 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentForensics: Towards lighter deepfake detection in the StyleGAN latent space
Mar 30, 2023



The classification of forged videos has been a challenge for the past few years. Deepfake classifiers can now reliably predict whether or not video frames have been tampered with. However, their performance is tied to both the dataset used for training and the analyst's computational power. We propose a deepfake classification method that operates in the latent space of a state-of-the-art generative adversarial network (GAN) trained on high-quality face images. The proposed method leverages the structure of the latent space of StyleGAN to learn a lightweight classification model. Experimental results on a standard dataset reveal that the proposed approach outperforms other state-of-the-art deepfake classification methods. To the best of our knowledge, this is the first study showing the interest of the latent space of StyleGAN for deepfake classification. Combined with other recent studies on the interpretation and manipulation of this latent space, we believe that the proposed approach can help in developing robust deepfake classification methods based on interpretable high-level properties of face images.
Learning Vision Transformer with Squeeze and Excitation for Facial Expression Recognition
Jul 16, 2021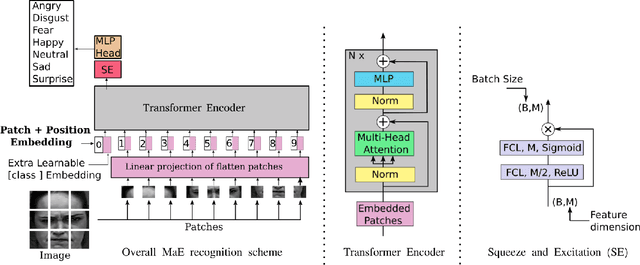

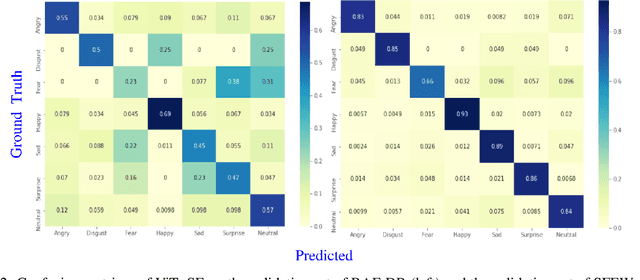

As various databases of facial expressions have been made accessible over the last few decades, the Facial Expression Recognition (FER) task has gotten a lot of interest. The multiple sources of the available databases raised several challenges for facial recognition task. These challenges are usually addressed by Convolution Neural Network (CNN) architectures. Different from CNN models, a Transformer model based on attention mechanism has been presented recently to address vision tasks. One of the major issue with Transformers is the need of a large data for training, while most FER databases are limited compared to other vision applications. Therefore, we propose in this paper to learn a vision Transformer jointly with a Squeeze and Excitation (SE) block for FER task. The proposed method is evaluated on different publicly available FER databases including CK+, JAFFE,RAF-DB and SFEW. Experiments demonstrate that our model outperforms state-of-the-art methods on CK+ and SFEW and achieves competitive results on JAFFE and RAF-DB.
Emo-CNN for Perceiving Stress from Audio Signals: A Brain Chemistry Approach
Jan 08, 2020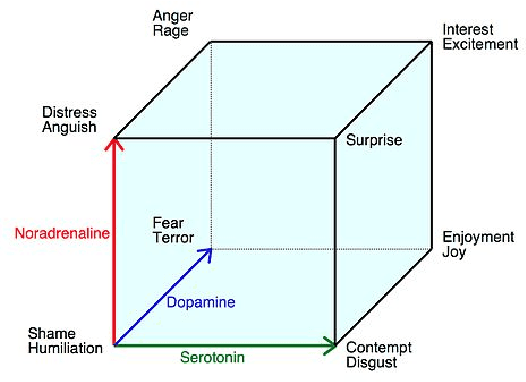
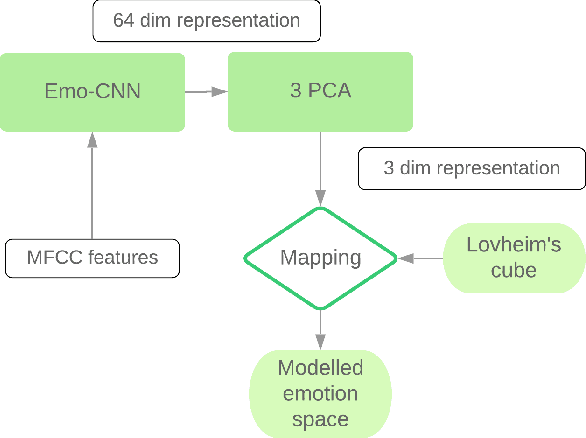

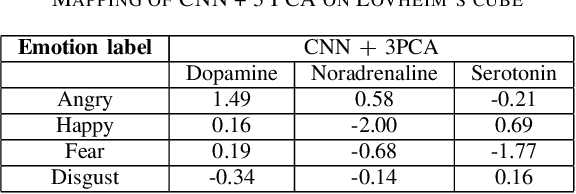
Emotion plays a key role in many applications like healthcare, to gather patients emotional behavior. There are certain emotions which are given more importance due to their effectiveness in understanding human feelings. In this paper, we propose an approach that models human stress from audio signals. The research challenge in speech emotion detection is defining the very meaning of stress and being able to categorize it in a precise manner. Supervised Machine Learning models, including state of the art Deep Learning classification methods, rely on the availability of clean and labelled data. One of the problems in affective computation and emotion detection is the limited amount of annotated data of stress. The existing labelled stress emotion datasets are highly subjective to the perception of the annotator. We address the first issue of feature selection by exploiting the use of traditional MFCC features in Convolutional Neural Network. Our experiments show that Emo-CNN consistently and significantly outperforms the popular existing methods over multiple datasets. It achieves 90.2% categorical accuracy on the Emo-DB dataset. To tackle the second and the more significant problem of subjectivity in stress labels, we use Lovheim's cube, which is a 3-dimensional projection of emotions. The cube aims at explaining the relationship between these neurotransmitters and the positions of emotions in 3D space. The learnt emotion representations from the Emo-CNN are mapped to the cube using three component PCA (Principal Component Analysis) which is then used to model human stress. This proposed approach not only circumvents the need for labelled stress data but also complies with the psychological theory of emotions given by Lovheim's cube. We believe that this work is the first step towards creating a connection between Artificial Intelligence and the chemistry of human emotions.