Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCytoImageNet: A large-scale pretraining dataset for bioimage transfer learning
Paper and Code

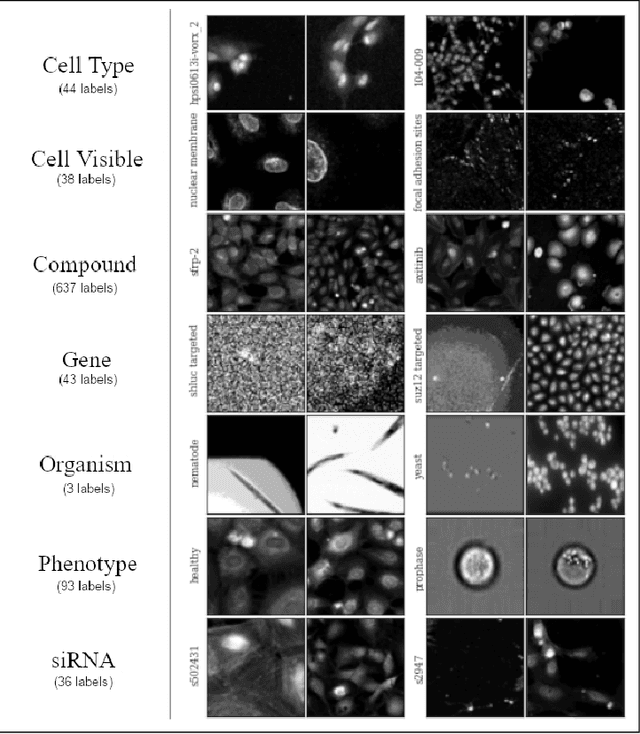
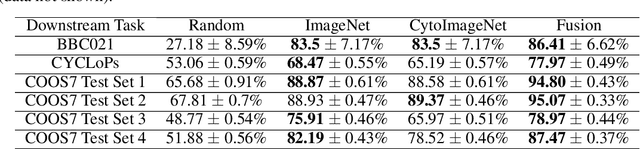
Motivation: In recent years, image-based biological assays have steadily become high-throughput, sparking a need for fast automated methods to extract biologically-meaningful information from hundreds of thousands of images. Taking inspiration from the success of ImageNet, we curate CytoImageNet, a large-scale dataset of openly-sourced and weakly-labeled microscopy images (890K images, 894 classes). Pretraining on CytoImageNet yields features that are competitive to ImageNet features on downstream microscopy classification tasks. We show evidence that CytoImageNet features capture information not available in ImageNet-trained features. The dataset is made available at https://www.kaggle.com/stanleyhua/cytoimagenet.
* Accepted paper at NeurIPS 2021 Learning Meaningful Representations
for Life (LMRL) Workshop
View paper on