 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentForensics: Towards lighter deepfake detection in the StyleGAN latent space
Mar 30, 2023The classification of forged videos has been a challenge for the past few years. Deepfake classifiers can now reliably predict whether or not video frames have been tampered with. However, their performance is tied to both the dataset used for training and the analyst's computational power. We propose a deepfake classification method that operates in the latent space of a state-of-the-art generative adversarial network (GAN) trained on high-quality face images. The proposed method leverages the structure of the latent space of StyleGAN to learn a lightweight classification model. Experimental results on a standard dataset reveal that the proposed approach outperforms other state-of-the-art deepfake classification methods. To the best of our knowledge, this is the first study showing the interest of the latent space of StyleGAN for deepfake classification. Combined with other recent studies on the interpretation and manipulation of this latent space, we believe that the proposed approach can help in developing robust deepfake classification methods based on interpretable high-level properties of face images.
TwistSLAM++: Fusing multiple modalities for accurate dynamic semantic SLAM
Sep 16, 2022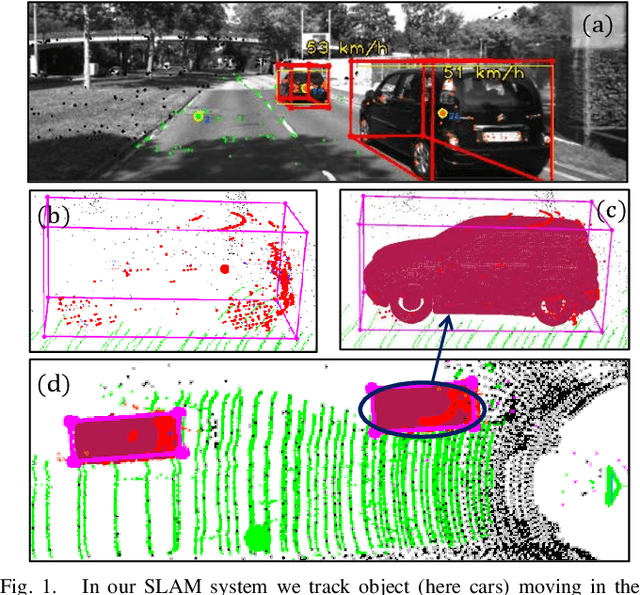
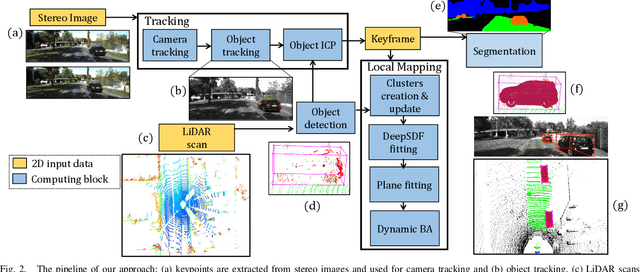
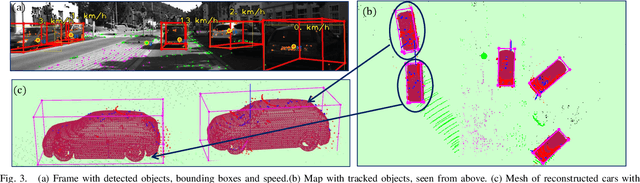

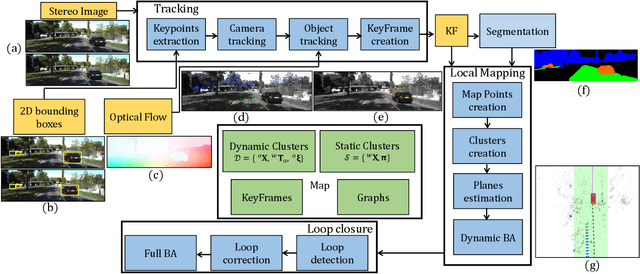
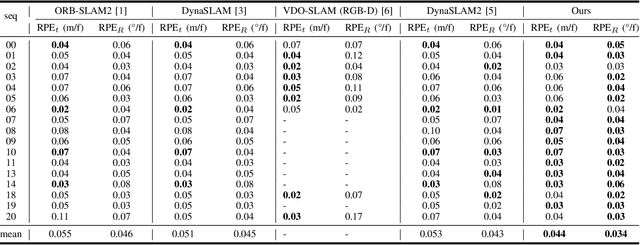
Most classical SLAM systems rely on the static scene assumption, which limits their applicability in real world scenarios. Recent SLAM frameworks have been proposed to simultaneously track the camera and moving objects. However they are often unable to estimate the canonical pose of the objects and exhibit a low object tracking accuracy. To solve this problem we propose TwistSLAM++, a semantic, dynamic, SLAM system that fuses stereo images and LiDAR information. Using semantic information, we track potentially moving objects and associate them to 3D object detections in LiDAR scans to obtain their pose and size. Then, we perform registration on consecutive object scans to refine object pose estimation. Finally, object scans are used to estimate the shape of the object and constrain map points to lie on the estimated surface within the BA. We show on classical benchmarks that this fusion approach based on multimodal information improves the accuracy of object tracking.
TwistSLAM: Constrained SLAM in Dynamic Environment
Feb 24, 2022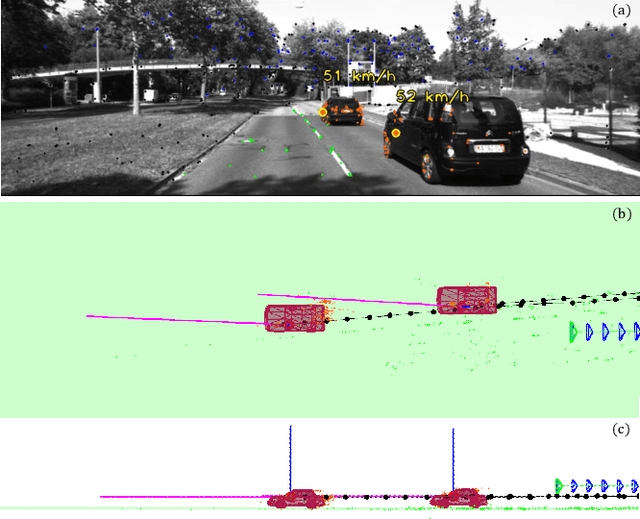
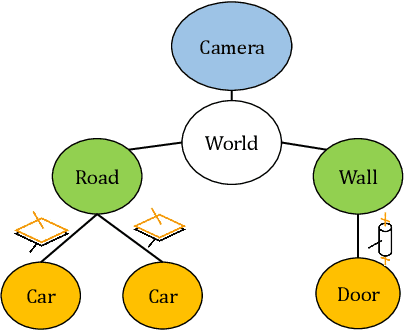
Moving objects are present in most scenes of our life. However they can be very problematic for classical SLAM algorithms that assume the scene to be rigid. This assumption limits the applicability of those algorithms as they are unable to accurately estimate the camera pose and world structure in many scenarios. Some SLAM systems have been proposed to detect and mask out dynamic objects, making the static scene assumption valid. However this information can allow the system to track objects within the scene, while tracking the camera, which can be crucial for some applications. In this paper we present TwistSLAM a semantic, dynamic, stereo SLAM system that can track dynamic objects in the scene. Our algorithm creates clusters of points according to their semantic class. It uses the static parts of the environment to robustly localize the camera and tracks the remaining objects. We propose a new formulation for the tracking and the bundle adjustment to take in account the characteristics of mechanical joints between clusters to constrain and improve their pose estimation. We evaluate our approach on several sequences from a public dataset and show that we improve camera and object tracking compared to state of the art.
S3LAM: Structured Scene SLAM
Sep 15, 2021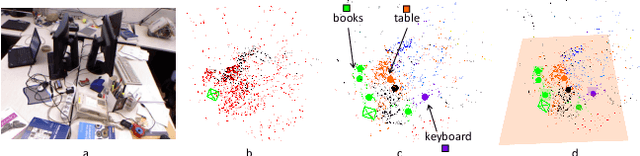
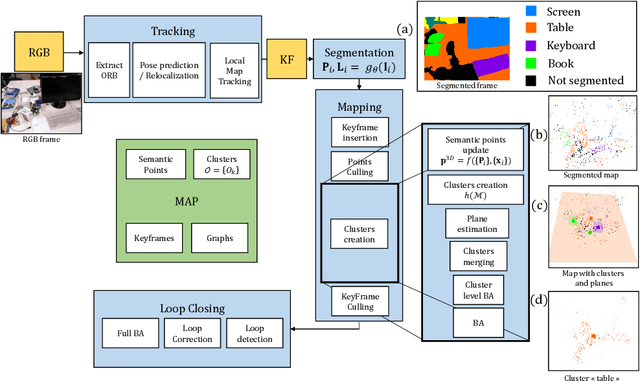
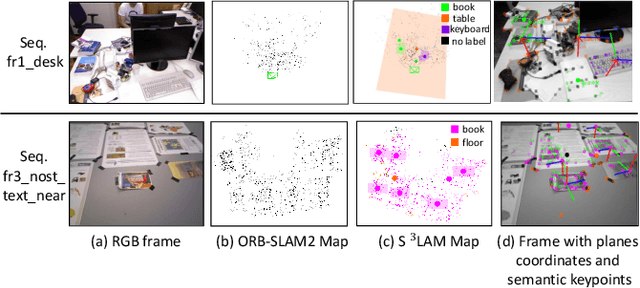
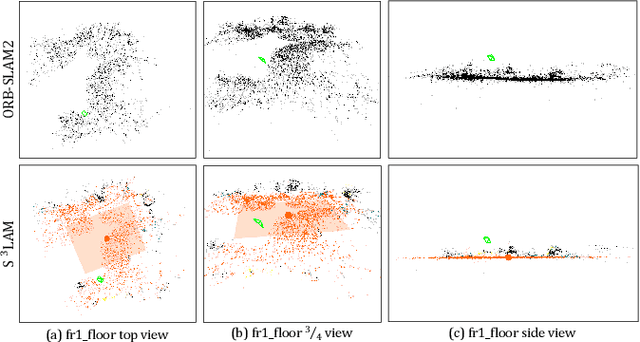
We propose a new general SLAM system that uses the semantic segmentation of objects and structures in the scene. Semantic information is relevant as it contains high level information which may make SLAM more accurate and robust. Our contribution is threefold: i) A new SLAM system based on ORB-SLAM2 that creates a semantic map made of clusters of points corresponding to objects instances and structures in the scene. ii) A modification of the classical Bundle Adjustment formulation to constrain each cluster using geometrical priors, which improves both camera localization and reconstruction and enables a better understanding of the scene. iii) A new Bundle Adjustment formulation at the level of clusters to improve the convergence of classical Bundle Adjustment. We evaluate our approach on several sequences from a public dataset and show that, with respect to ORB-SLAM2 it improves camera pose estimation.
YOLOff: You Only Learn Offsets for robust 6DoF object pose estimation
Feb 25, 2020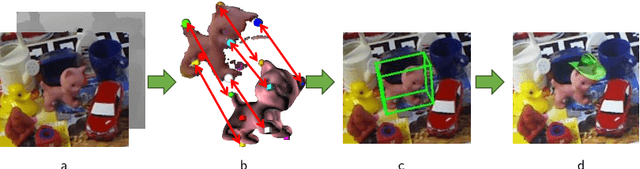

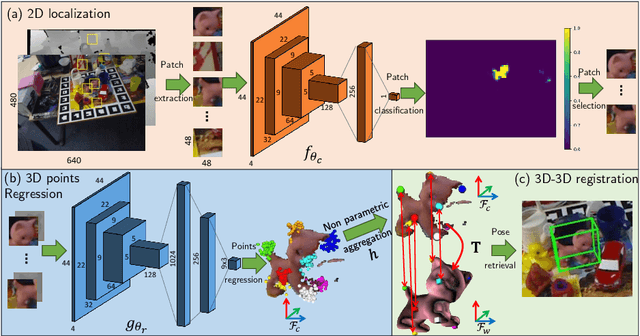

Estimating the 3D translation and orientation of an object is a challenging task that can be considered within augmented reality or robotic applications. In this paper, we propose a novel approach to perform 6 DoF object pose estimation from a single RGB-D image in cluttered scenes. We adopt an hybrid pipeline in two stages: data-driven and geometric respectively. The first data-driven step consists of a classification CNN to estimate the object 2D location in the image from local patches, followed by a regression CNN trained to predict the 3D location of a set of keypoints in the camera coordinate system. We robustly perform local voting to recover the location of each keypoint in the camera coordinate system. To extract the pose information, the geometric step consists in aligning the 3D points in the camera coordinate system with the corresponding 3D points in world coordinate system by minimizing a registration error, thus computing the pose. Our experiments on the standard dataset LineMod show that our approach more robust and accurate than state-of-the-art methods.