Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Embeddings and Linear Regression can Predict Protein Function
Paper and Code
Apr 25, 2021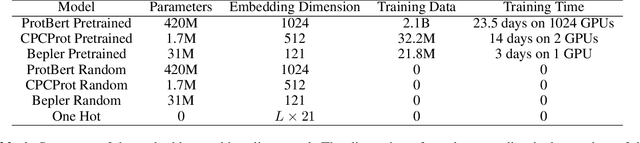



Large self-supervised models pretrained on millions of protein sequences have recently gained popularity in generating embeddings of protein sequences for protein function prediction. However, the absence of random baselines makes it difficult to conclude whether pretraining has learned useful information for protein function prediction. Here we show that one-hot encoding and random embeddings, both of which do not require any pretraining, are strong baselines for protein function prediction across 14 diverse sequence-to-function tasks.
View paper on