apr 25, 2021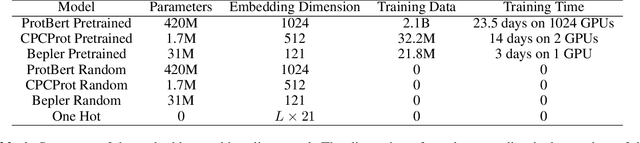



Large self-supervised models pretrained on millions of protein sequences have recently gained popularity in generating embeddings of protein sequences for protein function prediction. However, the absence of random baselines makes it difficult to conclude whether pretraining has learned useful information for protein function prediction. Here we show that one-hot encoding and random embeddings, both of which do not require any pretraining, are strong baselines for protein function prediction across 14 diverse sequence-to-function tasks.
W-Cell-Net: Multi-frame Interpolation of Cellular Microscopy Videos
May 14, 2020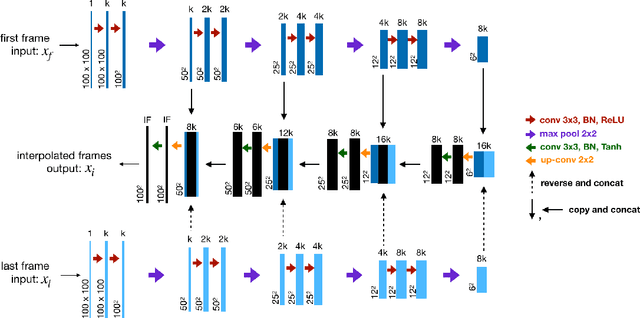
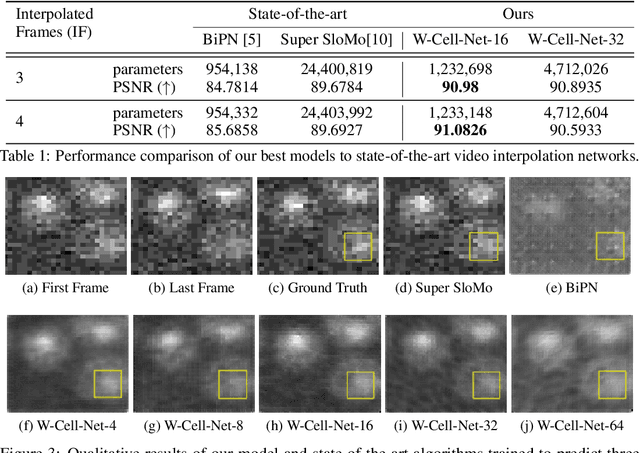
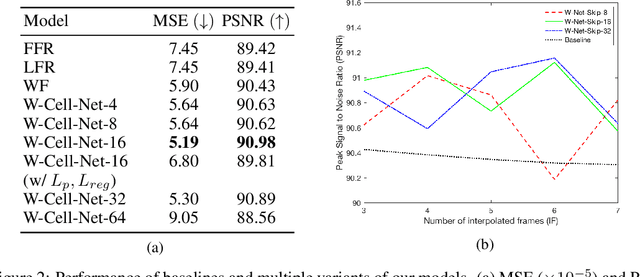
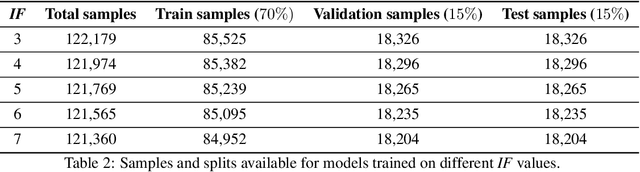
Deep Neural Networks are increasingly used in video frame interpolation tasks such as frame rate changes as well as generating fake face videos. Our project aims to apply recent advances in Deep video interpolation to increase the temporal resolution of fluorescent microscopy time-lapse movies. To our knowledge, there is no previous work that uses Convolutional Neural Networks (CNN) to generate frames between two consecutive microscopy images. We propose a fully convolutional autoencoder network that takes as input two images and generates upto seven intermediate images. Our architecture has two encoders each with a skip connection to a single decoder. We evaluate the performance of several variants of our model that differ in network architecture and loss function. Our best model out-performs state of the art video frame interpolation algorithms. We also show qualitative and quantitative comparisons with state-of-the-art video frame interpolation algorithms. We believe deep video interpolation represents a new approach to improve the time-resolution of fluorescent microscopy.
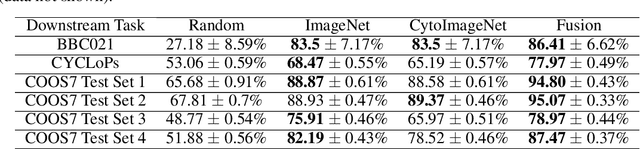
The Cells Out of Sample dataset and benchmarks for measuring out-of-sample generalization of image classifiers
Jun 17, 2019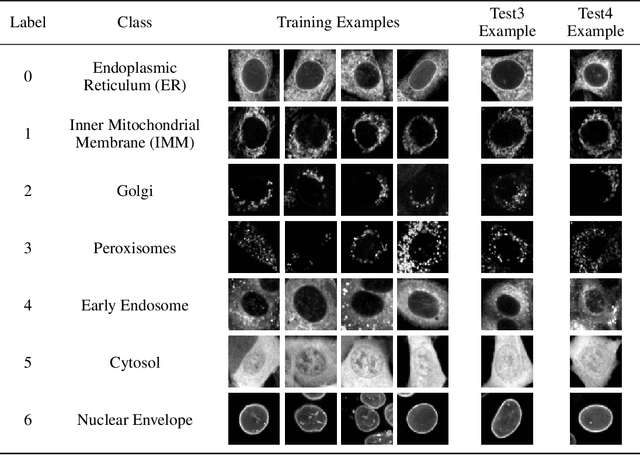

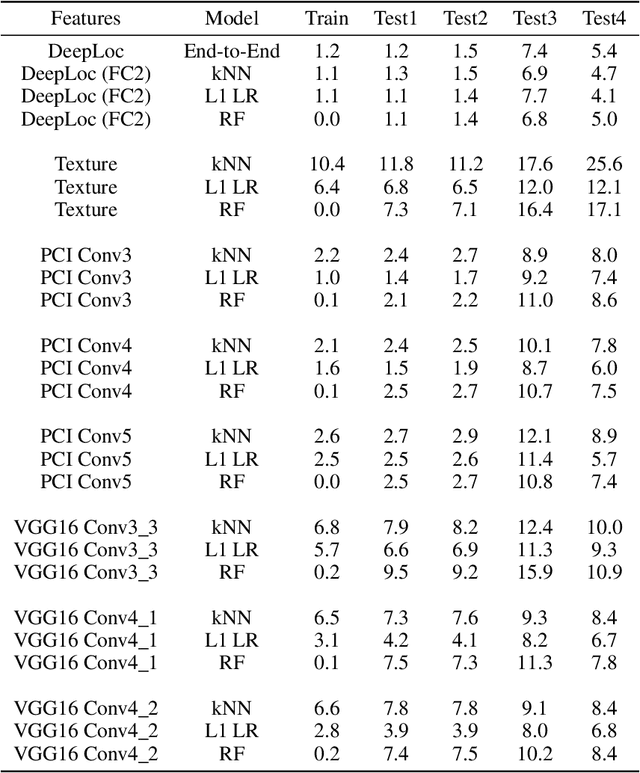
Understanding if classifiers generalize to out-of-sample datasets is a central problem in machine learning. Microscopy images provide a standardized way to measure the generalization capacity of image classifiers, as we can image the same classes of objects under increasingly divergent, but controlled factors of variation. We created a public dataset of 132,209 images of mouse cells, COOS-7 (Cells Out Of Sample 7-Class). COOS-7 provides a classification setting where four test datasets have increasing degrees of covariate shift: some images are random subsets of the training data, while others are from experiments reproduced months later and imaged by different instruments. We benchmarked a range of classification models using different representations, including transferred neural network features, end-to-end classification with a supervised deep CNN, and features from a self-supervised CNN. While most classifiers perform well on test datasets similar to the training dataset, all classifiers failed to generalize their performance to datasets with greater covariate shifts. These baselines highlight the challenges of covariate shifts in image data, and establish metrics for improving the generalization capacity of image classifiers.