 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent-based jewellery item retrieval using the local region-based histograms
May 12, 2023



Jewellery item retrieval is regularly used to find what people want on online marketplaces using a sample query reference image. Considering recent developments, due to the simultaneous nature of various jewelry items, various jewelry goods' occlusion in images or visual streams, as well as shape deformation, content-based jewellery item retrieval (CBJIR) still has limitations whenever it pertains to visual searching in the actual world. This article proposed a content-based jewellery item retrieval method using the local region-based histograms in HSV color space. Using five local regions, our novel jewellery classification module extracts the specific feature vectors from the query image. The jewellery classification module is also applied to the jewellery database to extract feature vectors. Finally, the similarity score is matched between the database and query features vectors to retrieve the jewellery items from the database. The proposed method performance is tested on publicly available jewellery item retrieval datasets, i.e. ringFIR and Fashion Product Images dataset. The experimental results demonstrate the dominance of the proposed method over the baseline methods for retrieving desired jewellery products.
Methods and advancement of content-based fashion image retrieval: A Review
Mar 30, 2023



Content-based fashion image retrieval (CBFIR) has been widely used in our daily life for searching fashion images or items from online platforms. In e-commerce purchasing, the CBFIR system can retrieve fashion items or products with the same or comparable features when a consumer uploads a reference image, image with text, sketch or visual stream from their daily life. This lowers the CBFIR system reliance on text and allows for a more accurate and direct searching of the desired fashion product. Considering recent developments, CBFIR still has limits when it comes to visual searching in the real world due to the simultaneous availability of multiple fashion items, occlusion of fashion products, and shape deformation. This paper focuses on CBFIR methods with the guidance of images, images with text, sketches, and videos. Accordingly, we categorized CBFIR methods into four main categories, i.e., image-guided CBFIR (with the addition of attributes and styles), image and text-guided, sketch-guided, and video-guided CBFIR methods. The baseline methodologies have been thoroughly analyzed, and the most recent developments in CBFIR over the past six years (2017 to 2022) have been thoroughly examined. Finally, key issues are highlighted for CBFIR with promising directions for future research.
A Review on Methods and Applications in Multimodal Deep Learning
Feb 18, 2022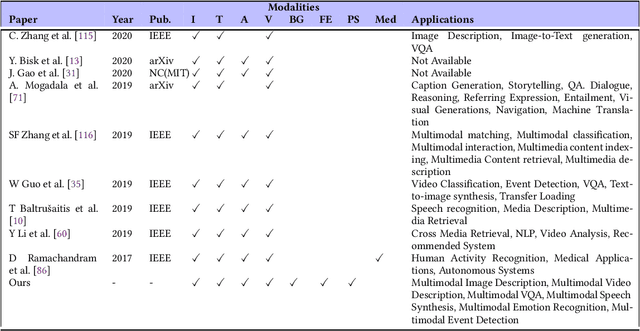
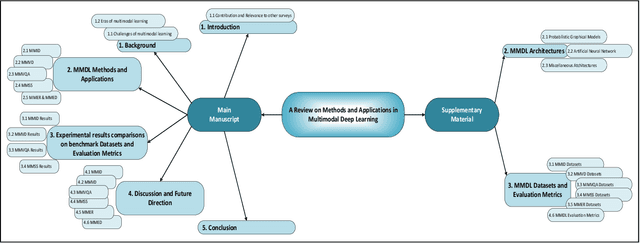
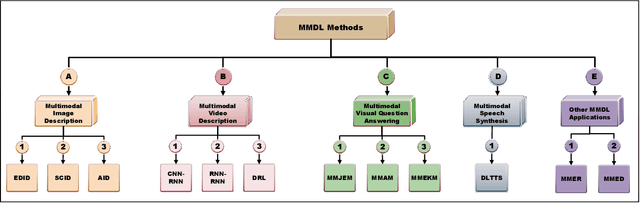
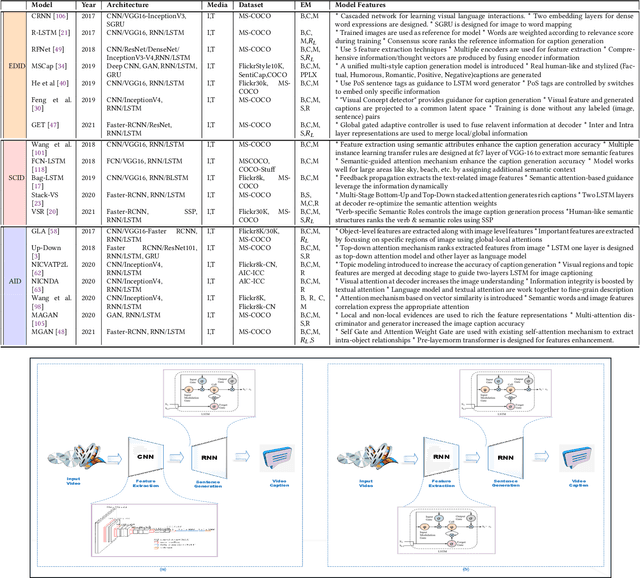
Deep Learning has implemented a wide range of applications and has become increasingly popular in recent years. The goal of multimodal deep learning (MMDL) is to create models that can process and link information using various modalities. Despite the extensive development made for unimodal learning, it still cannot cover all the aspects of human learning. Multimodal learning helps to understand and analyze better when various senses are engaged in the processing of information. This paper focuses on multiple types of modalities, i.e., image, video, text, audio, body gestures, facial expressions, and physiological signals. Detailed analysis of the baseline approaches and an in-depth study of recent advancements during the last five years (2017 to 2021) in multimodal deep learning applications has been provided. A fine-grained taxonomy of various multimodal deep learning methods is proposed, elaborating on different applications in more depth. Lastly, main issues are highlighted separately for each domain, along with their possible future research directions.
* 29 pages. arXiv admin note: substantial text overlap with arXiv:2105.11087
Recent Advances and Trends in Multimodal Deep Learning: A Review
May 24, 2021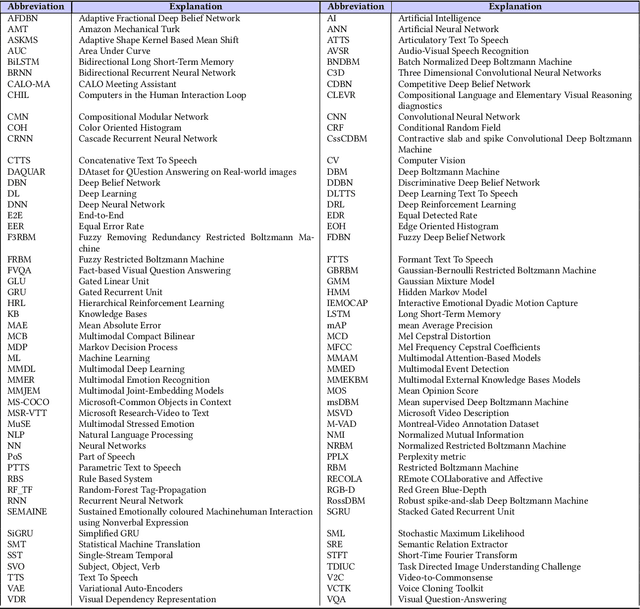
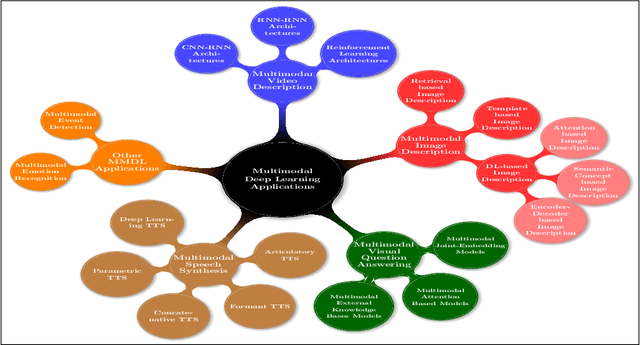

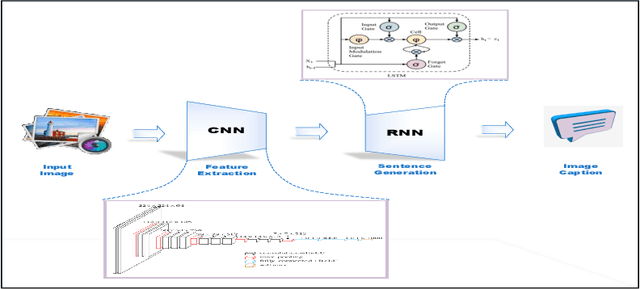
Deep Learning has implemented a wide range of applications and has become increasingly popular in recent years. The goal of multimodal deep learning is to create models that can process and link information using various modalities. Despite the extensive development made for unimodal learning, it still cannot cover all the aspects of human learning. Multimodal learning helps to understand and analyze better when various senses are engaged in the processing of information. This paper focuses on multiple types of modalities, i.e., image, video, text, audio, body gestures, facial expressions, and physiological signals. Detailed analysis of past and current baseline approaches and an in-depth study of recent advancements in multimodal deep learning applications has been provided. A fine-grained taxonomy of various multimodal deep learning applications is proposed, elaborating on different applications in more depth. Architectures and datasets used in these applications are also discussed, along with their evaluation metrics. Last, main issues are highlighted separately for each domain along with their possible future research directions.